 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIterative Closed-Loop Motion Synthesis for Scaling the Capabilities of Humanoid Control
Feb 25, 2026Physics-based humanoid control relies on training with motion datasets that have diverse data distributions. However, the fixed difficulty distribution of datasets limits the performance ceiling of the trained control policies. Additionally, the method of acquiring high-quality data through professional motion capture systems is constrained by costs, making it difficult to achieve large-scale scalability. To address these issues, we propose a closed-loop automated motion data generation and iterative framework. It can generate high-quality motion data with rich action semantics, including martial arts, dance, combat, sports, gymnastics, and more. Furthermore, our framework enables difficulty iteration of policies and data through physical metrics and objective evaluations, allowing the trained tracker to break through its original difficulty limits. On the PHC single-primitive tracker, using only approximately 1/10 of the AMASS dataset size, the average failure rate on the test set (2201 clips) is reduced by 45\% compared to the baseline. Finally, we conduct comprehensive ablation and comparative experiments to highlight the rationality and advantages of our framework.
T2MBench: A Benchmark for Out-of-Distribution Text-to-Motion Generation
Feb 14, 2026Most existing evaluations of text-to-motion generation focus on in-distribution textual inputs and a limited set of evaluation criteria, which restricts their ability to systematically assess model generalization and motion generation capabilities under complex out-of-distribution (OOD) textual conditions. To address this limitation, we propose a benchmark specifically designed for OOD text-to-motion evaluation, which includes a comprehensive analysis of 14 representative baseline models and the two datasets derived from evaluation results. Specifically, we construct an OOD prompt dataset consisting of 1,025 textual descriptions. Based on this prompt dataset, we introduce a unified evaluation framework that integrates LLM-based Evaluation, Multi-factor Motion evaluation, and Fine-grained Accuracy Evaluation. Our experimental results reveal that while different baseline models demonstrate strengths in areas such as text-to-motion semantic alignment, motion generalizability, and physical quality, most models struggle to achieve strong performance with Fine-grained Accuracy Evaluation. These findings highlight the limitations of existing methods in OOD scenarios and offer practical guidance for the design and evaluation of future production-level text-to-motion models.
Training Video Foundation Models with NVIDIA NeMo
Mar 17, 2025Video Foundation Models (VFMs) have recently been used to simulate the real world to train physical AI systems and develop creative visual experiences. However, there are significant challenges in training large-scale, high quality VFMs that can generate high-quality videos. We present a scalable, open-source VFM training pipeline with NVIDIA NeMo, providing accelerated video dataset curation, multimodal data loading, and parallelized video diffusion model training and inference. We also provide a comprehensive performance analysis highlighting best practices for efficient VFM training and inference.
Out-of-Core GPU Gradient Boosting
May 19, 2020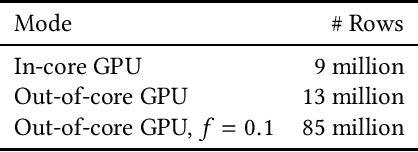
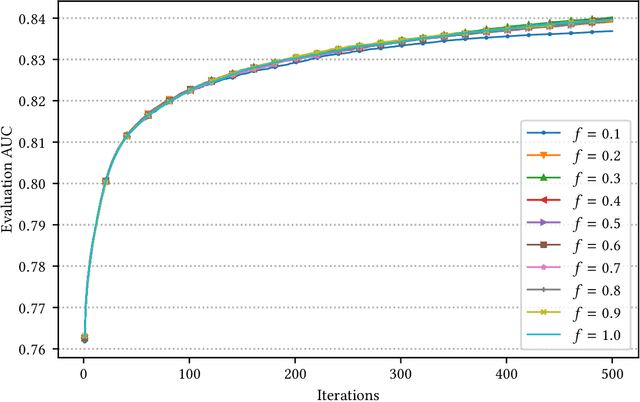
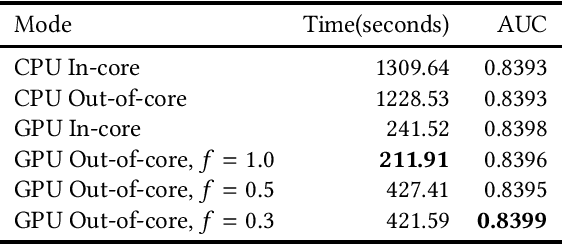
GPU-based algorithms have greatly accelerated many machine learning methods; however, GPU memory is typically smaller than main memory, limiting the size of training data. In this paper, we describe an out-of-core GPU gradient boosting algorithm implemented in the XGBoost library. We show that much larger datasets can fit on a given GPU, without degrading model accuracy or training time. To the best of our knowledge, this is the first out-of-core GPU implementation of gradient boosting. Similar approaches can be applied to other machine learning algorithms