 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVICRegL: Self-Supervised Learning of Local Visual Features
Oct 04, 2022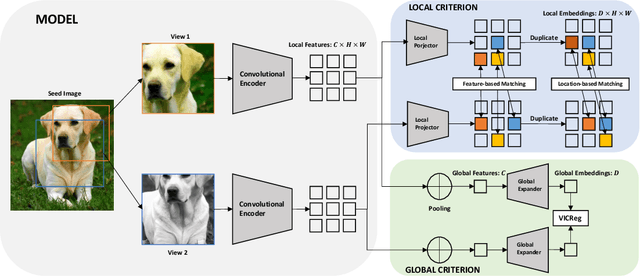
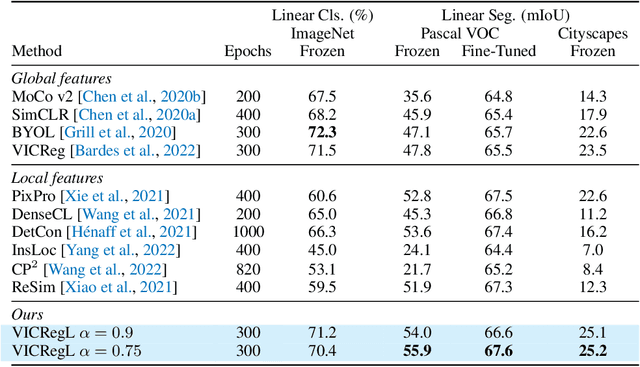
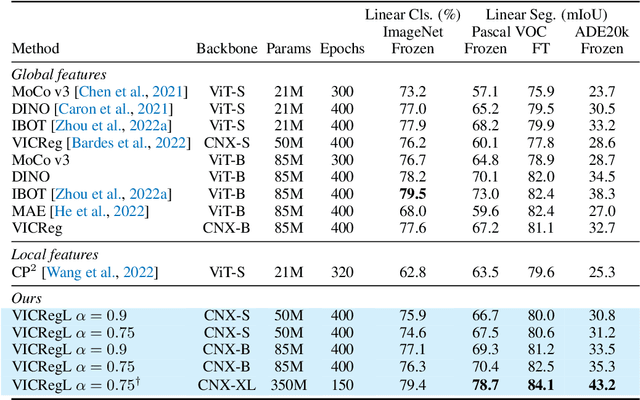
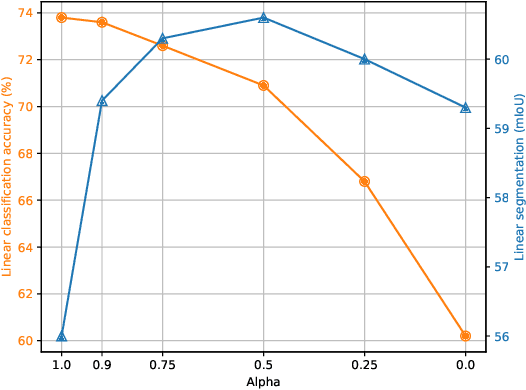
Most recent self-supervised methods for learning image representations focus on either producing a global feature with invariance properties, or producing a set of local features. The former works best for classification tasks while the latter is best for detection and segmentation tasks. This paper explores the fundamental trade-off between learning local and global features. A new method called VICRegL is proposed that learns good global and local features simultaneously, yielding excellent performance on detection and segmentation tasks while maintaining good performance on classification tasks. Concretely, two identical branches of a standard convolutional net architecture are fed two differently distorted versions of the same image. The VICReg criterion is applied to pairs of global feature vectors. Simultaneously, the VICReg criterion is applied to pairs of local feature vectors occurring before the last pooling layer. Two local feature vectors are attracted to each other if their l2-distance is below a threshold or if their relative locations are consistent with a known geometric transformation between the two input images. We demonstrate strong performance on linear classification and segmentation transfer tasks. Code and pretrained models are publicly available at: https://github.com/facebookresearch/VICRegL
Minimalistic Unsupervised Learning with the Sparse Manifold Transform
Sep 30, 2022



We describe a minimalistic and interpretable method for unsupervised learning, without resorting to data augmentation, hyperparameter tuning, or other engineering designs, that achieves performance close to the SOTA SSL methods. Our approach leverages the sparse manifold transform, which unifies sparse coding, manifold learning, and slow feature analysis. With a one-layer deterministic sparse manifold transform, one can achieve 99.3% KNN top-1 accuracy on MNIST, 81.1% KNN top-1 accuracy on CIFAR-10 and 53.2% on CIFAR-100. With a simple gray-scale augmentation, the model gets 83.2% KNN top-1 accuracy on CIFAR-10 and 57% on CIFAR-100. These results significantly close the gap between simplistic ``white-box'' methods and the SOTA methods. Additionally, we provide visualization to explain how an unsupervised representation transform is formed. The proposed method is closely connected to latent-embedding self-supervised methods and can be treated as the simplest form of VICReg. Though there remains a small performance gap between our simple constructive model and SOTA methods, the evidence points to this as a promising direction for achieving a principled and white-box approach to unsupervised learning.
Variance Covariance Regularization Enforces Pairwise Independence in Self-Supervised Representations
Sep 29, 2022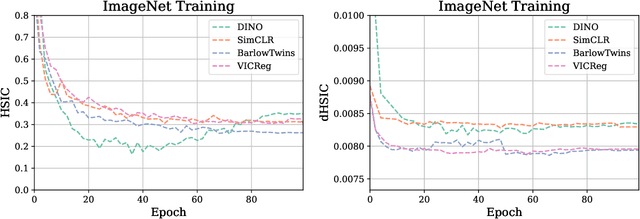
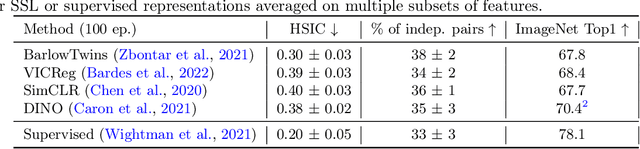
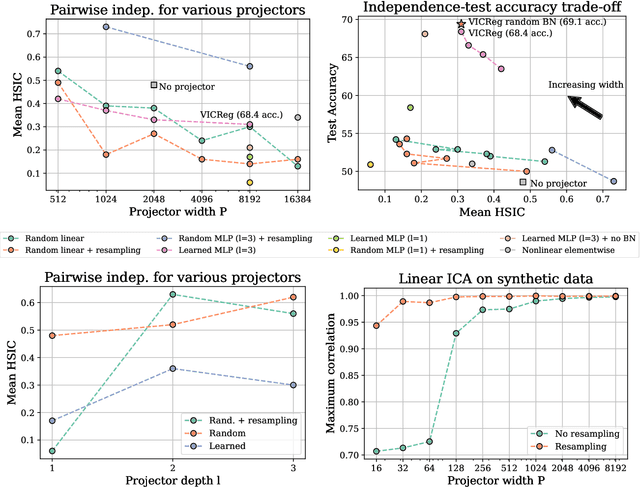

Self-Supervised Learning (SSL) methods such as VICReg, Barlow Twins or W-MSE avoid collapse of their joint embedding architectures by constraining or regularizing the covariance matrix of their projector's output. This study highlights important properties of such strategy, which we coin Variance-Covariance regularization (VCReg). More precisely, we show that VCReg enforces pairwise independence between the features of the learned representation. This result emerges by bridging VCReg applied on the projector's output to kernel independence criteria applied on the projector's input. This provides the first theoretical motivations and explanations of VCReg. We empirically validate our findings where (i) we observe that SSL methods employing VCReg learn visual representations with greater pairwise independence than other methods, (i) we put in evidence which projector's characteristics favor pairwise independence, and show it to emerge independently from learning the projector, (ii) we use these findings to obtain nontrivial performance gains for VICReg, (iii) we demonstrate that the scope of VCReg goes beyond SSL by using it to solve Independent Component Analysis. We hope that our findings will support the adoption of VCReg in SSL and beyond.
Joint Embedding Self-Supervised Learning in the Kernel Regime
Sep 29, 2022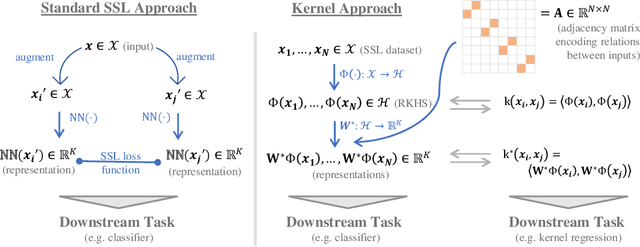
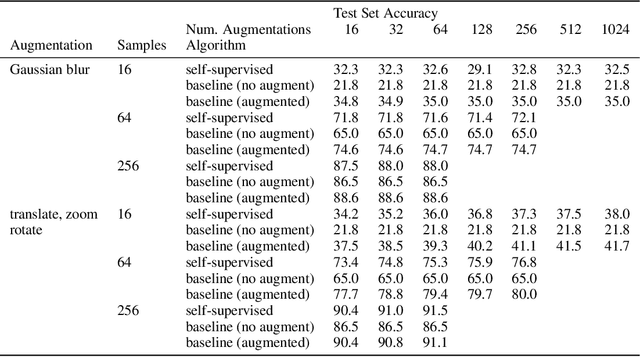
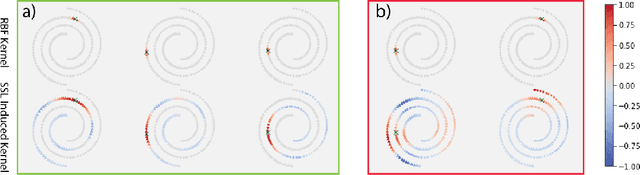
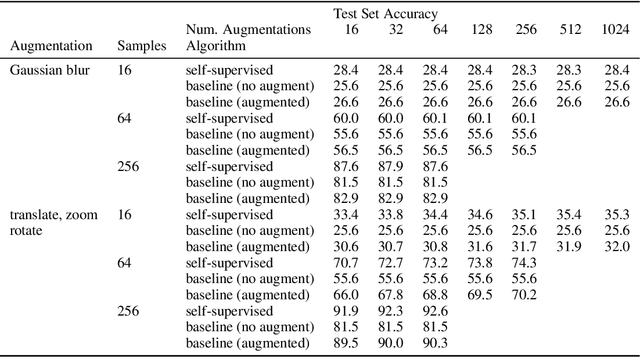
The fundamental goal of self-supervised learning (SSL) is to produce useful representations of data without access to any labels for classifying the data. Modern methods in SSL, which form representations based on known or constructed relationships between samples, have been particularly effective at this task. Here, we aim to extend this framework to incorporate algorithms based on kernel methods where embeddings are constructed by linear maps acting on the feature space of a kernel. In this kernel regime, we derive methods to find the optimal form of the output representations for contrastive and non-contrastive loss functions. This procedure produces a new representation space with an inner product denoted as the induced kernel which generally correlates points which are related by an augmentation in kernel space and de-correlates points otherwise. We analyze our kernel model on small datasets to identify common features of self-supervised learning algorithms and gain theoretical insights into their performance on downstream tasks.
Light-weight probing of unsupervised representations for Reinforcement Learning
Aug 25, 2022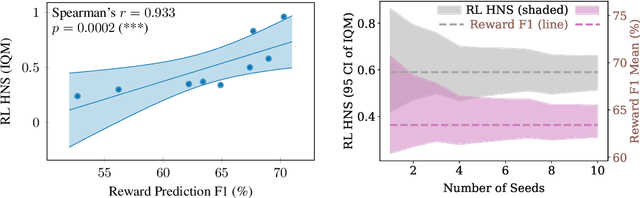
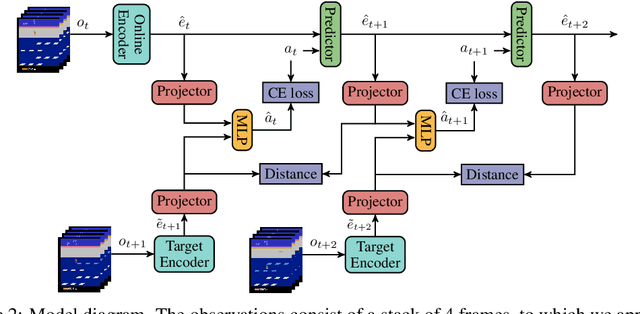
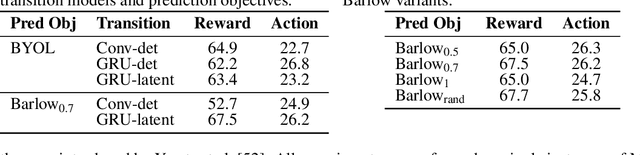

Unsupervised visual representation learning offers the opportunity to leverage large corpora of unlabeled trajectories to form useful visual representations, which can benefit the training of reinforcement learning (RL) algorithms. However, evaluating the fitness of such representations requires training RL algorithms which is computationally intensive and has high variance outcomes. To alleviate this issue, we design an evaluation protocol for unsupervised RL representations with lower variance and up to 600x lower computational cost. Inspired by the vision community, we propose two linear probing tasks: predicting the reward observed in a given state, and predicting the action of an expert in a given state. These two tasks are generally applicable to many RL domains, and we show through rigorous experimentation that they correlate strongly with the actual downstream control performance on the Atari100k Benchmark. This provides a better method for exploring the space of pretraining algorithms without the need of running RL evaluations for every setting. Leveraging this framework, we further improve existing self-supervised learning (SSL) recipes for RL, highlighting the importance of the forward model, the size of the visual backbone, and the precise formulation of the unsupervised objective.
What Do We Maximize in Self-Supervised Learning?
Jul 20, 2022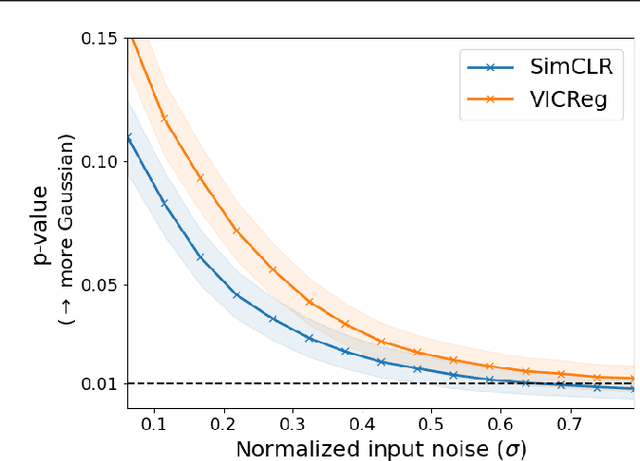
In this paper, we examine self-supervised learning methods, particularly VICReg, to provide an information-theoretical understanding of their construction. As a first step, we demonstrate how information-theoretic quantities can be obtained for a deterministic network, offering a possible alternative to prior work that relies on stochastic models. This enables us to demonstrate how VICReg can be (re)discovered from first principles and its assumptions about data distribution. Furthermore, we empirically demonstrate the validity of our assumptions, confirming our novel understanding of VICReg. Finally, we believe that the derivation and insights we obtain can be generalized to many other SSL methods, opening new avenues for theoretical and practical understanding of SSL and transfer learning.
TiCo: Transformation Invariance and Covariance Contrast for Self-Supervised Visual Representation Learning
Jun 23, 2022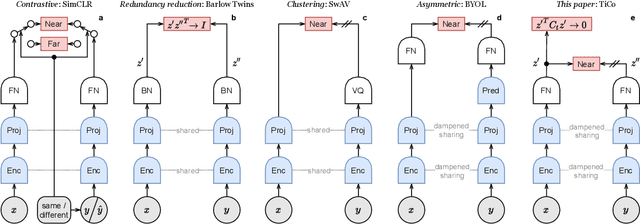
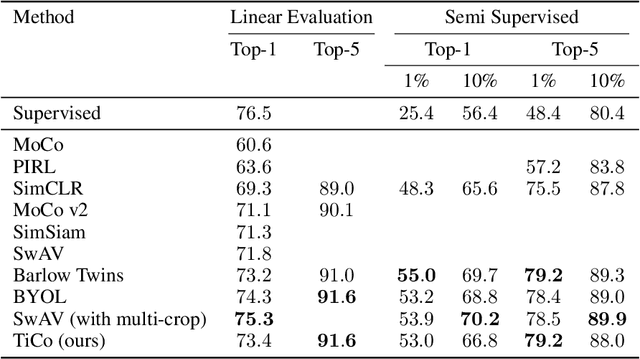
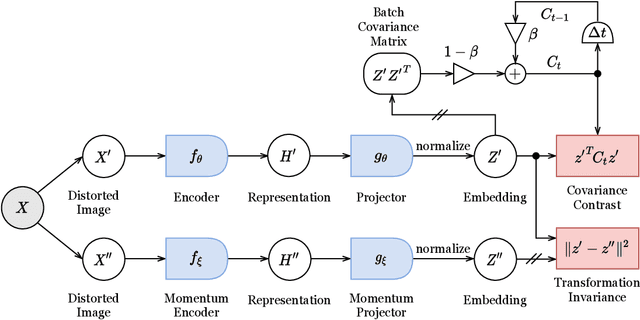
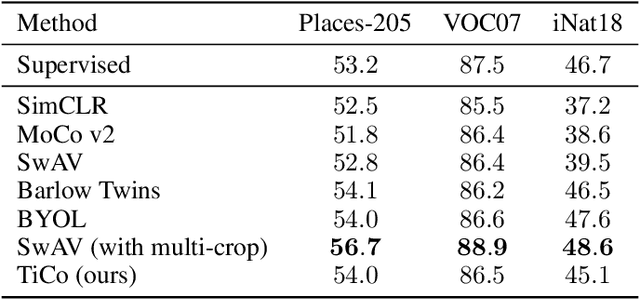
We present Transformation Invariance and Covariance Contrast (TiCo) for self-supervised visual representation learning. Similar to other recent self-supervised learning methods, our method is based on maximizing the agreement among embeddings of different distorted versions of the same image, which pushes the encoder to produce transformation invariant representations. To avoid the trivial solution where the encoder generates constant vectors, we regularize the covariance matrix of the embeddings from different images by penalizing low rank solutions. By jointly minimizing the transformation invariance loss and covariance contrast loss, we get an encoder that is able to produce useful representations for downstream tasks. We analyze our method and show that it can be viewed as a variant of MoCo with an implicit memory bank of unlimited size at no extra memory cost. This makes our method perform better than alternative methods when using small batch sizes. TiCo can also be seen as a modification of Barlow Twins. By connecting the contrastive and redundancy-reduction methods together, TiCo gives us new insights into how joint embedding methods work.
Intra-Instance VICReg: Bag of Self-Supervised Image Patch Embedding
Jun 17, 2022

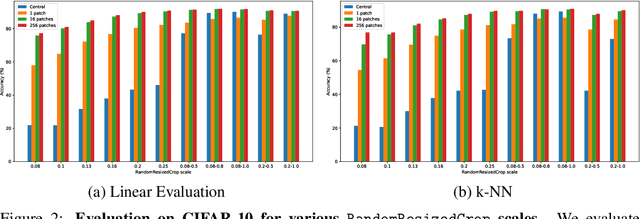

Recently, self-supervised learning (SSL) has achieved tremendous empirical advancements in learning image representation. However, our understanding and knowledge of the representation are still limited. This work shows that the success of the SOTA siamese-network-based SSL approaches is primarily based on learning a representation of image patches. Particularly, we show that when we learn a representation only for fixed-scale image patches and aggregate different patch representations linearly for an image (instance), it can achieve on par or even better results than the baseline methods on several benchmarks. Further, we show that the patch representation aggregation can also improve various SOTA baseline methods by a large margin. We also establish a formal connection between the SSL objective and the image patches co-occurrence statistics modeling, which supplements the prevailing invariance perspective. By visualizing the nearest neighbors of different image patches in the embedding space and projection space, we show that while the projection has more invariance, the embedding space tends to preserve more equivariance and locality. Finally, we propose a hypothesis for the future direction based on the discovery of this work.
Masked Siamese ConvNets
Jun 15, 2022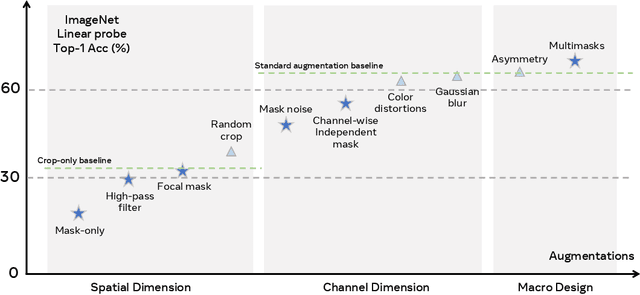
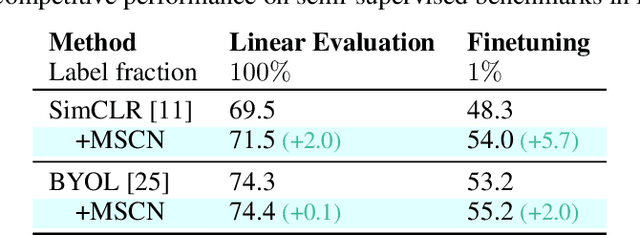

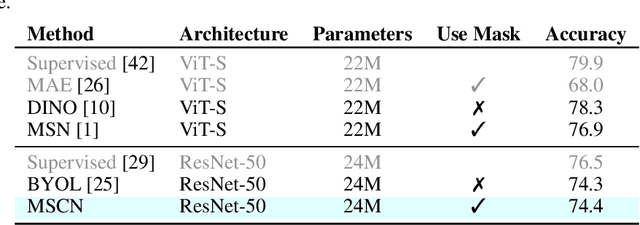
Self-supervised learning has shown superior performances over supervised methods on various vision benchmarks. The siamese network, which encourages embeddings to be invariant to distortions, is one of the most successful self-supervised visual representation learning approaches. Among all the augmentation methods, masking is the most general and straightforward method that has the potential to be applied to all kinds of input and requires the least amount of domain knowledge. However, masked siamese networks require particular inductive bias and practically only work well with Vision Transformers. This work empirically studies the problems behind masked siamese networks with ConvNets. We propose several empirical designs to overcome these problems gradually. Our method performs competitively on low-shot image classification and outperforms previous methods on object detection benchmarks. We discuss several remaining issues and hope this work can provide useful data points for future general-purpose self-supervised learning.
Coarse-to-Fine Vision-Language Pre-training with Fusion in the Backbone
Jun 15, 2022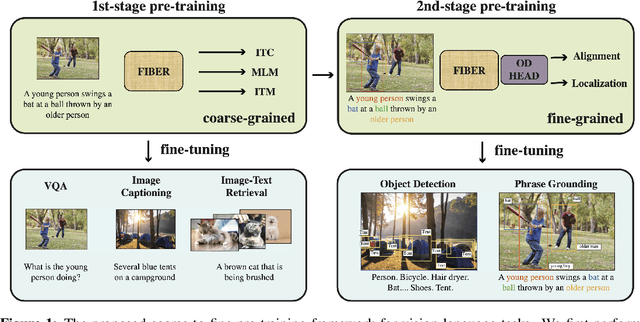

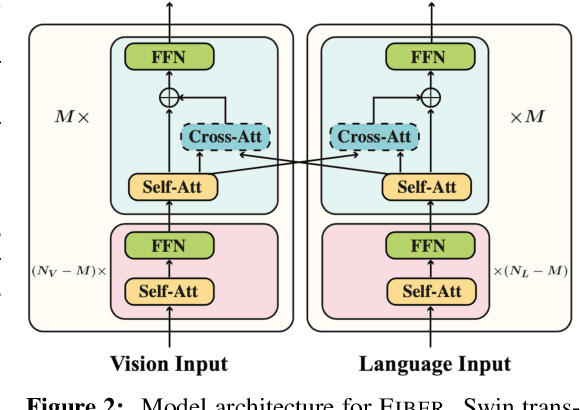
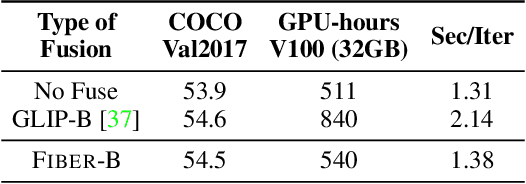
Vision-language (VL) pre-training has recently received considerable attention. However, most existing end-to-end pre-training approaches either only aim to tackle VL tasks such as image-text retrieval, visual question answering (VQA) and image captioning that test high-level understanding of images, or only target region-level understanding for tasks such as phrase grounding and object detection. We present FIBER (Fusion-In-the-Backbone-based transformER), a new VL model architecture that can seamlessly handle both these types of tasks. Instead of having dedicated transformer layers for fusion after the uni-modal backbones, FIBER pushes multimodal fusion deep into the model by inserting cross-attention into the image and text backbones, bringing gains in terms of memory and performance. In addition, unlike previous work that is either only pre-trained on image-text data or on fine-grained data with box-level annotations, we present a two-stage pre-training strategy that uses both these kinds of data efficiently: (i) coarse-grained pre-training based on image-text data; followed by (ii) fine-grained pre-training based on image-text-box data. We conduct comprehensive experiments on a wide range of VL tasks, ranging from VQA, image captioning, and retrieval, to phrase grounding, referring expression comprehension, and object detection. Using deep multimodal fusion coupled with the two-stage pre-training, FIBER provides consistent performance improvements over strong baselines across all tasks, often outperforming methods using magnitudes more data. Code is available at https://github.com/microsoft/FIBER.