 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLSRIF: Logic-Structured Reinforcement Learning for Instruction Following
Jan 10, 2026Instruction-following is critical for large language models, but real-world instructions often contain logical structures such as sequential dependencies and conditional branching. Existing methods typically construct datasets with parallel constraints and optimize average rewards, ignoring logical dependencies and yielding noisy signals. We propose a logic-structured training framework LSRIF that explicitly models instruction logic. We first construct a dataset LSRInstruct with constraint structures such as parallel, sequential, and conditional types, and then design structure-aware rewarding method LSRIF including average aggregation for parallel structures, failure-penalty propagation for sequential structures, and selective rewards for conditional branches. Experiments show LSRIF brings significant improvements in instruction-following (in-domain and out-of-domain) and general reasoning. Analysis reveals that learning with explicit logic structures brings parameter updates in attention layers and sharpens token-level attention to constraints and logical operators.
Instructions are all you need: Self-supervised Reinforcement Learning for Instruction Following
Oct 16, 2025Language models often struggle to follow multi-constraint instructions that are crucial for real-world applications. Existing reinforcement learning (RL) approaches suffer from dependency on external supervision and sparse reward signals from multi-constraint tasks. We propose a label-free self-supervised RL framework that eliminates dependency on external supervision by deriving reward signals directly from instructions and generating pseudo-labels for reward model training. Our approach introduces constraint decomposition strategies and efficient constraint-wise binary classification to address sparse reward challenges while maintaining computational efficiency. Experiments show that our approach generalizes well, achieving strong improvements across 3 in-domain and 5 out-of-domain datasets, including challenging agentic and multi-turn instruction following. The data and code are publicly available at https://github.com/Rainier-rq/verl-if
Order Doesn't Matter, But Reasoning Does: Training LLMs with Order-Centric Augmentation
Feb 27, 2025



Logical reasoning is essential for large language models (LLMs) to ensure accurate and coherent inference. However, LLMs struggle with reasoning order variations and fail to generalize across logically equivalent transformations. LLMs often rely on fixed sequential patterns rather than true logical understanding. To address this issue, we introduce an order-centric data augmentation framework based on commutativity in logical reasoning. We first randomly shuffle independent premises to introduce condition order augmentation. For reasoning steps, we construct a directed acyclic graph (DAG) to model dependencies between steps, which allows us to identify valid reorderings of steps while preserving logical correctness. By leveraging order-centric augmentations, models can develop a more flexible and generalized reasoning process. Finally, we conduct extensive experiments across multiple logical reasoning benchmarks, demonstrating that our method significantly enhances LLMs' reasoning performance and adaptability to diverse logical structures. We release our codes and augmented data in https://anonymous.4open.science/r/Order-Centric-Data-Augmentation-822C/.
Order Matters: Investigate the Position Bias in Multi-constraint Instruction Following
Feb 24, 2025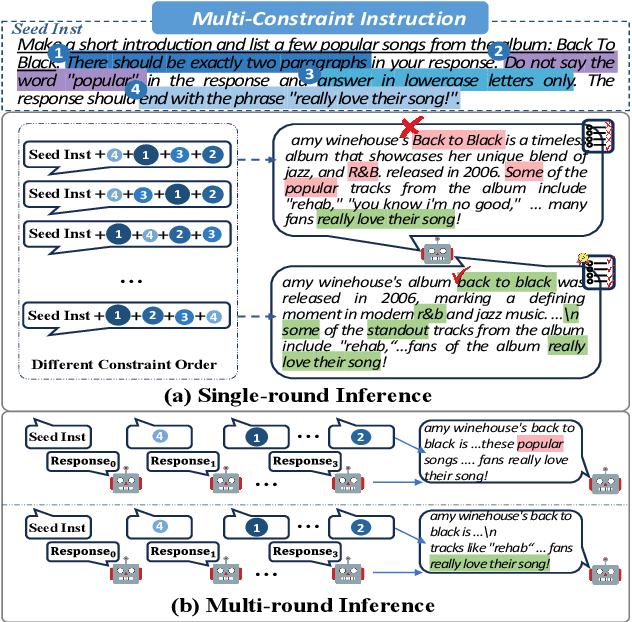
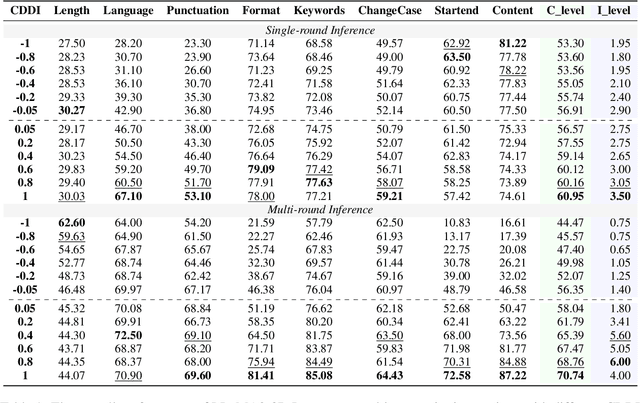
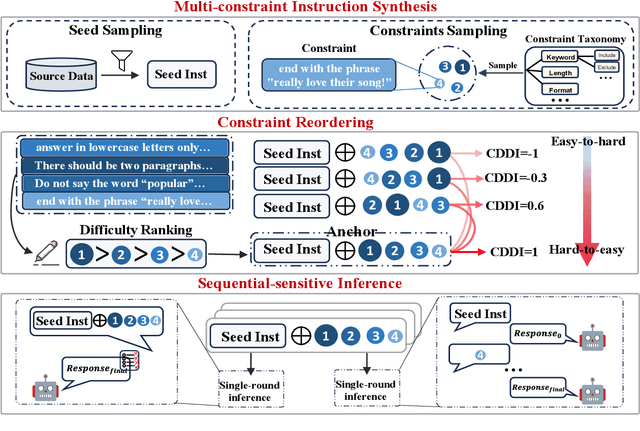

Real-world instructions with multiple constraints pose a significant challenge to existing large language models (LLMs). An observation is that the LLMs exhibit dramatic performance fluctuation when disturbing the order of the incorporated constraints. Yet, none of the existing works has systematically investigated this position bias problem in the field of multi-constraint instruction following. To bridge this gap, we design a probing task where we quantitatively measure the difficulty distribution of the constraints by a novel Difficulty Distribution Index (CDDI). Through the experimental results, we find that LLMs are more performant when presented with the constraints in a ``hard-to-easy'' order. This preference can be generalized to LLMs with different architecture or different sizes of parameters. Additionally, we conduct an explanation study, providing an intuitive insight into the correlation between the LLM's attention and constraint orders. Our code and dataset are publicly available at https://github.com/meowpass/PBIF.
Step-by-Step Mastery: Enhancing Soft Constraint Following Ability of Large Language Models
Jan 09, 2025It is crucial for large language models (LLMs) to follow instructions that involve multiple constraints. However, soft constraints are semantically related and difficult to verify through automated methods. These constraints remain a significant challenge for LLMs. To enhance the ability of LLMs to follow soft constraints, we initially design a pipeline to obtain high-quality outputs automatically. Additionally, to fully utilize the acquired data, we introduce a training paradigm based on curriculum learning. We experimentally evaluate the effectiveness of our methods in improving LLMs' soft constraint following ability and analyze the factors driving the improvements. The datasets and code are publicly available at https://github.com/Rainier-rq/FollowSoftConstraints.
Minor DPO reject penalty to increase training robustness
Aug 22, 2024



Learning from human preference is a paradigm used in large-scale language model (LLM) fine-tuning step to better align pretrained LLM to human preference for downstream task. In the past it uses reinforcement learning from human feedback (RLHF) algorithm to optimize the LLM policy to align with these preferences and not to draft too far from the original model. Recently, Direct Preference Optimization (DPO) has been proposed to solve the alignment problem with a simplified RL-free method. Using preference pairs of chosen and reject data, DPO models the relative log probability as implicit reward function and optimize LLM policy using a simple binary cross entropy objective directly. DPO is quite straight forward and easy to be understood. It perform efficiently and well in most cases. In this article, we analyze the working mechanism of $\beta$ in DPO, disclose its syntax difference between RL algorithm and DPO, and understand the potential shortage brought by the DPO simplification. With these insights, we propose MinorDPO, which is better aligned to the original RL algorithm, and increase the stability of preference optimization process.
Minor SFT loss for LLM fine-tune to increase performance and reduce model deviation
Aug 20, 2024

Instruct LLM provide a paradigm used in large scale language model to align LLM to human preference. The paradigm contains supervised fine tuning and reinforce learning from human feedback. This paradigm is also used in downstream scenarios to adapt LLM to specific corpora and applications. Comparing to SFT, there are many efforts focused on RLHF and several algorithms being proposed, such as PPO, DPO, IPO, KTO, MinorDPO and etc. Meanwhile most efforts for SFT are focused on how to collect, filter and mix high quality data. In this article with insight from DPO and MinorDPO, we propose a training metric for SFT to measure the discrepancy between the optimized model and the original model, and a loss function MinorSFT that can increase the training effectiveness, and reduce the discrepancy between the optimized LLM and original LLM.