 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFRESCO: Benchmarking and Optimizing Re-rankers for Evolving Semantic Conflict in Retrieval-Augmented Generation
Apr 14, 2026Retrieval-Augmented Generation (RAG) is a key approach to mitigating the temporal staleness of large language models (LLMs) by grounding responses in up-to-date evidence. Within the RAG pipeline, re-rankers play a pivotal role in selecting the most useful documents from retrieved candidates. However, existing benchmarks predominantly evaluate re-rankers in static settings and do not adequately assess performance under evolving information -- a critical gap, as real-world systems often must choose among temporally different pieces of evidence. To address this limitation, we introduce FRESCO (Factual Recency and Evolving Semantic COnflict), a benchmark for evaluating re-rankers in temporally dynamic contexts. By pairing recency-seeking queries with historical Wikipedia revisions, FRESCO tests whether re-rankers can prioritize factually recent evidence while maintaining semantic relevance. Our evaluation reveals a consistent failure mode across existing re-rankers: a strong bias toward older, semantically rich documents, even when they are factually obsolete. We further investigate an instruction optimization framework to mitigate this issue. By identifying Pareto-optimal instructions that balance Evolving and Non-Evolving Knowledge tasks, we obtain gains of up to 27% on Evolving Knowledge tasks while maintaining competitive performance on Non-Evolving Knowledge tasks.
Dynamic Graph Representation Learning via Graph Transformer Networks
Nov 19, 2021
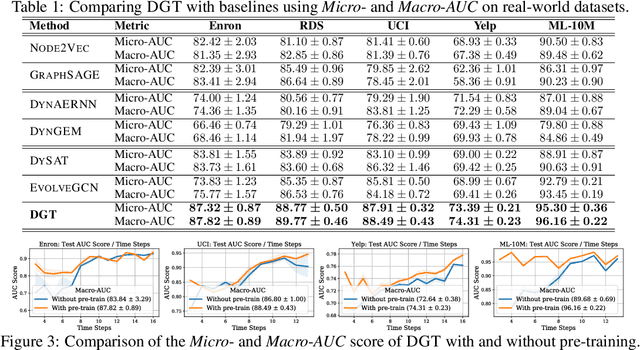
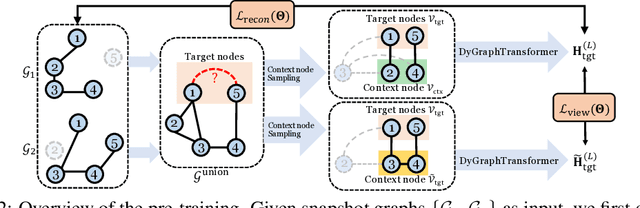
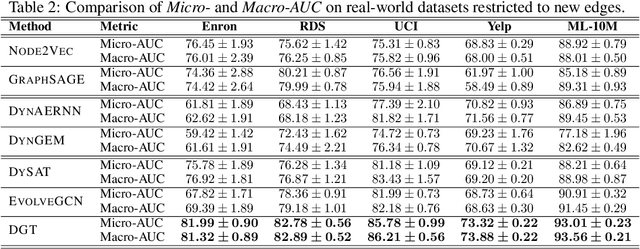
Dynamic graph representation learning is an important task with widespread applications. Previous methods on dynamic graph learning are usually sensitive to noisy graph information such as missing or spurious connections, which can yield degenerated performance and generalization. To overcome this challenge, we propose a Transformer-based dynamic graph learning method named Dynamic Graph Transformer (DGT) with spatial-temporal encoding to effectively learn graph topology and capture implicit links. To improve the generalization ability, we introduce two complementary self-supervised pre-training tasks and show that jointly optimizing the two pre-training tasks results in a smaller Bayesian error rate via an information-theoretic analysis. We also propose a temporal-union graph structure and a target-context node sampling strategy for efficient and scalable training. Extensive experiments on real-world datasets illustrate that DGT presents superior performance compared with several state-of-the-art baselines.