 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBagelVLA: Enhancing Long-Horizon Manipulation via Interleaved Vision-Language-Action Generation
Feb 11, 2026Equipping embodied agents with the ability to reason about tasks, foresee physical outcomes, and generate precise actions is essential for general-purpose manipulation. While recent Vision-Language-Action (VLA) models have leveraged pre-trained foundation models, they typically focus on either linguistic planning or visual forecasting in isolation. These methods rarely integrate both capabilities simultaneously to guide action generation, leading to suboptimal performance in complex, long-horizon manipulation tasks. To bridge this gap, we propose BagelVLA, a unified model that integrates linguistic planning, visual forecasting, and action generation within a single framework. Initialized from a pretrained unified understanding and generative model, BagelVLA is trained to interleave textual reasoning and visual prediction directly into the action execution loop. To efficiently couple these modalities, we introduce Residual Flow Guidance (RFG), which initializes from current observation and leverages single-step denoising to extract predictive visual features, guiding action generation with minimal latency. Extensive experiments demonstrate that BagelVLA outperforms existing baselines by a significant margin on multiple simulated and real-world benchmarks, particularly in tasks requiring multi-stage reasoning.
VLingNav: Embodied Navigation with Adaptive Reasoning and Visual-Assisted Linguistic Memory
Jan 13, 2026VLA models have shown promising potential in embodied navigation by unifying perception and planning while inheriting the strong generalization abilities of large VLMs. However, most existing VLA models rely on reactive mappings directly from observations to actions, lacking the explicit reasoning capabilities and persistent memory required for complex, long-horizon navigation tasks. To address these challenges, we propose VLingNav, a VLA model for embodied navigation grounded in linguistic-driven cognition. First, inspired by the dual-process theory of human cognition, we introduce an adaptive chain-of-thought mechanism, which dynamically triggers explicit reasoning only when necessary, enabling the agent to fluidly switch between fast, intuitive execution and slow, deliberate planning. Second, to handle long-horizon spatial dependencies, we develop a visual-assisted linguistic memory module that constructs a persistent, cross-modal semantic memory, enabling the agent to recall past observations to prevent repetitive exploration and infer movement trends for dynamic environments. For the training recipe, we construct Nav-AdaCoT-2.9M, the largest embodied navigation dataset with reasoning annotations to date, enriched with adaptive CoT annotations that induce a reasoning paradigm capable of adjusting both when to think and what to think about. Moreover, we incorporate an online expert-guided reinforcement learning stage, enabling the model to surpass pure imitation learning and to acquire more robust, self-explored navigation behaviors. Extensive experiments demonstrate that VLingNav achieves state-of-the-art performance across a wide range of embodied navigation benchmarks. Notably, VLingNav transfers to real-world robotic platforms in a zero-shot manner, executing various navigation tasks and demonstrating strong cross-domain and cross-task generalization.
UniUGP: Unifying Understanding, Generation, and Planing For End-to-end Autonomous Driving
Dec 10, 2025Autonomous driving (AD) systems struggle in long-tail scenarios due to limited world knowledge and weak visual dynamic modeling. Existing vision-language-action (VLA)-based methods cannot leverage unlabeled videos for visual causal learning, while world model-based methods lack reasoning capabilities from large language models. In this paper, we construct multiple specialized datasets providing reasoning and planning annotations for complex scenarios. Then, a unified Understanding-Generation-Planning framework, named UniUGP, is proposed to synergize scene reasoning, future video generation, and trajectory planning through a hybrid expert architecture. By integrating pre-trained VLMs and video generation models, UniUGP leverages visual dynamics and semantic reasoning to enhance planning performance. Taking multi-frame observations and language instructions as input, it produces interpretable chain-of-thought reasoning, physically consistent trajectories, and coherent future videos. We introduce a four-stage training strategy that progressively builds these capabilities across multiple existing AD datasets, along with the proposed specialized datasets. Experiments demonstrate state-of-the-art performance in perception, reasoning, and decision-making, with superior generalization to challenging long-tail situations.
Learning Vision-Driven Reactive Soccer Skills for Humanoid Robots
Nov 06, 2025Humanoid soccer poses a representative challenge for embodied intelligence, requiring robots to operate within a tightly coupled perception-action loop. However, existing systems typically rely on decoupled modules, resulting in delayed responses and incoherent behaviors in dynamic environments, while real-world perceptual limitations further exacerbate these issues. In this work, we present a unified reinforcement learning-based controller that enables humanoid robots to acquire reactive soccer skills through the direct integration of visual perception and motion control. Our approach extends Adversarial Motion Priors to perceptual settings in real-world dynamic environments, bridging motion imitation and visually grounded dynamic control. We introduce an encoder-decoder architecture combined with a virtual perception system that models real-world visual characteristics, allowing the policy to recover privileged states from imperfect observations and establish active coordination between perception and action. The resulting controller demonstrates strong reactivity, consistently executing coherent and robust soccer behaviors across various scenarios, including real RoboCup matches.
Astra: Toward General-Purpose Mobile Robots via Hierarchical Multimodal Learning
Jun 06, 2025Modern robot navigation systems encounter difficulties in diverse and complex indoor environments. Traditional approaches rely on multiple modules with small models or rule-based systems and thus lack adaptability to new environments. To address this, we developed Astra, a comprehensive dual-model architecture, Astra-Global and Astra-Local, for mobile robot navigation. Astra-Global, a multimodal LLM, processes vision and language inputs to perform self and goal localization using a hybrid topological-semantic graph as the global map, and outperforms traditional visual place recognition methods. Astra-Local, a multitask network, handles local path planning and odometry estimation. Its 4D spatial-temporal encoder, trained through self-supervised learning, generates robust 4D features for downstream tasks. The planning head utilizes flow matching and a novel masked ESDF loss to minimize collision risks for generating local trajectories, and the odometry head integrates multi-sensor inputs via a transformer encoder to predict the relative pose of the robot. Deployed on real in-house mobile robots, Astra achieves high end-to-end mission success rate across diverse indoor environments.
Model Distillation with Knowledge Transfer from Face Classification to Alignment and Verification
Oct 23, 2017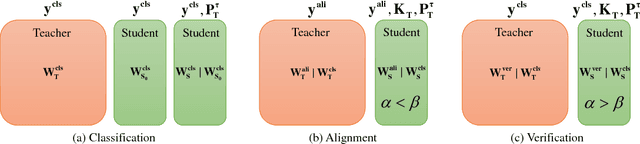
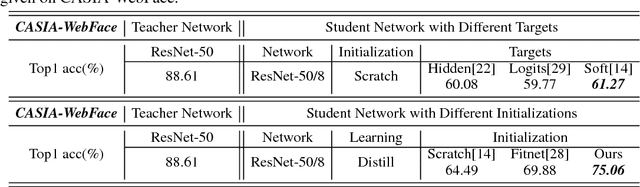
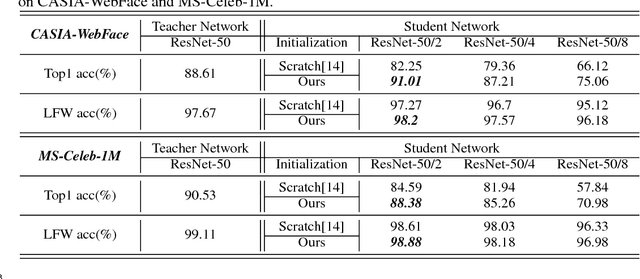

Knowledge distillation is a potential solution for model compression. The idea is to make a small student network imitate the target of a large teacher network, then the student network can be competitive to the teacher one. Most previous studies focus on model distillation in the classification task, where they propose different architects and initializations for the student network. However, only the classification task is not enough, and other related tasks such as regression and retrieval are barely considered. To solve the problem, in this paper, we take face recognition as a breaking point and propose model distillation with knowledge transfer from face classification to alignment and verification. By selecting appropriate initializations and targets in the knowledge transfer, the distillation can be easier in non-classification tasks. Experiments on the CelebA and CASIA-WebFace datasets demonstrate that the student network can be competitive to the teacher one in alignment and verification, and even surpasses the teacher network under specific compression rates. In addition, to achieve stronger knowledge transfer, we also use a common initialization trick to improve the distillation performance of classification. Evaluations on the CASIA-Webface and large-scale MS-Celeb-1M datasets show the effectiveness of this simple trick.