 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentGroupChat-V2: Divide-and-Conquer Is What LLM-Based Multi-Agent System Need
Jun 18, 2025Large language model based multi-agent systems have demonstrated significant potential in social simulation and complex task resolution domains. However, current frameworks face critical challenges in system architecture design, cross-domain generalizability, and performance guarantees, particularly as task complexity and number of agents increases. We introduces AgentGroupChat-V2, a novel framework addressing these challenges through three core innovations: (1) a divide-and-conquer fully parallel architecture that decomposes user queries into hierarchical task forest structures enabling dependency management and distributed concurrent processing. (2) an adaptive collaboration engine that dynamically selects heterogeneous LLM combinations and interaction modes based on task characteristics. (3) agent organization optimization strategies combining divide-and-conquer approaches for efficient problem decomposition. Extensive experiments demonstrate AgentGroupChat-V2's superior performance across diverse domains, achieving 91.50% accuracy on GSM8K (exceeding the best baseline by 5.6 percentage points), 30.4% accuracy on competition-level AIME (nearly doubling other methods), and 79.20% pass@1 on HumanEval. Performance advantages become increasingly pronounced with higher task difficulty, particularly on Level 5 MATH problems where improvements exceed 11 percentage points compared to state-of-the-art baselines. These results confirm that AgentGroupChat-V2 provides a comprehensive solution for building efficient, general-purpose LLM multi-agent systems with significant advantages in complex reasoning scenarios. Code is available at https://github.com/MikeGu721/AgentGroupChat-V2.
RECKON: Large-scale Reference-based Efficient Knowledge Evaluation for Large Language Model
Apr 01, 2025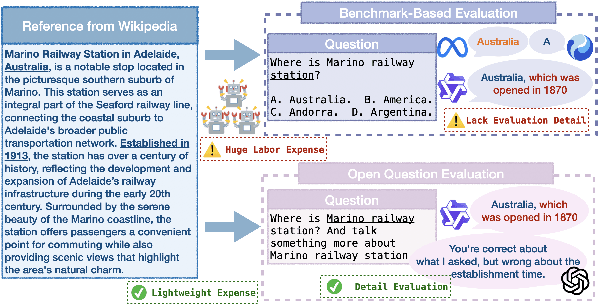
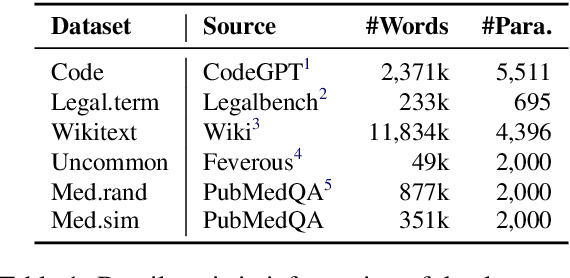
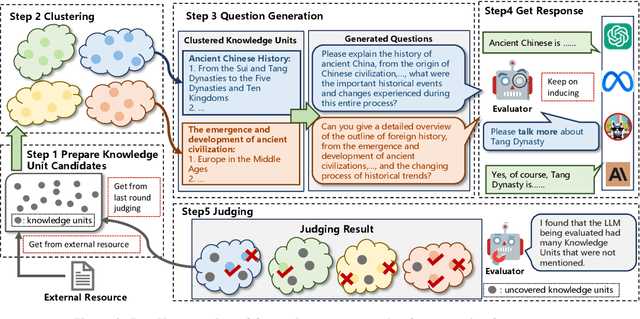
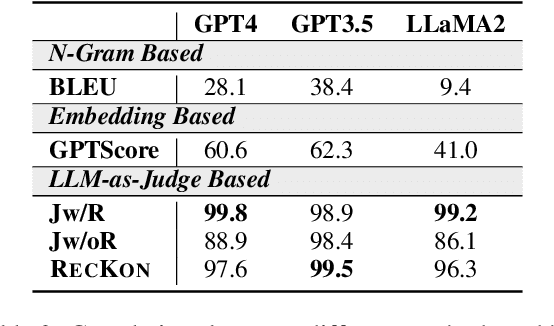
As large language models (LLMs) advance, efficient knowledge evaluation becomes crucial to verifying their capabilities. Traditional methods, relying on benchmarks, face limitations such as high resource costs and information loss. We propose the Large-scale Reference-based Efficient Knowledge Evaluation for Large Language Model (RECKON), which directly uses reference data to evaluate models. RECKON organizes unstructured data into manageable units and generates targeted questions for each cluster, improving evaluation accuracy and efficiency. Experimental results show that RECKON reduces resource consumption by 56.5% compared to traditional methods while achieving over 97% accuracy across various domains, including world knowledge, code, legal, and biomedical datasets. Code is available at https://github.com/MikeGu721/reckon
GAPO: Learning Preferential Prompt through Generative Adversarial Policy Optimization
Mar 26, 2025Recent advances in large language models have highlighted the critical need for precise control over model outputs through predefined constraints. While existing methods attempt to achieve this through either direct instruction-response synthesis or preferential response optimization, they often struggle with constraint understanding and adaptation. This limitation becomes particularly evident when handling fine-grained constraints, leading to either hallucination or brittle performance. We introduce Generative Adversarial Policy Optimization (GAPO), a novel framework that combines GAN-based training dynamics with an encoder-only reward model to progressively learn and adapt to increasingly complex constraints. GAPO leverages adversarial training to automatically generate training samples of varying difficulty while utilizing the encoder-only architecture to better capture prompt-response relationships. Extensive experiments demonstrate GAPO's superior performance across multiple benchmarks, particularly in scenarios requiring fine-grained constraint handling, where it significantly outperforms existing methods like PPO, DPO, and KTO. Our results suggest that GAPO's unique approach to preferential prompt learning offers a more robust and effective solution for controlling LLM outputs. Code is avaliable in https://github.com/MikeGu721/GAPO.
An Evidential-enhanced Tri-Branch Consistency Learning Method for Semi-supervised Medical Image Segmentation
Apr 10, 2024Semi-supervised segmentation presents a promising approach for large-scale medical image analysis, effectively reducing annotation burdens while achieving comparable performance. This methodology holds substantial potential for streamlining the segmentation process and enhancing its feasibility within clinical settings for translational investigations. While cross-supervised training, based on distinct co-training sub-networks, has become a prevalent paradigm for this task, addressing critical issues such as predication disagreement and label-noise suppression requires further attention and progress in cross-supervised training. In this paper, we introduce an Evidential Tri-Branch Consistency learning framework (ETC-Net) for semi-supervised medical image segmentation. ETC-Net employs three branches: an evidential conservative branch, an evidential progressive branch, and an evidential fusion branch. The first two branches exhibit complementary characteristics, allowing them to address prediction diversity and enhance training stability. We also integrate uncertainty estimation from the evidential learning into cross-supervised training, mitigating the negative impact of erroneous supervision signals. Additionally, the evidential fusion branch capitalizes on the complementary attributes of the first two branches and leverages an evidence-based Dempster-Shafer fusion strategy, supervised by more reliable and accurate pseudo-labels of unlabeled data. Extensive experiments conducted on LA, Pancreas-CT, and ACDC datasets demonstrate that ETC-Net surpasses other state-of-the-art methods for semi-supervised segmentation. The code will be made available in the near future at https://github.com/Medsemiseg.