 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Distillation with Knowledge Transfer from Face Classification to Alignment and Verification
Oct 23, 2017
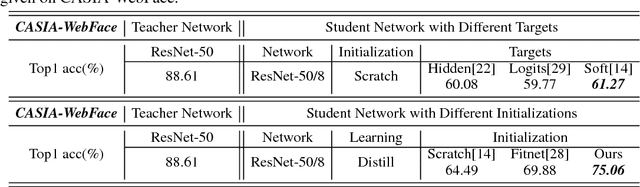
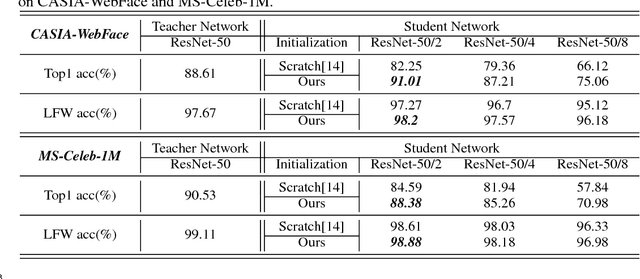

Knowledge distillation is a potential solution for model compression. The idea is to make a small student network imitate the target of a large teacher network, then the student network can be competitive to the teacher one. Most previous studies focus on model distillation in the classification task, where they propose different architects and initializations for the student network. However, only the classification task is not enough, and other related tasks such as regression and retrieval are barely considered. To solve the problem, in this paper, we take face recognition as a breaking point and propose model distillation with knowledge transfer from face classification to alignment and verification. By selecting appropriate initializations and targets in the knowledge transfer, the distillation can be easier in non-classification tasks. Experiments on the CelebA and CASIA-WebFace datasets demonstrate that the student network can be competitive to the teacher one in alignment and verification, and even surpasses the teacher network under specific compression rates. In addition, to achieve stronger knowledge transfer, we also use a common initialization trick to improve the distillation performance of classification. Evaluations on the CASIA-Webface and large-scale MS-Celeb-1M datasets show the effectiveness of this simple trick.
How to Train Triplet Networks with 100K Identities?
Sep 09, 2017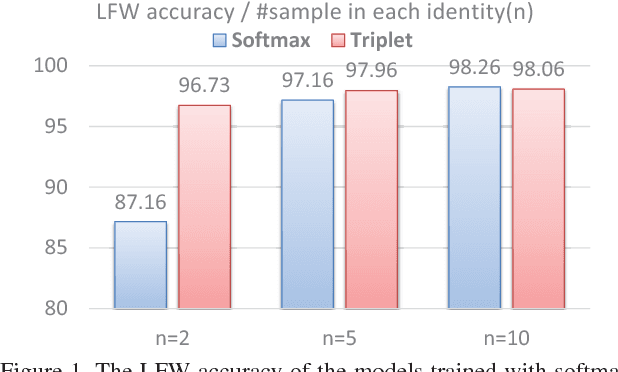
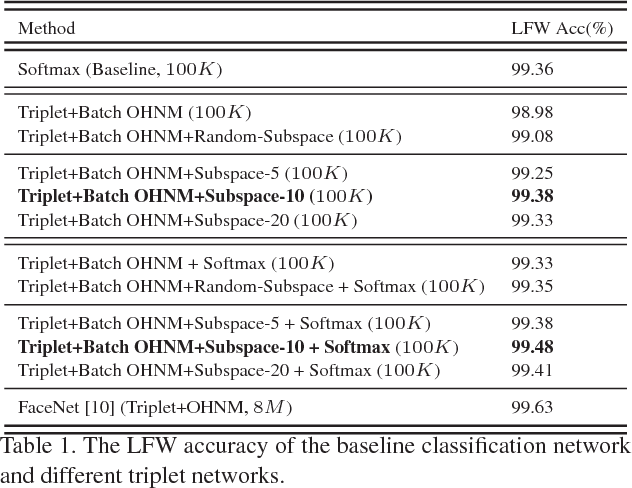
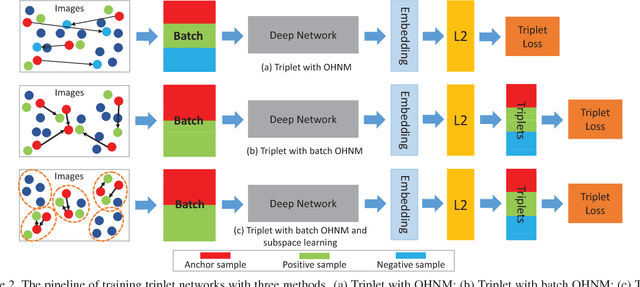
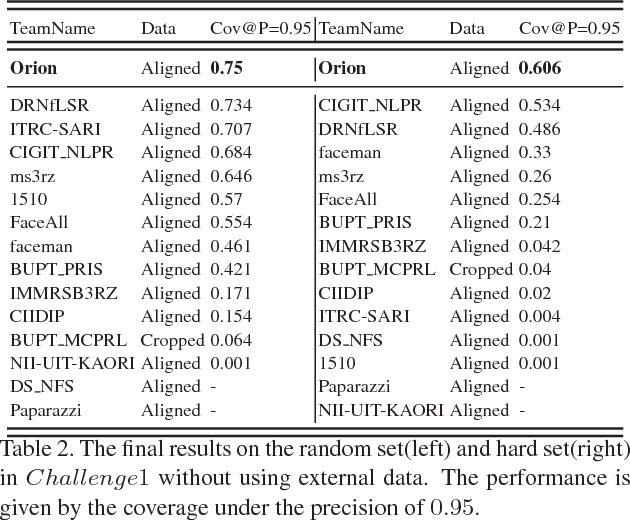
Training triplet networks with large-scale data is challenging in face recognition. Due to the number of possible triplets explodes with the number of samples, previous studies adopt the online hard negative mining(OHNM) to handle it. However, as the number of identities becomes extremely large, the training will suffer from bad local minima because effective hard triplets are difficult to be found. To solve the problem, in this paper, we propose training triplet networks with subspace learning, which splits the space of all identities into subspaces consisting of only similar identities. Combined with the batch OHNM, hard triplets can be found much easier. Experiments on the large-scale MS-Celeb-1M challenge with 100K identities demonstrate that the proposed method can largely improve the performance. In addition, to deal with heavy noise and large-scale retrieval, we also make some efforts on robust noise removing and efficient image retrieval, which are used jointly with the subspace learning to obtain the state-of-the-art performance on the MS-Celeb-1M competition (without external data in Challenge1).