 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan LLMs Learn to Map the World from Local Descriptions?
May 27, 2025Recent advances in Large Language Models (LLMs) have demonstrated strong capabilities in tasks such as code and mathematics. However, their potential to internalize structured spatial knowledge remains underexplored. This study investigates whether LLMs, grounded in locally relative human observations, can construct coherent global spatial cognition by integrating fragmented relational descriptions. We focus on two core aspects of spatial cognition: spatial perception, where models infer consistent global layouts from local positional relationships, and spatial navigation, where models learn road connectivity from trajectory data and plan optimal paths between unconnected locations. Experiments conducted in a simulated urban environment demonstrate that LLMs not only generalize to unseen spatial relationships between points of interest (POIs) but also exhibit latent representations aligned with real-world spatial distributions. Furthermore, LLMs can learn road connectivity from trajectory descriptions, enabling accurate path planning and dynamic spatial awareness during navigation.
ARM: Adaptive Reasoning Model
May 26, 2025



While large reasoning models demonstrate strong performance on complex tasks, they lack the ability to adjust reasoning token usage based on task difficulty. This often leads to the "overthinking" problem -- excessive and unnecessary reasoning -- which, although potentially mitigated by human intervention to control the token budget, still fundamentally contradicts the goal of achieving fully autonomous AI. In this work, we propose Adaptive Reasoning Model (ARM), a reasoning model capable of adaptively selecting appropriate reasoning formats based on the task at hand. These formats include three efficient ones -- Direct Answer, Short CoT, and Code -- as well as a more elaborate format, Long CoT. To train ARM, we introduce Ada-GRPO, an adaptation of Group Relative Policy Optimization (GRPO), which addresses the format collapse issue in traditional GRPO. Ada-GRPO enables ARM to achieve high token efficiency, reducing tokens by an average of 30%, and up to 70%, while maintaining performance comparable to the model that relies solely on Long CoT. Furthermore, not only does it improve inference efficiency through reduced token generation, but it also brings a 2x speedup in training. In addition to the default Adaptive Mode, ARM supports two additional reasoning modes: 1) Instruction-Guided Mode, which allows users to explicitly specify the reasoning format via special tokens -- ideal when the appropriate format is known for a batch of tasks. 2) Consensus-Guided Mode, which aggregates the outputs of the three efficient formats and resorts to Long CoT in case of disagreement, prioritizing performance with higher token usage.
BookWorld: From Novels to Interactive Agent Societies for Creative Story Generation
Apr 20, 2025



Recent advances in large language models (LLMs) have enabled social simulation through multi-agent systems. Prior efforts focus on agent societies created from scratch, assigning agents with newly defined personas. However, simulating established fictional worlds and characters remain largely underexplored, despite its significant practical value. In this paper, we introduce BookWorld, a comprehensive system for constructing and simulating book-based multi-agent societies. BookWorld's design covers comprehensive real-world intricacies, including diverse and dynamic characters, fictional worldviews, geographical constraints and changes, e.t.c. BookWorld enables diverse applications including story generation, interactive games and social simulation, offering novel ways to extend and explore beloved fictional works. Through extensive experiments, we demonstrate that BookWorld generates creative, high-quality stories while maintaining fidelity to the source books, surpassing previous methods with a win rate of 75.36%. The code of this paper can be found at the project page: https://bookworld2025.github.io/.
LITE: LLM-Impelled efficient Taxonomy Evaluation
Apr 02, 2025This paper presents LITE, an LLM-based evaluation method designed for efficient and flexible assessment of taxonomy quality. To address challenges in large-scale taxonomy evaluation, such as efficiency, fairness, and consistency, LITE adopts a top-down hierarchical evaluation strategy, breaking down the taxonomy into manageable substructures and ensuring result reliability through cross-validation and standardized input formats. LITE also introduces a penalty mechanism to handle extreme cases and provides both quantitative performance analysis and qualitative insights by integrating evaluation metrics closely aligned with task objectives. Experimental results show that LITE demonstrates high reliability in complex evaluation tasks, effectively identifying semantic errors, logical contradictions, and structural flaws in taxonomies, while offering directions for improvement. Code is available at https://github.com/Zhang-l-i-n/TAXONOMY_DETECT .
RECKON: Large-scale Reference-based Efficient Knowledge Evaluation for Large Language Model
Apr 01, 2025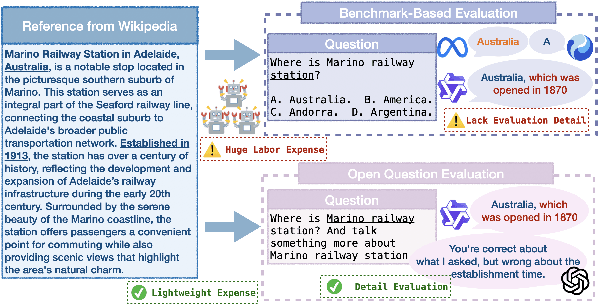
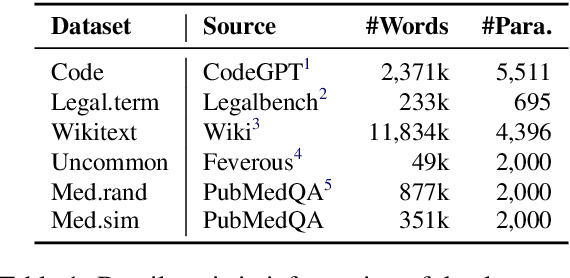
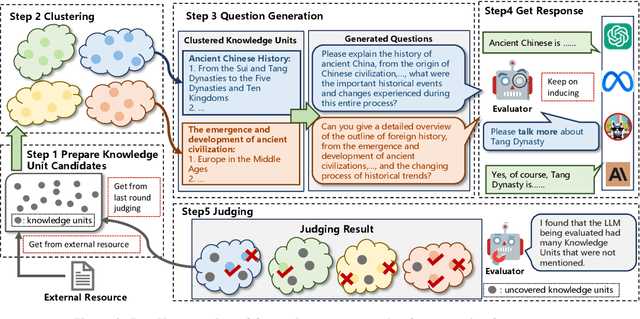
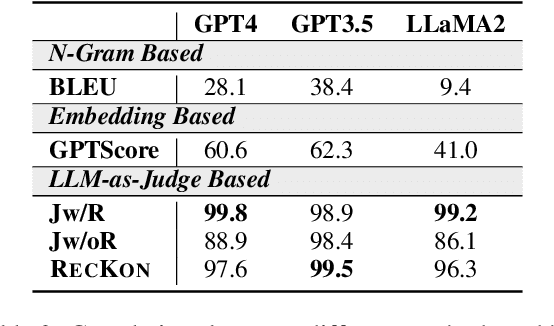
As large language models (LLMs) advance, efficient knowledge evaluation becomes crucial to verifying their capabilities. Traditional methods, relying on benchmarks, face limitations such as high resource costs and information loss. We propose the Large-scale Reference-based Efficient Knowledge Evaluation for Large Language Model (RECKON), which directly uses reference data to evaluate models. RECKON organizes unstructured data into manageable units and generates targeted questions for each cluster, improving evaluation accuracy and efficiency. Experimental results show that RECKON reduces resource consumption by 56.5% compared to traditional methods while achieving over 97% accuracy across various domains, including world knowledge, code, legal, and biomedical datasets. Code is available at https://github.com/MikeGu721/reckon
ToReMi: Topic-Aware Data Reweighting for Dynamic Pre-Training Data Selection
Apr 01, 2025



Pre-training large language models (LLMs) necessitates enormous diverse textual corpora, making effective data selection a key challenge for balancing computational resources and model performance. Current methodologies primarily emphasize data quality metrics and mixing proportions, yet they fail to adequately capture the underlying semantic connections between training samples and quality disparities within individual domains. We introduce ToReMi (Topic-based Reweighting for Model improvement), a novel two-stage framework that dynamically adjusts training sample weights according to their topical associations and observed learning patterns. Our comprehensive experiments reveal that ToReMi variants consistently achieve superior performance over conventional pre-training approaches, demonstrating accelerated perplexity reduction across multiple domains and enhanced capabilities on downstream evaluation tasks. Code is available at https://github.com/zxx000728/ToReMi.
GAPO: Learning Preferential Prompt through Generative Adversarial Policy Optimization
Mar 26, 2025Recent advances in large language models have highlighted the critical need for precise control over model outputs through predefined constraints. While existing methods attempt to achieve this through either direct instruction-response synthesis or preferential response optimization, they often struggle with constraint understanding and adaptation. This limitation becomes particularly evident when handling fine-grained constraints, leading to either hallucination or brittle performance. We introduce Generative Adversarial Policy Optimization (GAPO), a novel framework that combines GAN-based training dynamics with an encoder-only reward model to progressively learn and adapt to increasingly complex constraints. GAPO leverages adversarial training to automatically generate training samples of varying difficulty while utilizing the encoder-only architecture to better capture prompt-response relationships. Extensive experiments demonstrate GAPO's superior performance across multiple benchmarks, particularly in scenarios requiring fine-grained constraint handling, where it significantly outperforms existing methods like PPO, DPO, and KTO. Our results suggest that GAPO's unique approach to preferential prompt learning offers a more robust and effective solution for controlling LLM outputs. Code is avaliable in https://github.com/MikeGu721/GAPO.
PowerAttention: Exponentially Scaling of Receptive Fields for Effective Sparse Attention
Mar 05, 2025



Large Language Models (LLMs) face efficiency bottlenecks due to the quadratic complexity of the attention mechanism when processing long contexts. Sparse attention methods offer a promising solution, but existing approaches often suffer from incomplete effective context and/or require complex implementation of pipeline. We present a comprehensive analysis of sparse attention for autoregressive LLMs from the respective of receptive field, recognize the suboptimal nature of existing methods for expanding the receptive field, and introduce PowerAttention, a novel sparse attention design that facilitates effective and complete context extension through the theoretical analysis. PowerAttention achieves exponential receptive field growth in $d$-layer LLMs, allowing each output token to attend to $2^d$ tokens, ensuring completeness and continuity of the receptive field. Experiments demonstrate that PowerAttention outperforms existing static sparse attention methods by $5\sim 40\%$, especially on tasks demanding long-range dependencies like Passkey Retrieval and RULER, while maintaining a comparable time complexity to sliding window attention. Efficiency evaluations further highlight PowerAttention's superior speedup in both prefilling and decoding phases compared with dynamic sparse attentions and full attention ($3.0\times$ faster on 128K context), making it a highly effective and user-friendly solution for processing long sequences in LLMs.
MCiteBench: A Benchmark for Multimodal Citation Text Generation in MLLMs
Mar 05, 2025Multimodal Large Language Models (MLLMs) have advanced in integrating diverse modalities but frequently suffer from hallucination. A promising solution to mitigate this issue is to generate text with citations, providing a transparent chain for verification. However, existing work primarily focuses on generating citations for text-only content, overlooking the challenges and opportunities of multimodal contexts. To address this gap, we introduce MCiteBench, the first benchmark designed to evaluate and analyze the multimodal citation text generation ability of MLLMs. Our benchmark comprises data derived from academic papers and review-rebuttal interactions, featuring diverse information sources and multimodal content. We comprehensively evaluate models from multiple dimensions, including citation quality, source reliability, and answer accuracy. Through extensive experiments, we observe that MLLMs struggle with multimodal citation text generation. We also conduct deep analyses of models' performance, revealing that the bottleneck lies in attributing the correct sources rather than understanding the multimodal content.
Order Doesn't Matter, But Reasoning Does: Training LLMs with Order-Centric Augmentation
Feb 27, 2025



Logical reasoning is essential for large language models (LLMs) to ensure accurate and coherent inference. However, LLMs struggle with reasoning order variations and fail to generalize across logically equivalent transformations. LLMs often rely on fixed sequential patterns rather than true logical understanding. To address this issue, we introduce an order-centric data augmentation framework based on commutativity in logical reasoning. We first randomly shuffle independent premises to introduce condition order augmentation. For reasoning steps, we construct a directed acyclic graph (DAG) to model dependencies between steps, which allows us to identify valid reorderings of steps while preserving logical correctness. By leveraging order-centric augmentations, models can develop a more flexible and generalized reasoning process. Finally, we conduct extensive experiments across multiple logical reasoning benchmarks, demonstrating that our method significantly enhances LLMs' reasoning performance and adaptability to diverse logical structures. We release our codes and augmented data in https://anonymous.4open.science/r/Order-Centric-Data-Augmentation-822C/.