 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupling Skeleton and Flesh: Efficient Multimodal Table Reasoning with Disentangled Alignment and Structure-aware Guidance
Feb 03, 2026Reasoning over table images remains challenging for Large Vision-Language Models (LVLMs) due to complex layouts and tightly coupled structure-content information. Existing solutions often depend on expensive supervised training, reinforcement learning, or external tools, limiting efficiency and scalability. This work addresses a key question: how to adapt LVLMs to table reasoning with minimal annotation and no external tools? Specifically, we first introduce DiSCo, a Disentangled Structure-Content alignment framework that explicitly separates structural abstraction from semantic grounding during multimodal alignment, efficiently adapting LVLMs to tables structures. Building on DiSCo, we further present Table-GLS, a Global-to-Local Structure-guided reasoning framework that performs table reasoning via structured exploration and evidence-grounded inference. Extensive experiments across diverse benchmarks demonstrate that our framework efficiently enhances LVLM's table understanding and reasoning capabilities, particularly generalizing to unseen table structures.
Instruction Anchors: Dissecting the Causal Dynamics of Modality Arbitration
Feb 03, 2026Modality following serves as the capacity of multimodal large language models (MLLMs) to selectively utilize multimodal contexts based on user instructions. It is fundamental to ensuring safety and reliability in real-world deployments. However, the underlying mechanisms governing this decision-making process remain poorly understood. In this paper, we investigate its working mechanism through an information flow lens. Our findings reveal that instruction tokens function as structural anchors for modality arbitration: Shallow attention layers perform non-selective information transfer, routing multimodal cues to these anchors as a latent buffer; Modality competition is resolved within deep attention layers guided by the instruction intent, while MLP layers exhibit semantic inertia, acting as an adversarial force. Furthermore, we identify a sparse set of specialized attention heads that drive this arbitration. Causal interventions demonstrate that manipulating a mere $5\%$ of these critical heads can decrease the modality-following ratio by $60\%$ through blocking, or increase it by $60\%$ through targeted amplification of failed samples. Our work provides a substantial step toward model transparency and offers a principled framework for the orchestration of multimodal information in MLLMs.
VC-Bench: Pioneering the Video Connecting Benchmark with a Dataset and Evaluation Metrics
Jan 27, 2026While current video generation focuses on text or image conditions, practical applications like video editing and vlogging often need to seamlessly connect separate clips. In our work, we introduce Video Connecting, an innovative task that aims to generate smooth intermediate video content between given start and end clips. However, the absence of standardized evaluation benchmarks has hindered the development of this task. To bridge this gap, we proposed VC-Bench, a novel benchmark specifically designed for video connecting. It includes 1,579 high-quality videos collected from public platforms, covering 15 main categories and 72 subcategories to ensure diversity and structure. VC-Bench focuses on three core aspects: Video Quality Score VQS, Start-End Consistency Score SECS, and Transition Smoothness Score TSS. Together, they form a comprehensive framework that moves beyond conventional quality-only metrics. We evaluated multiple state-of-the-art video generation models on VC-Bench. Experimental results reveal significant limitations in maintaining start-end consistency and transition smoothness, leading to lower overall coherence and fluidity. We expect that VC-Bench will serve as a pioneering benchmark to inspire and guide future research in video connecting. The evaluation metrics and dataset are publicly available at: https://anonymous.4open.science/r/VC-Bench-1B67/.
FunCineForge: A Unified Dataset Toolkit and Model for Zero-Shot Movie Dubbing in Diverse Cinematic Scenes
Jan 21, 2026Movie dubbing is the task of synthesizing speech from scripts conditioned on video scenes, requiring accurate lip sync, faithful timbre transfer, and proper modeling of character identity and emotion. However, existing methods face two major limitations: (1) high-quality multimodal dubbing datasets are limited in scale, suffer from high word error rates, contain sparse annotations, rely on costly manual labeling, and are restricted to monologue scenes, all of which hinder effective model training; (2) existing dubbing models rely solely on the lip region to learn audio-visual alignment, which limits their applicability to complex live-action cinematic scenes, and exhibit suboptimal performance in lip sync, speech quality, and emotional expressiveness. To address these issues, we propose FunCineForge, which comprises an end-to-end production pipeline for large-scale dubbing datasets and an MLLM-based dubbing model designed for diverse cinematic scenes. Using the pipeline, we construct the first Chinese television dubbing dataset with rich annotations, and demonstrate the high quality of these data. Experiments across monologue, narration, dialogue, and multi-speaker scenes show that our dubbing model consistently outperforms SOTA methods in audio quality, lip sync, timbre transfer, and instruction following. Code and demos are available at https://anonymous.4open.science/w/FunCineForge.
MCGA: A Multi-task Classical Chinese Literary Genre Audio Corpus
Jan 14, 2026With the rapid advancement of Multimodal Large Language Models (MLLMs), their potential has garnered significant attention in Chinese Classical Studies (CCS). While existing research has primarily focused on text and visual modalities, the audio corpus within this domain remains largely underexplored. To bridge this gap, we propose the Multi-task Classical Chinese Literary Genre Audio Corpus (MCGA). It encompasses a diverse range of literary genres across six tasks: Automatic Speech Recognition (ASR), Speech-to-Text Translation (S2TT), Speech Emotion Captioning (SEC), Spoken Question Answering (SQA), Speech Understanding (SU), and Speech Reasoning (SR). Through the evaluation of ten MLLMs, our experimental results demonstrate that current models still face substantial challenges when processed on the MCGA test set. Furthermore, we introduce an evaluation metric for SEC and a metric to measure the consistency between the speech and text capabilities of MLLMs. We release MCGA and our code to the public to facilitate the development of MLLMs with more robust multidimensional audio capabilities in CCS. MCGA Corpus: https://github.com/yxduir/MCGA
TeachPro: Multi-Label Qualitative Teaching Evaluation via Cross-View Graph Synergy and Semantic Anchored Evidence Encoding
Jan 14, 2026Standardized Student Evaluation of Teaching often suffer from low reliability, restricted response options, and response distortion. Existing machine learning methods that mine open-ended comments usually reduce feedback to binary sentiment, which overlooks concrete concerns such as content clarity, feedback timeliness, and instructor demeanor, and provides limited guidance for instructional improvement.We propose TeachPro, a multi-label learning framework that systematically assesses five key teaching dimensions: professional expertise, instructional behavior, pedagogical efficacy, classroom experience, and other performance metrics. We first propose a Dimension-Anchored Evidence Encoder, which integrates three core components: (i) a pre-trained text encoder that transforms qualitative feedback annotations into contextualized embeddings; (ii) a prompt module that represents five teaching dimensions as learnable semantic anchors; and (iii) a cross-attention mechanism that aligns evidence with pedagogical dimensions within a structured semantic space. We then propose a Cross-View Graph Synergy Network to represent student comments. This network comprises two components: (i) a Syntactic Branch that extracts explicit grammatical dependencies from parse trees, and (ii) a Semantic Branch that models latent conceptual relations derived from BERT-based similarity graphs. BiAffine fusion module aligns syntactic and semantic units, while a differential regularizer disentangles embeddings to encourage complementary representations. Finally, a cross-attention mechanism bridges the dimension-anchored evidence with the multi-view comment representations. We also contribute a novel benchmark dataset featuring expert qualitative annotations and multi-label scores. Extensive experiments demonstrate that TeachPro offers superior diagnostic granularity and robustness across diverse evaluation settings.
StablePDENet: Enhancing Stability of Operator Learning for Solving Differential Equations
Jan 10, 2026Learning solution operators for differential equations with neural networks has shown great potential in scientific computing, but ensuring their stability under input perturbations remains a critical challenge. This paper presents a robust self-supervised neural operator framework that enhances stability through adversarial training while preserving accuracy. We formulate operator learning as a min-max optimization problem, where the model is trained against worst-case input perturbations to achieve consistent performance under both normal and adversarial conditions. We demonstrate that our method not only achieves good performance on standard inputs, but also maintains high fidelity under adversarial perturbed inputs. The results highlight the importance of stability-aware training in operator learning and provide a foundation for developing reliable neural PDE solvers in real-world applications, where input noise and uncertainties are inevitable.
Towards a Golden Classifier-Free Guidance Path via Foresight Fixed Point Iterations
Oct 24, 2025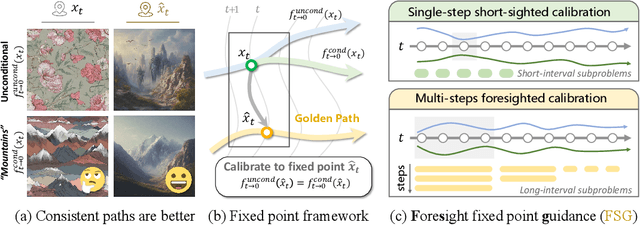

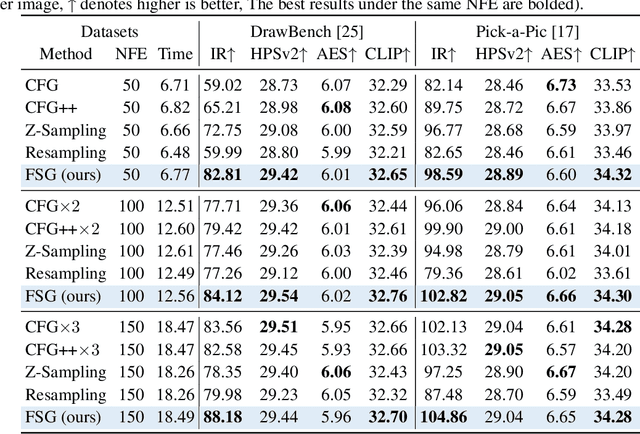
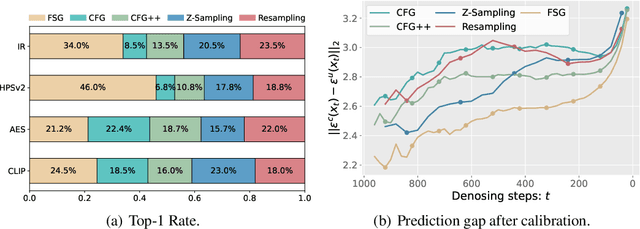
Classifier-Free Guidance (CFG) is an essential component of text-to-image diffusion models, and understanding and advancing its operational mechanisms remains a central focus of research. Existing approaches stem from divergent theoretical interpretations, thereby limiting the design space and obscuring key design choices. To address this, we propose a unified perspective that reframes conditional guidance as fixed point iterations, seeking to identify a golden path where latents produce consistent outputs under both conditional and unconditional generation. We demonstrate that CFG and its variants constitute a special case of single-step short-interval iteration, which is theoretically proven to exhibit inefficiency. To this end, we introduce Foresight Guidance (FSG), which prioritizes solving longer-interval subproblems in early diffusion stages with increased iterations. Extensive experiments across diverse datasets and model architectures validate the superiority of FSG over state-of-the-art methods in both image quality and computational efficiency. Our work offers novel perspectives for conditional guidance and unlocks the potential of adaptive design.
A Hierarchical Quantized Tokenization Framework for Task-Adaptive Graph Representation Learning
Oct 14, 2025Recent progress in language and vision foundation models demonstrates the importance of discrete token interfaces that transform complex inputs into compact sequences for large-scale modeling. Extending this paradigm to graphs requires a tokenization scheme that handles non-Euclidean structures and multi-scale dependencies efficiently. Existing approaches to graph tokenization, linearized, continuous, and quantized, remain limited in adaptability and efficiency. In particular, most current quantization-based tokenizers organize hierarchical information in fixed or task-agnostic ways, which may either over-represent or under-utilize structural cues, and lack the ability to dynamically reweight contributions from different levels without retraining the encoder. This work presents a hierarchical quantization framework that introduces a self-weighted mechanism for task-adaptive aggregation across multiple scales. The proposed method maintains a frozen encoder while modulating information flow through a lightweight gating process, enabling parameter-efficient adaptation to diverse downstream tasks. Experiments on benchmark datasets for node classification and link prediction demonstrate consistent improvements over strong baselines under comparable computational budgets.
From Bias to Balance: Exploring and Mitigating Spatial Bias in LVLMs
Sep 26, 2025



Large Vision-Language Models (LVLMs) have achieved remarkable success across a wide range of multimodal tasks, yet their robustness to spatial variations remains insufficiently understood. In this work, we present a systematic study of the spatial bias of LVLMs, focusing on how models respond when identical key visual information is placed at different locations within an image. Through a carefully designed probing dataset, we demonstrate that current LVLMs often produce inconsistent outputs under such spatial shifts, revealing a fundamental limitation in their spatial-semantic understanding. Further analysis shows that this phenomenon originates not from the vision encoder, which reliably perceives and interprets visual content across positions, but from the unbalanced design of position embeddings in the language model component. In particular, the widely adopted position embedding strategies, such as RoPE, introduce imbalance during cross-modal interaction, leading image tokens at different positions to exert unequal influence on semantic understanding. To mitigate this issue, we introduce Balanced Position Assignment (BaPA), a simple yet effective mechanism that assigns identical position embeddings to all image tokens, promoting a more balanced integration of visual information. Extensive experiments show that BaPA enhances the spatial robustness of LVLMs without retraining and further boosts their performance across diverse multimodal benchmarks when combined with lightweight fine-tuning. Further analysis of information flow reveals that BaPA yields balanced attention, enabling more holistic visual understanding.