 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-Aware Concept and Motion Segmentation for Semi-Supervised Angiography Videos
Mar 01, 2026Segmentation of the main coronary artery from X-ray coronary angiography (XCA) sequences is crucial for the diagnosis of coronary artery diseases. However, this task is challenging due to issues such as blurred boundaries, inconsistent radiation contrast, complex motion patterns, and a lack of annotated images for training. Although Semi-Supervised Learning (SSL) can alleviate the annotation burden, conventional methods struggle with complicated temporal dynamics and unreliable uncertainty quantification. To address these challenges, we propose SAM3-based Teacher-student framework with Motion-Aware consistency and Progressive Confidence Regularization (SMART), a semi-supervised vessel segmentation approach for X-ray angiography videos. First, our method utilizes SAM3's unique promptable concept segmentation design and innovates a SAM3-based teacher-student framework to maximize the performance potential of both the teacher and the student. Second, we enhance segmentation by integrating the vessel mask warping technique and motion consistency loss to model complex vessel dynamics. To address the issue of unreliable teacher predictions caused by blurred boundaries and minimal contrast, we further propose a progressive confidence-aware consistency regularization to mitigate the risk of unreliable outputs. Extensive experiments on three datasets of XCA sequences from different institutions demonstrate that SMART achieves state-of-the-art performance while requiring significantly fewer annotations, making it particularly valuable for real-world clinical applications where labeled data is scarce. Our code is available at: https://github.com/qimingfan10/SMART.
Spherical Latent Motion Prior for Physics-Based Simulated Humanoid Control
Mar 01, 2026Learning motion priors for physics-based humanoid control is an active research topic. Existing approaches mainly include variational autoencoders (VAE) and adversarial motion priors (AMP). VAE introduces information loss, and random latent sampling may sometimes produce invalid behaviors. AMP suffers from mode collapse and struggles to capture diverse motion skills. We present the Spherical Latent Motion Prior (SLMP), a two-stage method for learning motion priors. In the first stage, we train a high-quality motion tracking controller. In the second stage, we distill the tracking controller into a spherical latent space. A combination of distillation, a discriminator, and a discriminator-guided local semantic consistency constraint shapes a structured latent action space, allowing stable random sampling without information loss. To evaluate SLMP, we collect a two-hour human combat motion capture dataset and show that SLMP preserves fine motion detail without information loss, and random sampling yields semantically valid and stable behaviors. When applied to a two-agent physics-based combat task, SLMP produces human-like and physically plausible combat behaviors only using simple rule-based rewards. Furthermore, SLMP generalizes across different humanoid robot morphologies, demonstrating its transferability beyond a single simulated avatar.
Iterative Closed-Loop Motion Synthesis for Scaling the Capabilities of Humanoid Control
Feb 25, 2026Physics-based humanoid control relies on training with motion datasets that have diverse data distributions. However, the fixed difficulty distribution of datasets limits the performance ceiling of the trained control policies. Additionally, the method of acquiring high-quality data through professional motion capture systems is constrained by costs, making it difficult to achieve large-scale scalability. To address these issues, we propose a closed-loop automated motion data generation and iterative framework. It can generate high-quality motion data with rich action semantics, including martial arts, dance, combat, sports, gymnastics, and more. Furthermore, our framework enables difficulty iteration of policies and data through physical metrics and objective evaluations, allowing the trained tracker to break through its original difficulty limits. On the PHC single-primitive tracker, using only approximately 1/10 of the AMASS dataset size, the average failure rate on the test set (2201 clips) is reduced by 45\% compared to the baseline. Finally, we conduct comprehensive ablation and comparative experiments to highlight the rationality and advantages of our framework.
FaultDiffusion: Few-Shot Fault Time Series Generation with Diffusion Model
Nov 19, 2025In industrial equipment monitoring, fault diagnosis is critical for ensuring system reliability and enabling predictive maintenance. However, the scarcity of fault data, due to the rarity of fault events and the high cost of data annotation, significantly hinders data-driven approaches. Existing time-series generation models, optimized for abundant normal data, struggle to capture fault distributions in few-shot scenarios, producing samples that lack authenticity and diversity due to the large domain gap and high intra-class variability of faults. To address this, we propose a novel few-shot fault time-series generation framework based on diffusion models. Our approach employs a positive-negative difference adapter, leveraging pre-trained normal data distributions to model the discrepancies between normal and fault domains for accurate fault synthesis. Additionally, a diversity loss is introduced to prevent mode collapse, encouraging the generation of diverse fault samples through inter-sample difference regularization. Experimental results demonstrate that our model significantly outperforms traditional methods in authenticity and diversity, achieving state-of-the-art performance on key benchmarks.
FARM: Frame-Accelerated Augmentation and Residual Mixture-of-Experts for Physics-Based High-Dynamic Humanoid Control
Aug 27, 2025Unified physics-based humanoid controllers are pivotal for robotics and character animation, yet models that excel on gentle, everyday motions still stumble on explosive actions, hampering real-world deployment. We bridge this gap with FARM (Frame-Accelerated Augmentation and Residual Mixture-of-Experts), an end-to-end framework composed of frame-accelerated augmentation, a robust base controller, and a residual mixture-of-experts (MoE). Frame-accelerated augmentation exposes the model to high-velocity pose changes by widening inter-frame gaps. The base controller reliably tracks everyday low-dynamic motions, while the residual MoE adaptively allocates additional network capacity to handle challenging high-dynamic actions, significantly enhancing tracking accuracy. In the absence of a public benchmark, we curate the High-Dynamic Humanoid Motion (HDHM) dataset, comprising 3593 physically plausible clips. On HDHM, FARM reduces the tracking failure rate by 42.8\% and lowers global mean per-joint position error by 14.6\% relative to the baseline, while preserving near-perfect accuracy on low-dynamic motions. These results establish FARM as a new baseline for high-dynamic humanoid control and introduce the first open benchmark dedicated to this challenge. The code and dataset will be released at https://github.com/Colin-Jing/FARM.
Statistical Parameterized Physics-Based Machine Learning Digital Twin Models for Laser Powder Bed Fusion Process
Nov 14, 2023



A digital twin (DT) is a virtual representation of physical process, products and/or systems that requires a high-fidelity computational model for continuous update through the integration of sensor data and user input. In the context of laser powder bed fusion (LPBF) additive manufacturing, a digital twin of the manufacturing process can offer predictions for the produced parts, diagnostics for manufacturing defects, as well as control capabilities. This paper introduces a parameterized physics-based digital twin (PPB-DT) for the statistical predictions of LPBF metal additive manufacturing process. We accomplish this by creating a high-fidelity computational model that accurately represents the melt pool phenomena and subsequently calibrating and validating it through controlled experiments. In PPB-DT, a mechanistic reduced-order method-driven stochastic calibration process is introduced, which enables the statistical predictions of the melt pool geometries and the identification of defects such as lack-of-fusion porosity and surface roughness, specifically for diagnostic applications. Leveraging data derived from this physics-based model and experiments, we have trained a machine learning-based digital twin (PPB-ML-DT) model for predicting, monitoring, and controlling melt pool geometries. These proposed digital twin models can be employed for predictions, control, optimization, and quality assurance within the LPBF process, ultimately expediting product development and certification in LPBF-based metal additive manufacturing.
Emergence of Shape Bias in Convolutional Neural Networks through Activation Sparsity
Oct 29, 2023



Current deep-learning models for object recognition are known to be heavily biased toward texture. In contrast, human visual systems are known to be biased toward shape and structure. What could be the design principles in human visual systems that led to this difference? How could we introduce more shape bias into the deep learning models? In this paper, we report that sparse coding, a ubiquitous principle in the brain, can in itself introduce shape bias into the network. We found that enforcing the sparse coding constraint using a non-differential Top-K operation can lead to the emergence of structural encoding in neurons in convolutional neural networks, resulting in a smooth decomposition of objects into parts and subparts and endowing the networks with shape bias. We demonstrated this emergence of shape bias and its functional benefits for different network structures with various datasets. For object recognition convolutional neural networks, the shape bias leads to greater robustness against style and pattern change distraction. For the image synthesis generative adversary networks, the emerged shape bias leads to more coherent and decomposable structures in the synthesized images. Ablation studies suggest that sparse codes tend to encode structures, whereas the more distributed codes tend to favor texture. Our code is host at the github repository: \url{https://github.com/Crazy-Jack/nips2023_shape_vs_texture}
A Hierarchical Deep Convolutional Neural Network and Gated Recurrent Unit Framework for Structural Damage Detection
May 29, 2020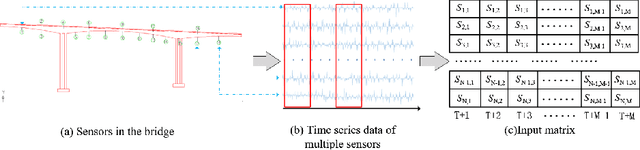

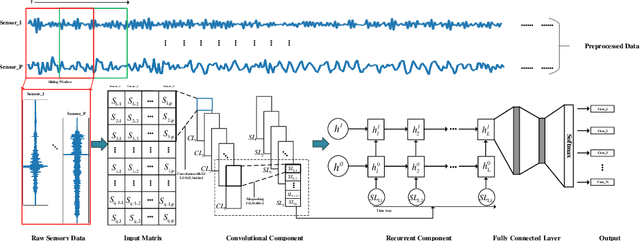

Structural damage detection has become an interdisciplinary area of interest for various engineering fields, while the available damage detection methods are being in the process of adapting machine learning concepts. Most machine learning based methods heavily depend on extracted ``hand-crafted" features that are manually selected in advance by domain experts and then, fixed. Recently, deep learning has demonstrated remarkable performance on traditional challenging tasks, such as image classification, object detection, etc., due to the powerful feature learning capabilities. This breakthrough has inspired researchers to explore deep learning techniques for structural damage detection problems. However, existing methods have considered either spatial relation (e.g., using convolutional neural network (CNN)) or temporal relation (e.g., using long short term memory network (LSTM)) only. In this work, we propose a novel Hierarchical CNN and Gated recurrent unit (GRU) framework to model both spatial and temporal relations, termed as HCG, for structural damage detection. Specifically, CNN is utilized to model the spatial relations and the short-term temporal dependencies among sensors, while the output features of CNN are fed into the GRU to learn the long-term temporal dependencies jointly. Extensive experiments on IASC-ASCE structural health monitoring benchmark and scale model of three-span continuous rigid frame bridge structure datasets have shown that our proposed HCG outperforms other existing methods for structural damage detection significantly.