 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsynchronous Stochastic Approximation and Average-Reward Reinforcement Learning
Sep 05, 2024This paper studies asynchronous stochastic approximation (SA) algorithms and their application to reinforcement learning in semi-Markov decision processes (SMDPs) with an average-reward criterion. We first extend Borkar and Meyn's stability proof method to accommodate more general noise conditions, leading to broader convergence guarantees for asynchronous SA algorithms. Leveraging these results, we establish the convergence of an asynchronous SA analogue of Schweitzer's classical relative value iteration algorithm, RVI Q-learning, for finite-space, weakly communicating SMDPs. Furthermore, to fully utilize the SA results in this application, we introduce new monotonicity conditions for estimating the optimal reward rate in RVI Q-learning. These conditions substantially expand the previously considered algorithmic framework, and we address them with novel proof arguments in the stability and convergence analysis of RVI Q-learning.
On Convergence of Average-Reward Q-Learning in Weakly Communicating Markov Decision Processes
Aug 29, 2024This paper analyzes reinforcement learning (RL) algorithms for Markov decision processes (MDPs) under the average-reward criterion. We focus on Q-learning algorithms based on relative value iteration (RVI), which are model-free stochastic analogues of the classical RVI method for average-reward MDPs. These algorithms have low per-iteration complexity, making them well-suited for large state space problems. We extend the almost-sure convergence analysis of RVI Q-learning algorithms developed by Abounadi, Bertsekas, and Borkar (2001) from unichain to weakly communicating MDPs. This extension is important both practically and theoretically: weakly communicating MDPs cover a much broader range of applications compared to unichain MDPs, and their optimality equations have a richer solution structure (with multiple degrees of freedom), introducing additional complexity in proving algorithmic convergence. We also characterize the sets to which RVI Q-learning algorithms converge, showing that they are compact, connected, potentially nonconvex, and comprised of solutions to the average-reward optimality equation, with exactly one less degree of freedom than the general solution set of this equation. Furthermore, we extend our analysis to two RVI-based hierarchical average-reward RL algorithms using the options framework, proving their almost-sure convergence and characterizing their sets of convergence under the assumption that the underlying semi-Markov decision process is weakly communicating.
Reward Centering
May 16, 2024We show that discounted methods for solving continuing reinforcement learning problems can perform significantly better if they center their rewards by subtracting out the rewards' empirical average. The improvement is substantial at commonly used discount factors and increases further as the discount factor approaches one. In addition, we show that if a problem's rewards are shifted by a constant, then standard methods perform much worse, whereas methods with reward centering are unaffected. Estimating the average reward is straightforward in the on-policy setting; we propose a slightly more sophisticated method for the off-policy setting. Reward centering is a general idea, so we expect almost every reinforcement-learning algorithm to benefit by the addition of reward centering.
Distillation Matters: Empowering Sequential Recommenders to Match the Performance of Large Language Model
May 01, 2024



Owing to their powerful semantic reasoning capabilities, Large Language Models (LLMs) have been effectively utilized as recommenders, achieving impressive performance. However, the high inference latency of LLMs significantly restricts their practical deployment. To address this issue, this work investigates knowledge distillation from cumbersome LLM-based recommendation models to lightweight conventional sequential models. It encounters three challenges: 1) the teacher's knowledge may not always be reliable; 2) the capacity gap between the teacher and student makes it difficult for the student to assimilate the teacher's knowledge; 3) divergence in semantic space poses a challenge to distill the knowledge from embeddings. To tackle these challenges, this work proposes a novel distillation strategy, DLLM2Rec, specifically tailored for knowledge distillation from LLM-based recommendation models to conventional sequential models. DLLM2Rec comprises: 1) Importance-aware ranking distillation, which filters reliable and student-friendly knowledge by weighting instances according to teacher confidence and student-teacher consistency; 2) Collaborative embedding distillation integrates knowledge from teacher embeddings with collaborative signals mined from the data. Extensive experiments demonstrate the effectiveness of the proposed DLLM2Rec, boosting three typical sequential models with an average improvement of 47.97%, even enabling them to surpass LLM-based recommenders in some cases.
Light-weight Retinal Layer Segmentation with Global Reasoning
Apr 25, 2024



Automatic retinal layer segmentation with medical images, such as optical coherence tomography (OCT) images, serves as an important tool for diagnosing ophthalmic diseases. However, it is challenging to achieve accurate segmentation due to low contrast and blood flow noises presented in the images. In addition, the algorithm should be light-weight to be deployed for practical clinical applications. Therefore, it is desired to design a light-weight network with high performance for retinal layer segmentation. In this paper, we propose LightReSeg for retinal layer segmentation which can be applied to OCT images. Specifically, our approach follows an encoder-decoder structure, where the encoder part employs multi-scale feature extraction and a Transformer block for fully exploiting the semantic information of feature maps at all scales and making the features have better global reasoning capabilities, while the decoder part, we design a multi-scale asymmetric attention (MAA) module for preserving the semantic information at each encoder scale. The experiments show that our approach achieves a better segmentation performance compared to the current state-of-the-art method TransUnet with 105.7M parameters on both our collected dataset and two other public datasets, with only 3.3M parameters.
ELA: Efficient Local Attention for Deep Convolutional Neural Networks
Mar 02, 2024



The attention mechanism has gained significant recognition in the field of computer vision due to its ability to effectively enhance the performance of deep neural networks. However, existing methods often struggle to effectively utilize spatial information or, if they do, they come at the cost of reducing channel dimensions or increasing the complexity of neural networks. In order to address these limitations, this paper introduces an Efficient Local Attention (ELA) method that achieves substantial performance improvements with a simple structure. By analyzing the limitations of the Coordinate Attention method, we identify the lack of generalization ability in Batch Normalization, the adverse effects of dimension reduction on channel attention, and the complexity of attention generation process. To overcome these challenges, we propose the incorporation of 1D convolution and Group Normalization feature enhancement techniques. This approach enables accurate localization of regions of interest by efficiently encoding two 1D positional feature maps without the need for dimension reduction, while allowing for a lightweight implementation. We carefully design three hyperparameters in ELA, resulting in four different versions: ELA-T, ELA-B, ELA-S, and ELA-L, to cater to the specific requirements of different visual tasks such as image classification, object detection and sementic segmentation. ELA can be seamlessly integrated into deep CNN networks such as ResNet, MobileNet, and DeepLab. Extensive evaluations on the ImageNet, MSCOCO, and Pascal VOC datasets demonstrate the superiority of the proposed ELA module over current state-of-the-art methods in all three aforementioned visual tasks.
A Note on Stability in Asynchronous Stochastic Approximation without Communication Delays
Dec 22, 2023In this paper, we study asynchronous stochastic approximation algorithms without communication delays. Our main contribution is a stability proof for these algorithms that extends a method of Borkar and Meyn by accommodating more general noise conditions. We also derive convergence results from this stability result and discuss their application in important average-reward reinforcement learning problems.
Pearl: A Production-ready Reinforcement Learning Agent
Dec 06, 2023



Reinforcement Learning (RL) offers a versatile framework for achieving long-term goals. Its generality allows us to formalize a wide range of problems that real-world intelligent systems encounter, such as dealing with delayed rewards, handling partial observability, addressing the exploration and exploitation dilemma, utilizing offline data to improve online performance, and ensuring safety constraints are met. Despite considerable progress made by the RL research community in addressing these issues, existing open-source RL libraries tend to focus on a narrow portion of the RL solution pipeline, leaving other aspects largely unattended. This paper introduces Pearl, a Production-ready RL agent software package explicitly designed to embrace these challenges in a modular fashion. In addition to presenting preliminary benchmark results, this paper highlights Pearl's industry adoptions to demonstrate its readiness for production usage. Pearl is open sourced on Github at github.com/facebookresearch/pearl and its official website is located at pearlagent.github.io.
Survey on video anomaly detection in dynamic scenes with moving cameras
Aug 14, 2023The increasing popularity of compact and inexpensive cameras, e.g.~dash cameras, body cameras, and cameras equipped on robots, has sparked a growing interest in detecting anomalies within dynamic scenes recorded by moving cameras. However, existing reviews primarily concentrate on Video Anomaly Detection (VAD) methods assuming static cameras. The VAD literature with moving cameras remains fragmented, lacking comprehensive reviews to date. To address this gap, we endeavor to present the first comprehensive survey on Moving Camera Video Anomaly Detection (MC-VAD). We delve into the research papers related to MC-VAD, critically assessing their limitations and highlighting associated challenges. Our exploration encompasses three application domains: security, urban transportation, and marine environments, which in turn cover six specific tasks. We compile an extensive list of 25 publicly-available datasets spanning four distinct environments: underwater, water surface, ground, and aerial. We summarize the types of anomalies these datasets correspond to or contain, and present five main categories of approaches for detecting such anomalies. Lastly, we identify future research directions and discuss novel contributions that could advance the field of MC-VAD. With this survey, we aim to offer a valuable reference for researchers and practitioners striving to develop and advance state-of-the-art MC-VAD methods.
Attentive Multimodal Fusion for Optical and Scene Flow
Jul 28, 2023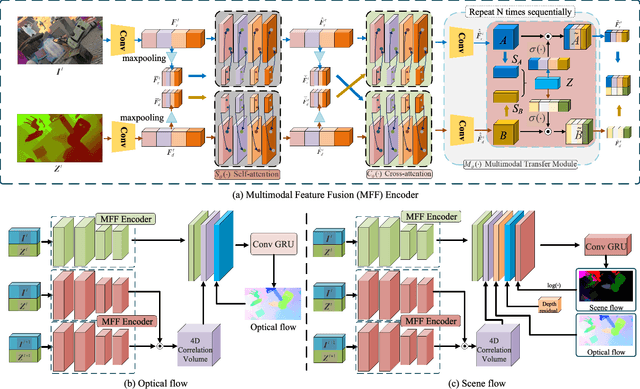

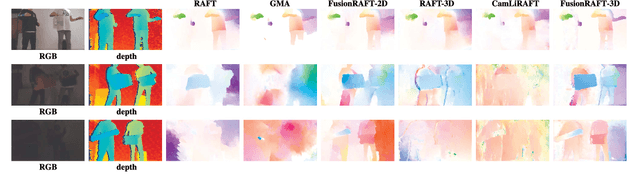
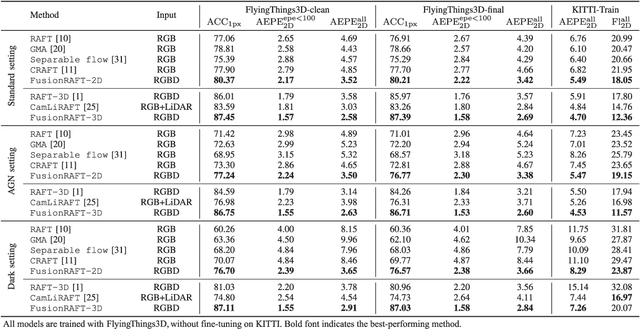
This paper presents an investigation into the estimation of optical and scene flow using RGBD information in scenarios where the RGB modality is affected by noise or captured in dark environments. Existing methods typically rely solely on RGB images or fuse the modalities at later stages, which can result in lower accuracy when the RGB information is unreliable. To address this issue, we propose a novel deep neural network approach named FusionRAFT, which enables early-stage information fusion between sensor modalities (RGB and depth). Our approach incorporates self- and cross-attention layers at different network levels to construct informative features that leverage the strengths of both modalities. Through comparative experiments, we demonstrate that our approach outperforms recent methods in terms of performance on the synthetic dataset Flyingthings3D, as well as the generalization on the real-world dataset KITTI. We illustrate that our approach exhibits improved robustness in the presence of noise and low-lighting conditions that affect the RGB images. We release the code, models and dataset at https://github.com/jiesico/FusionRAFT.