 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Limits Vision-and-Language Navigation ?
May 13, 2026Vision-and-Language Navigation (VLN) is a cornerstone of embodied intelligence. However, current agents often suffer from significant performance degradation when transitioning from simulation to real-world deployment, primarily due to perceptual instability (e.g., lighting variations and motion blur) and under-specified instructions. While existing methods attempt to bridge this gap by scaling up model size and training data, we argue that the bottleneck lies in the lack of robust spatial grounding and cross-domain priors. In this paper, we propose StereoNav, a robust Vision-Language-Action framework designed to enhance real-world navigation consistency. To address the inherent gap between synthetic training and physical execution, we introduce Target-Location Priors as a persistent bridge. These priors provide stable visual guidance that remains invariant across domains, effectively grounding the agent even when instructions are vague. Furthermore, to mitigate visual disturbances like motion blur and illumination shifts, StereoNav leverages stereo vision to construct a unified representation of semantics and geometry, enabling precise action prediction through enhanced depth awareness. Extensive experiments on R2R-CE and RxR-CE demonstrate that StereoNav achieves state-of-the-art egocentric RGB performance, with SR and SPL scores of 81.1% and 68.3%, and 67.5% and 52.0%, respectively, while using significantly fewer parameters and less training data than prior scaling-based approaches. More importantly, real-world robotic deployments confirm that StereoNav substantially improves navigation reliability in complex, unstructured environments. Project page: https://yunheng-wang.github.io/stereonav-public.github.io.
Morphology-Consistent Humanoid Interaction through Robot-Centric Video Synthesis
Mar 20, 2026Equipping humanoid robots with versatile interaction skills typically requires either extensive policy training or explicit human-to-robot motion retargeting. However, learning-based policies face prohibitive data collection costs. Meanwhile, retargeting relies on human-centric pose estimation (e.g., SMPL), introducing a morphology gap. Skeletal scale mismatches result in severe spatial misalignments when mapped to robots, compromising interaction success. In this work, we propose Dream2Act, a robot-centric framework enabling zero-shot interaction through generative video synthesis. Given a third-person image of the robot and target object, our framework leverages video generation models to envision the robot completing the task with morphology-consistent motion. We employ a high-fidelity pose extraction system to recover physically feasible, robot-native joint trajectories from these synthesized dreams, subsequently executed via a general-purpose whole-body controller. Operating strictly within the robot-native coordinate space, Dream2Act avoids retargeting errors and eliminates task-specific policy training. We evaluate Dream2Act on the Unitree G1 across four whole-body mobile interaction tasks: ball kicking, sofa sitting, bag punching, and box hugging. Dream2Act achieves a 37.5% overall success rate, compared to 0% for conventional retargeting. While retargeting fails to establish correct physical contacts due to the morphology gap (with errors compounded during locomotion), Dream2Act maintains robot-consistent spatial alignment, enabling reliable contact formation and substantially higher task completion.
UniGround: Universal 3D Visual Grounding via Training-Free Scene Parsing
Mar 09, 2026Understanding and localizing objects in complex 3D environments from natural language descriptions, known as 3D Visual Grounding (3DVG), is a foundational challenge in embodied AI, with broad implications for robotics, augmented reality, and human-machine interaction. Large-scale pre-trained foundation models have driven significant progress on this front, enabling open-vocabulary 3DVG that allows systems to locate arbitrary objects in a given scene. However, their reliance on pre-trained models constrains 3D perception and reasoning within the inherited knowledge boundaries, resulting in limited generalization to unseen spatial relationships and poor robustness to out-of-distribution scenes. In this paper, we replace this constrained perception with training-free visual and geometric reasoning, thereby unlocking open-world 3DVG that enables the localization of any object in any scene beyond the training data. Specifically, the proposed UniGround operates in two stages: a Global Candidate Filtering stage that constructs scene candidates through training-free 3D topology and multi-view semantic encoding, and a Local Precision Grounding stage that leverages multi-scale visual prompting and structured reasoning to precisely identify the target object. Experiments on ScanRefer and EmbodiedScan show that UniGround achieves 46.1\%/34.1\% Acc@0.25/0.5 on ScanRefer and 28.7\% Acc@0.25 on EmbodiedScan, establishing a new state-of-the-art among zero-shot methods on EmbodiedScan without any 3D supervision. We further evaluate UniGround in real-world environments under uncontrolled reconstruction conditions and substantial domain shift, showing training-free reasoning generalizes robustly beyond curated benchmarks.
Spherical Latent Motion Prior for Physics-Based Simulated Humanoid Control
Mar 01, 2026Learning motion priors for physics-based humanoid control is an active research topic. Existing approaches mainly include variational autoencoders (VAE) and adversarial motion priors (AMP). VAE introduces information loss, and random latent sampling may sometimes produce invalid behaviors. AMP suffers from mode collapse and struggles to capture diverse motion skills. We present the Spherical Latent Motion Prior (SLMP), a two-stage method for learning motion priors. In the first stage, we train a high-quality motion tracking controller. In the second stage, we distill the tracking controller into a spherical latent space. A combination of distillation, a discriminator, and a discriminator-guided local semantic consistency constraint shapes a structured latent action space, allowing stable random sampling without information loss. To evaluate SLMP, we collect a two-hour human combat motion capture dataset and show that SLMP preserves fine motion detail without information loss, and random sampling yields semantically valid and stable behaviors. When applied to a two-agent physics-based combat task, SLMP produces human-like and physically plausible combat behaviors only using simple rule-based rewards. Furthermore, SLMP generalizes across different humanoid robot morphologies, demonstrating its transferability beyond a single simulated avatar.
Iterative Closed-Loop Motion Synthesis for Scaling the Capabilities of Humanoid Control
Feb 25, 2026Physics-based humanoid control relies on training with motion datasets that have diverse data distributions. However, the fixed difficulty distribution of datasets limits the performance ceiling of the trained control policies. Additionally, the method of acquiring high-quality data through professional motion capture systems is constrained by costs, making it difficult to achieve large-scale scalability. To address these issues, we propose a closed-loop automated motion data generation and iterative framework. It can generate high-quality motion data with rich action semantics, including martial arts, dance, combat, sports, gymnastics, and more. Furthermore, our framework enables difficulty iteration of policies and data through physical metrics and objective evaluations, allowing the trained tracker to break through its original difficulty limits. On the PHC single-primitive tracker, using only approximately 1/10 of the AMASS dataset size, the average failure rate on the test set (2201 clips) is reduced by 45\% compared to the baseline. Finally, we conduct comprehensive ablation and comparative experiments to highlight the rationality and advantages of our framework.
VerilogReader: LLM-Aided Hardware Test Generation
Jun 03, 2024Test generation has been a critical and labor-intensive process in hardware design verification. Recently, the emergence of Large Language Model (LLM) with their advanced understanding and inference capabilities, has introduced a novel approach. In this work, we investigate the integration of LLM into the Coverage Directed Test Generation (CDG) process, where the LLM functions as a Verilog Reader. It accurately grasps the code logic, thereby generating stimuli that can reach unexplored code branches. We compare our framework with random testing, using our self-designed Verilog benchmark suite. Experiments demonstrate that our framework outperforms random testing on designs within the LLM's comprehension scope. Our work also proposes prompt engineering optimizations to augment LLM's understanding scope and accuracy.
Adaptive Reconvergence-driven AIG Rewriting via Strategy Learning
Dec 22, 2023



Rewriting is a common procedure in logic synthesis aimed at improving the performance, power, and area (PPA) of circuits. The traditional reconvergence-driven And-Inverter Graph (AIG) rewriting method focuses solely on optimizing the reconvergence cone through Boolean algebra minimization. However, there exist opportunities to incorporate other node-rewriting algorithms that are better suited for specific cones. In this paper, we propose an adaptive reconvergence-driven AIG rewriting algorithm that combines two key techniques: multi-strategy-based AIG rewriting and strategy learning-based algorithm selection. The multi-strategy-based rewriting method expands upon the traditional approach by incorporating support for multi-node-rewriting algorithms, thus expanding the optimization space. Additionally, the strategy learning-based algorithm selection method determines the most suitable node-rewriting algorithm for a given cone. Experimental results demonstrate that our proposed method yields a significant average improvement of 5.567\% in size and 5.327\% in depth.
Fast Exact NPN Classification with Influence-aided Canonical Form
Aug 23, 2023



NPN classification has many applications in the synthesis and verification of digital circuits. The canonical-form-based method is the most common approach, designing a canonical form as representative for the NPN equivalence class first and then computing the transformation function according to the canonical form. Most works use variable symmetries and several signatures, mainly based on the cofactor, to simplify the canonical form construction and computation. This paper describes a novel canonical form and its computation algorithm by introducing Boolean influence to NPN classification, which is a basic concept in analysis of Boolean functions. We show that influence is input-negation-independent, input-permutation-dependent, and has other structural information than previous signatures for NPN classification. Therefore, it is a significant ingredient in speeding up NPN classification. Experimental results prove that influence plays an important role in reducing the transformation enumeration in computing the canonical form. Compared with the state-of-the-art algorithm implemented in ABC, our influence-aided canonical form for exact NPN classification gains up to 5.5x speedup.
$Radar^2$: Passive Spy Radar Detection and Localization using COTS mmWave Radar
Jan 10, 2022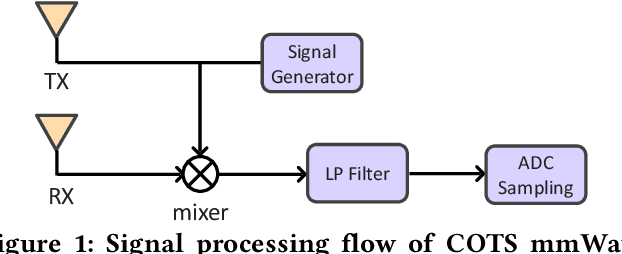
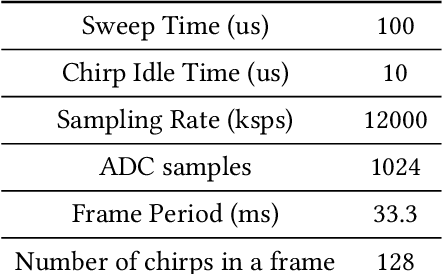
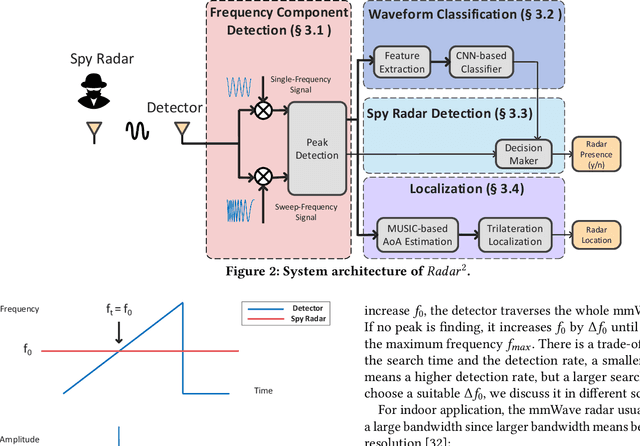
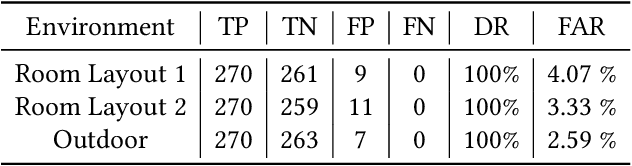
Millimeter-wave (mmWave) radars have found applications in a wide range of domains, including human tracking, health monitoring, and autonomous driving, for its unobtrusive nature and high range accuracy. These capabilities, however, if used for malicious purposes, could also lead to serious security and privacy issues. For example, a user's daily life could be secretly monitored by a spy radar. Hence, there is a strong urge to develop systems that can detect and localize such spy radars. In this paper, we propose $Radar^2$, a practical passive spy radar detection and localization system using a single commercial off-the-shelf (COTS) mmWave radar. Specifically, we propose a novel \textit{Frequency Component Detection} method to detect the existence of mmWave signal, distinguish between mmWave radar and WiGig signals using a convolutional neural network (CNN) based waveform classifier, and localize spy radars using the trilateration method based on the detector's observations at multiple anchor points. Not only does $Radar^2$ work for different types of mmWave radar, but it can also detect and localize multiple radars simultaneously. Finally, we perform extensive experiments to evaluate the effectiveness and robustness of $Radar^2$ in various settings. Our evaluation shows that the radar detection rate is constantly above 96$\%$ and the localization error is within 0.3m. The results also reveal that $Radar^2$ is robust against various factors (room layout, human activities, etc.).
Enhanced Fast Boolean Matching based on Sensitivity Signatures Pruning
Nov 11, 2021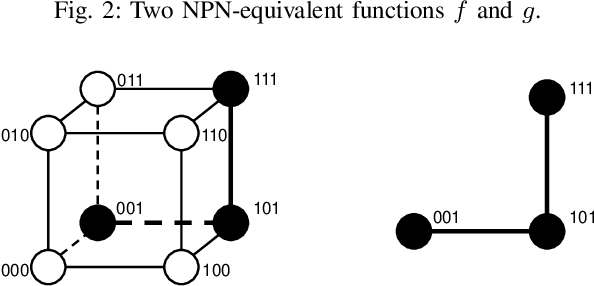
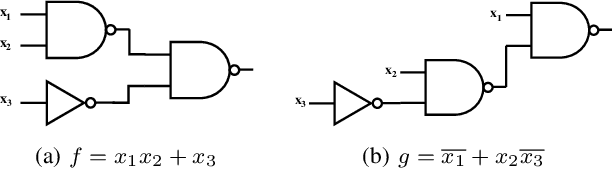
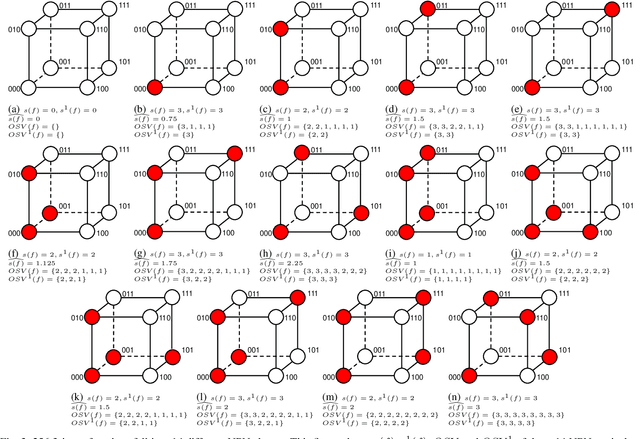
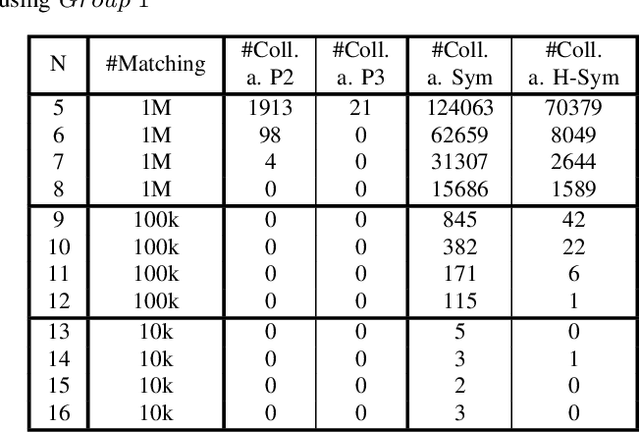
Boolean matching is significant to digital integrated circuits design. An exhaustive method for Boolean matching is computationally expensive even for functions with only a few variables, because the time complexity of such an algorithm for an n-variable Boolean function is $O(2^{n+1}n!)$. Sensitivity is an important characteristic and a measure of the complexity of Boolean functions. It has been used in analysis of the complexity of algorithms in different fields. This measure could be regarded as a signature of Boolean functions and has great potential to help reduce the search space of Boolean matching. In this paper, we introduce Boolean sensitivity into Boolean matching and design several sensitivity-related signatures to enhance fast Boolean matching. First, we propose some new signatures that relate sensitivity to Boolean equivalence. Then, we prove that these signatures are prerequisites for Boolean matching, which we can use to reduce the search space of the matching problem. Besides, we develop a fast sensitivity calculation method to compute and compare these signatures of two Boolean functions. Compared with the traditional cofactor and symmetric detection methods, sensitivity is a series of signatures of another dimension. We also show that sensitivity can be easily integrated into traditional methods and distinguish the mismatched Boolean functions faster. To the best of our knowledge, this is the first work that introduces sensitivity to Boolean matching. The experimental results show that sensitivity-related signatures we proposed in this paper can reduce the search space to a very large extent, and perform up to 3x speedup over the state-of-the-art Boolean matching methods.