 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeaching the Teachers: Boosting unsupervised domain adaptation in speech recognition by ensemble update
Apr 13, 2026Speech recognition systems often struggle with data domains that have not been included in the training. To address this, unsupervised domain adaptation has been explored with ensemble and multi-stage teacher-student training methods reducing the word error rate. Despite improvements, the error rate remains much higher than that achieved with supervised in-domain training. This work proposes a more efficient strategy by simultaneously updating the ensemble of teacher models along with the single student model eliminating the need for sequential models training. The joint update improves the word error rate of the student model, benefiting the progressively enhanced teacher models. Experiments are conducted with three labelled source datasets, namely AMI, WSJ, LS360, and one unlabeled target domain i.e. SwitchBoard. The results show that the proposed method improves the WER by 4.6% on the Switchboard eval00 test set, thus outperforming multi-stage and iterative training methods.
Towards Non-task-specific Distillation of BERT via Sentence Representation Approximation
Apr 07, 2020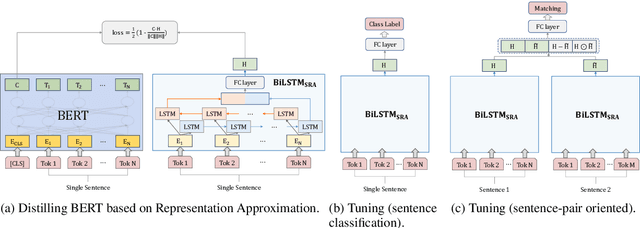
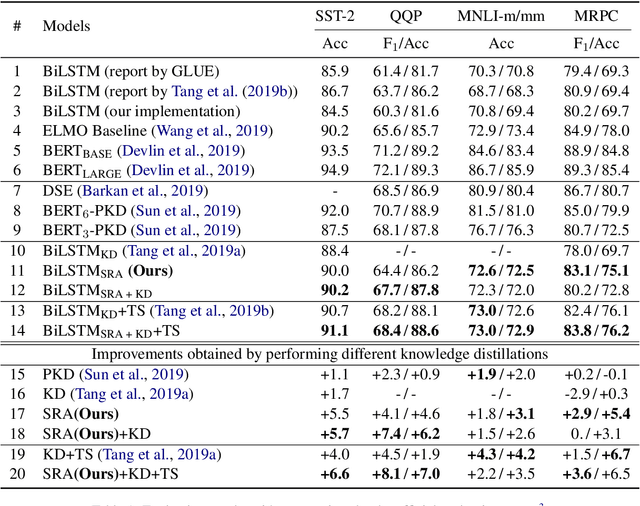
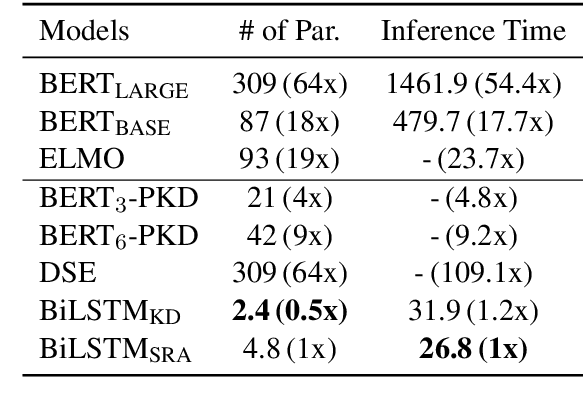
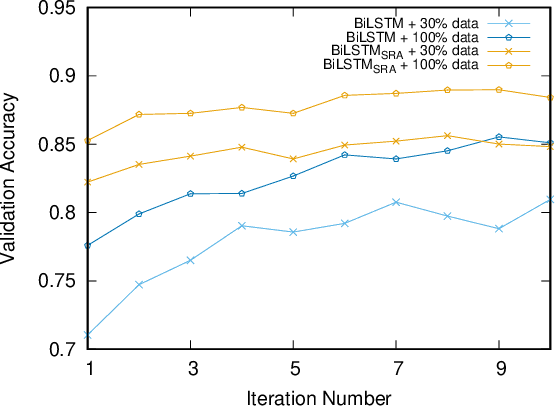
Recently, BERT has become an essential ingredient of various NLP deep models due to its effectiveness and universal-usability. However, the online deployment of BERT is often blocked by its large-scale parameters and high computational cost. There are plenty of studies showing that the knowledge distillation is efficient in transferring the knowledge from BERT into the model with a smaller size of parameters. Nevertheless, current BERT distillation approaches mainly focus on task-specified distillation, such methodologies lead to the loss of the general semantic knowledge of BERT for universal-usability. In this paper, we propose a sentence representation approximating oriented distillation framework that can distill the pre-trained BERT into a simple LSTM based model without specifying tasks. Consistent with BERT, our distilled model is able to perform transfer learning via fine-tuning to adapt to any sentence-level downstream task. Besides, our model can further cooperate with task-specific distillation procedures. The experimental results on multiple NLP tasks from the GLUE benchmark show that our approach outperforms other task-specific distillation methods or even much larger models, i.e., ELMO, with efficiency well-improved.
Guiding Variational Response Generator to Exploit Persona
Nov 06, 2019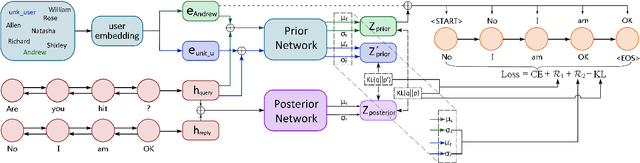
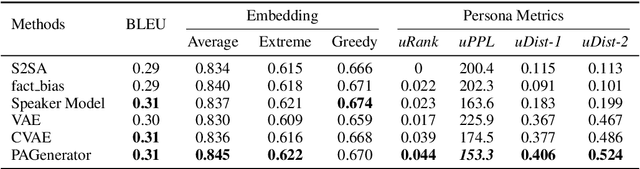
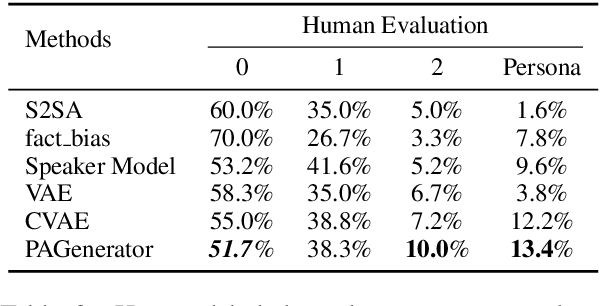

Leveraging persona information of users in Neural Response Generators (NRG) to perform personalized conversations has been considered as an attractive and important topic in the research of conversational agents over the past few years. Despite of the promising progresses achieved by recent studies in this field, persona information tends to be incorporated into neural networks in the form of user embeddings, with the expectation that the persona can be involved via the End-to-End learning. This paper proposes to adopt the personality-related characteristics of human conversations into variational response generators, by designing a specific conditional variational autoencoder based deep model with two new regularization terms employed to the loss function, so as to guide the optimization towards the direction of generating both persona-aware and relevant responses. Besides, to reasonably evaluate the performances of various persona modeling approaches, this paper further presents three direct persona-oriented metrics from different perspectives. The experimental results have shown that our proposed methodology can notably improve the performance of persona-aware response generation, and the metrics are reasonable to evaluate the results.
MemeFaceGenerator: Adversarial Synthesis of Chinese Meme-face from Natural Sentences
Aug 14, 2019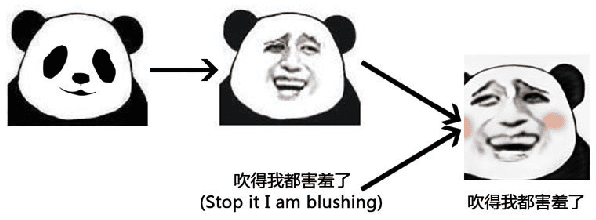
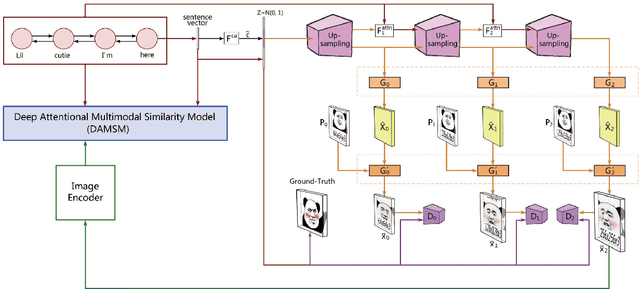
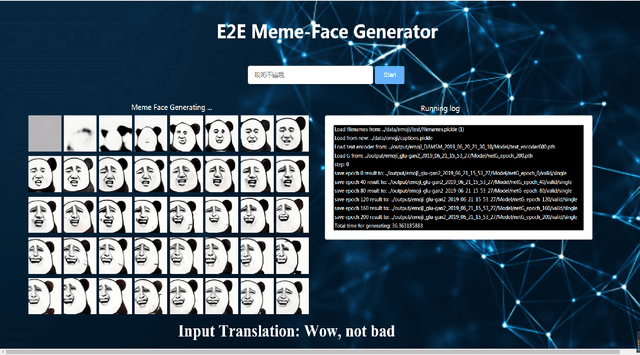

Chinese meme-face is a special kind of internet subculture widely spread in Chinese Social Community Networks. It usually consists of a template image modified by some amusing details and a text caption. In this paper, we present MemeFaceGenerator, a Generative Adversarial Network with the attention module and template information as supplementary signals, to automatically generate meme-faces from text inputs. We also develop a web service as system demonstration of meme-face synthesis. MemeFaceGenerator has been shown to be capable of generating high-quality meme-faces from random text inputs.