 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTiMem: Temporal-Hierarchical Memory Consolidation for Long-Horizon Conversational Agents
Jan 06, 2026Long-horizon conversational agents have to manage ever-growing interaction histories that quickly exceed the finite context windows of large language models (LLMs). Existing memory frameworks provide limited support for temporally structured information across hierarchical levels, often leading to fragmented memories and unstable long-horizon personalization. We present TiMem, a temporal--hierarchical memory framework that organizes conversations through a Temporal Memory Tree (TMT), enabling systematic memory consolidation from raw conversational observations to progressively abstracted persona representations. TiMem is characterized by three core properties: (1) temporal--hierarchical organization through TMT; (2) semantic-guided consolidation that enables memory integration across hierarchical levels without fine-tuning; and (3) complexity-aware memory recall that balances precision and efficiency across queries of varying complexity. Under a consistent evaluation setup, TiMem achieves state-of-the-art accuracy on both benchmarks, reaching 75.30% on LoCoMo and 76.88% on LongMemEval-S. It outperforms all evaluated baselines while reducing the recalled memory length by 52.20% on LoCoMo. Manifold analysis indicates clear persona separation on LoCoMo and reduced dispersion on LongMemEval-S. Overall, TiMem treats temporal continuity as a first-class organizing principle for long-horizon memory in conversational agents.
NVIDIA Nemotron Nano V2 VL
Nov 07, 2025We introduce Nemotron Nano V2 VL, the latest model of the Nemotron vision-language series designed for strong real-world document understanding, long video comprehension, and reasoning tasks. Nemotron Nano V2 VL delivers significant improvements over our previous model, Llama-3.1-Nemotron-Nano-VL-8B, across all vision and text domains through major enhancements in model architecture, datasets, and training recipes. Nemotron Nano V2 VL builds on Nemotron Nano V2, a hybrid Mamba-Transformer LLM, and innovative token reduction techniques to achieve higher inference throughput in long document and video scenarios. We are releasing model checkpoints in BF16, FP8, and FP4 formats and sharing large parts of our datasets, recipes and training code.
Towards Agentic Self-Learning LLMs in Search Environment
Oct 16, 2025



We study whether self-learning can scale LLM-based agents without relying on human-curated datasets or predefined rule-based rewards. Through controlled experiments in a search-agent setting, we identify two key determinants of scalable agent training: the source of reward signals and the scale of agent task data. We find that rewards from a Generative Reward Model (GRM) outperform rigid rule-based signals for open-domain learning, and that co-evolving the GRM with the policy further boosts performance. Increasing the volume of agent task data-even when synthetically generated-substantially enhances agentic capabilities. Building on these insights, we propose \textbf{Agentic Self-Learning} (ASL), a fully closed-loop, multi-role reinforcement learning framework that unifies task generation, policy execution, and evaluation within a shared tool environment and LLM backbone. ASL coordinates a Prompt Generator, a Policy Model, and a Generative Reward Model to form a virtuous cycle of harder task setting, sharper verification, and stronger solving. Empirically, ASL delivers steady, round-over-round gains, surpasses strong RLVR baselines (e.g., Search-R1) that plateau or degrade, and continues improving under zero-labeled-data conditions, indicating superior sample efficiency and robustness. We further show that GRM verification capacity is the main bottleneck: if frozen, it induces reward hacking and stalls progress; continual GRM training on the evolving data distribution mitigates this, and a small late-stage injection of real verification data raises the performance ceiling. This work establishes reward source and data scale as critical levers for open-domain agent learning and demonstrates the efficacy of multi-role co-evolution for scalable, self-improving agents. The data and code of this paper are released at https://github.com/forangel2014/Towards-Agentic-Self-Learning
Learning to Decide with Just Enough: Information-Theoretic Context Summarization for CDMPs
Oct 02, 2025



Contextual Markov Decision Processes (CMDPs) offer a framework for sequential decision-making under external signals, but existing methods often fail to generalize in high-dimensional or unstructured contexts, resulting in excessive computation and unstable performance. We propose an information-theoretic summarization approach that uses large language models (LLMs) to compress contextual inputs into low-dimensional, semantically rich summaries. These summaries augment states by preserving decision-critical cues while reducing redundancy. Building on the notion of approximate context sufficiency, we provide, to our knowledge, the first regret bounds and a latency-entropy trade-off characterization for CMDPs. Our analysis clarifies how informativeness impacts computational cost. Experiments across discrete, continuous, visual, and recommendation benchmarks show that our method outperforms raw-context and non-context baselines, improving reward, success rate, and sample efficiency, while reducing latency and memory usage. These findings demonstrate that LLM-based summarization offers a scalable and interpretable solution for efficient decision-making in context-rich, resource-constrained environments.
Self-Improvement for Audio Large Language Model using Unlabeled Speech
Jul 27, 2025Recent audio LLMs have emerged rapidly, demonstrating strong generalization across various speech tasks. However, given the inherent complexity of speech signals, these models inevitably suffer from performance degradation in specific target domains. To address this, we focus on enhancing audio LLMs in target domains without any labeled data. We propose a self-improvement method called SI-SDA, leveraging the information embedded in large-model decoding to evaluate the quality of generated pseudo labels and then perform domain adaptation based on reinforcement learning optimization. Experimental results show that our method consistently and significantly improves audio LLM performance, outperforming existing baselines in WER and BLEU across multiple public datasets of automatic speech recognition (ASR), spoken question-answering (SQA), and speech-to-text translation (S2TT). Furthermore, our approach exhibits high data efficiency, underscoring its potential for real-world deployment.
CCI4.0: A Bilingual Pretraining Dataset for Enhancing Reasoning in Large Language Models
Jun 09, 2025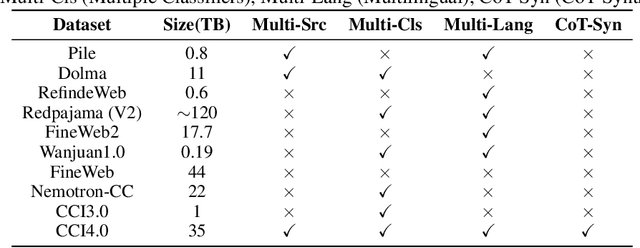
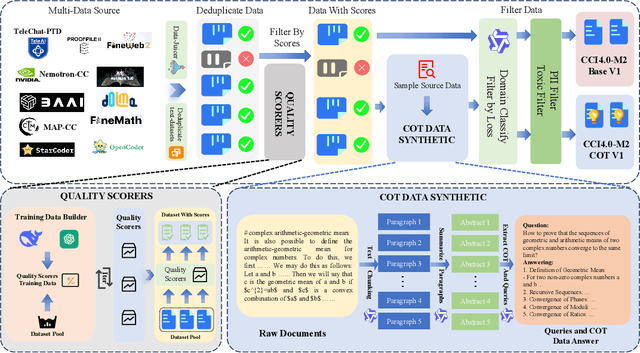
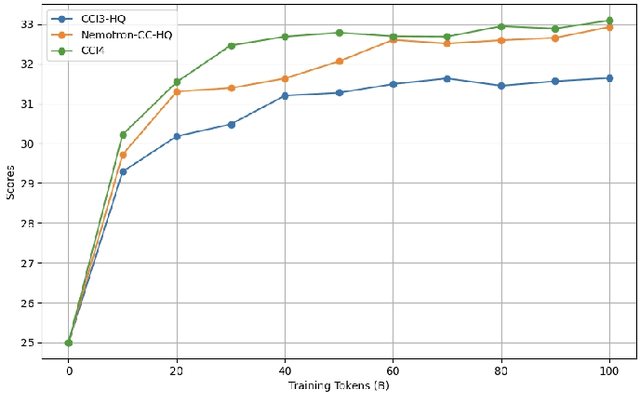
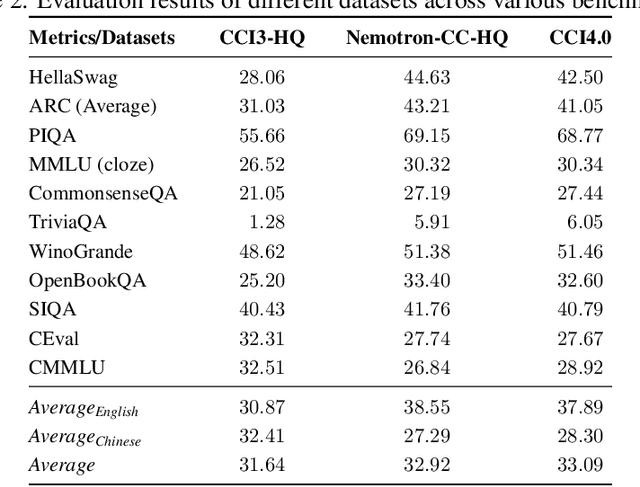
We introduce CCI4.0, a large-scale bilingual pre-training dataset engineered for superior data quality and diverse human-like reasoning trajectory. CCI4.0 occupies roughly $35$ TB of disk space and comprises two sub-datasets: CCI4.0-M2-Base and CCI4.0-M2-CoT. CCI4.0-M2-Base combines a $5.2$ TB carefully curated Chinese web corpus, a $22.5$ TB English subset from Nemotron-CC, and diverse sources from math, wiki, arxiv, and code. Although these data are mostly sourced from well-processed datasets, the quality standards of various domains are dynamic and require extensive expert experience and labor to process. So, we propose a novel pipeline justifying data quality mainly based on models through two-stage deduplication, multiclassifier quality scoring, and domain-aware fluency filtering. We extract $4.5$ billion pieces of CoT(Chain-of-Thought) templates, named CCI4.0-M2-CoT. Differing from the distillation of CoT from larger models, our proposed staged CoT extraction exemplifies diverse reasoning patterns and significantly decreases the possibility of hallucination. Empirical evaluations demonstrate that LLMs pre-trained in CCI4.0 benefit from cleaner, more reliable training signals, yielding consistent improvements in downstream tasks, especially in math and code reflection tasks. Our results underscore the critical role of rigorous data curation and human thinking templates in advancing LLM performance, shedding some light on automatically processing pretraining corpora.
HGCL: Hierarchical Graph Contrastive Learning for User-Item Recommendation
May 25, 2025Graph Contrastive Learning (GCL), which fuses graph neural networks with contrastive learning, has evolved as a pivotal tool in user-item recommendations. While promising, existing GCL methods often lack explicit modeling of hierarchical item structures, which represent item similarities across varying resolutions. Such hierarchical item structures are ubiquitous in various items (e.g., online products and local businesses), and reflect their inherent organizational properties that serve as critical signals for enhancing recommendation accuracy. In this paper, we propose Hierarchical Graph Contrastive Learning (HGCL), a novel GCL method that incorporates hierarchical item structures for user-item recommendations. First, HGCL pre-trains a GCL module using cross-layer contrastive learning to obtain user and item representations. Second, HGCL employs a representation compression and clustering method to construct a two-hierarchy user-item bipartite graph. Ultimately, HGCL fine-tunes user and item representations by learning on the hierarchical graph, and then provides recommendations based on user-item interaction scores. Experiments on three widely adopted benchmark datasets ranging from 70K to 382K nodes confirm the superior performance of HGCL over existing baseline models, highlighting the contribution of hierarchical item structures in enhancing GCL methods for recommendation tasks.
Amplify Adjacent Token Differences: Enhancing Long Chain-of-Thought Reasoning with Shift-FFN
May 22, 2025Recently, models such as OpenAI-o1 and DeepSeek-R1 have demonstrated remarkable performance on complex reasoning tasks through Long Chain-of-Thought (Long-CoT) reasoning. Although distilling this capability into student models significantly enhances their performance, this paper finds that fine-tuning LLMs with full parameters or LoRA with a low rank on long CoT data often leads to Cyclical Reasoning, where models repeatedly reiterate previous inference steps until the maximum length limit. Further analysis reveals that smaller differences in representations between adjacent tokens correlates with a higher tendency toward Cyclical Reasoning. To mitigate this issue, this paper proposes Shift Feedforward Networks (Shift-FFN), a novel approach that edits the current token's representation with the previous one before inputting it to FFN. This architecture dynamically amplifies the representation differences between adjacent tokens. Extensive experiments on multiple mathematical reasoning tasks demonstrate that LoRA combined with Shift-FFN achieves higher accuracy and a lower rate of Cyclical Reasoning across various data sizes compared to full fine-tuning and standard LoRA. Our data and code are available at https://anonymous.4open.science/r/Shift-FFN
Beyond Hard and Soft: Hybrid Context Compression for Balancing Local and Global Information Retention
May 21, 2025Large Language Models (LLMs) encounter significant challenges in long-sequence inference due to computational inefficiency and redundant processing, driving interest in context compression techniques. Existing methods often rely on token importance to perform hard local compression or encode context into latent representations for soft global compression. However, the uneven distribution of textual content relevance and the diversity of demands for user instructions mean these approaches frequently lead to the loss of potentially valuable information. To address this, we propose $\textbf{Hy}$brid $\textbf{Co}$ntext $\textbf{Co}$mpression (HyCo$_2$) for LLMs, which integrates both global and local perspectives to guide context compression while retaining both the essential semantics and critical details for task completion. Specifically, we employ a hybrid adapter to refine global semantics with the global view, based on the observation that different adapters excel at different tasks. Then we incorporate a classification layer that assigns a retention probability to each context token based on the local view, determining whether it should be retained or discarded. To foster a balanced integration of global and local compression, we introduce auxiliary paraphrasing and completion pretraining before instruction tuning. This promotes a synergistic integration that emphasizes instruction-relevant information while preserving essential local details, ultimately balancing local and global information retention in context compression. Experiments show that our HyCo$_2$ method significantly enhances long-text reasoning while reducing token usage. It improves the performance of various LLM series by an average of 13.1\% across seven knowledge-intensive QA benchmarks. Moreover, HyCo$_2$ matches the performance of uncompressed methods while reducing token consumption by 88.8\%.
Nemotron-H: A Family of Accurate and Efficient Hybrid Mamba-Transformer Models
Apr 10, 2025



As inference-time scaling becomes critical for enhanced reasoning capabilities, it is increasingly becoming important to build models that are efficient to infer. We introduce Nemotron-H, a family of 8B and 56B/47B hybrid Mamba-Transformer models designed to reduce inference cost for a given accuracy level. To achieve this goal, we replace the majority of self-attention layers in the common Transformer model architecture with Mamba layers that perform constant computation and require constant memory per generated token. We show that Nemotron-H models offer either better or on-par accuracy compared to other similarly-sized state-of-the-art open-sourced Transformer models (e.g., Qwen-2.5-7B/72B and Llama-3.1-8B/70B), while being up to 3$\times$ faster at inference. To further increase inference speed and reduce the memory required at inference time, we created Nemotron-H-47B-Base from the 56B model using a new compression via pruning and distillation technique called MiniPuzzle. Nemotron-H-47B-Base achieves similar accuracy to the 56B model, but is 20% faster to infer. In addition, we introduce an FP8-based training recipe and show that it can achieve on par results with BF16-based training. This recipe is used to train the 56B model. All Nemotron-H models will be released, with support in Hugging Face, NeMo, and Megatron-LM.