 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStyleHEAT: One-Shot High-Resolution Editable Talking Face Generation via Pre-trained StyleGAN
Mar 17, 2022
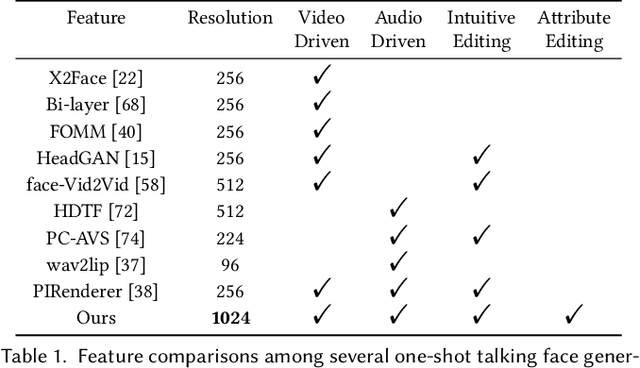

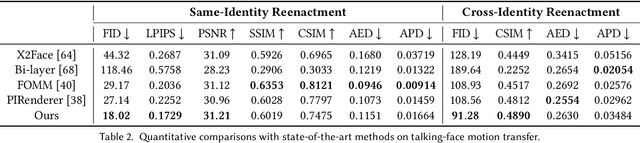
One-shot talking face generation aims at synthesizing a high-quality talking face video from an arbitrary portrait image, driven by a video or an audio segment. One challenging quality factor is the resolution of the output video: higher resolution conveys more details. In this work, we investigate the latent feature space of a pre-trained StyleGAN and discover some excellent spatial transformation properties. Upon the observation, we explore the possibility of using a pre-trained StyleGAN to break through the resolution limit of training datasets. We propose a novel unified framework based on a pre-trained StyleGAN that enables a set of powerful functionalities, i.e., high-resolution video generation, disentangled control by driving video or audio, and flexible face editing. Our framework elevates the resolution of the synthesized talking face to 1024*1024 for the first time, even though the training dataset has a lower resolution. We design a video-based motion generation module and an audio-based one, which can be plugged into the framework either individually or jointly to drive the video generation. The predicted motion is used to transform the latent features of StyleGAN for visual animation. To compensate for the transformation distortion, we propose a calibration network as well as a domain loss to refine the features. Moreover, our framework allows two types of facial editing, i.e., global editing via GAN inversion and intuitive editing based on 3D morphable models. Comprehensive experiments show superior video quality, flexible controllability, and editability over state-of-the-art methods.
Parallel Rectangle Flip Attack: A Query-based Black-box Attack against Object Detection
Jan 22, 2022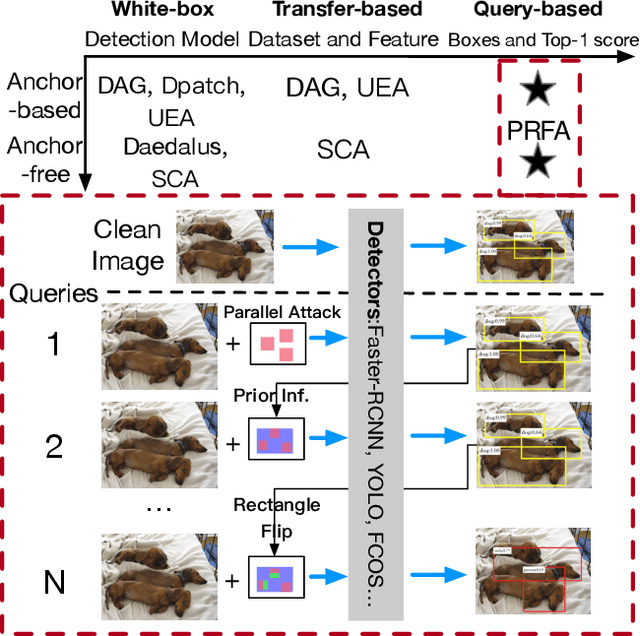


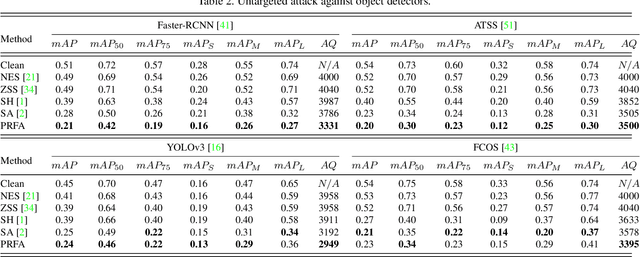
Object detection has been widely used in many safety-critical tasks, such as autonomous driving. However, its vulnerability to adversarial examples has not been sufficiently studied, especially under the practical scenario of black-box attacks, where the attacker can only access the query feedback of predicted bounding-boxes and top-1 scores returned by the attacked model. Compared with black-box attack to image classification, there are two main challenges in black-box attack to detection. Firstly, even if one bounding-box is successfully attacked, another sub-optimal bounding-box may be detected near the attacked bounding-box. Secondly, there are multiple bounding-boxes, leading to very high attack cost. To address these challenges, we propose a Parallel Rectangle Flip Attack (PRFA) via random search. We explain the difference between our method with other attacks in Fig.~\ref{fig1}. Specifically, we generate perturbations in each rectangle patch to avoid sub-optimal detection near the attacked region. Besides, utilizing the observation that adversarial perturbations mainly locate around objects' contours and critical points under white-box attacks, the search space of attacked rectangles is reduced to improve the attack efficiency. Moreover, we develop a parallel mechanism of attacking multiple rectangles simultaneously to further accelerate the attack process. Extensive experiments demonstrate that our method can effectively and efficiently attack various popular object detectors, including anchor-based and anchor-free, and generate transferable adversarial examples.
Robust Physical-World Attacks on Face Recognition
Sep 20, 2021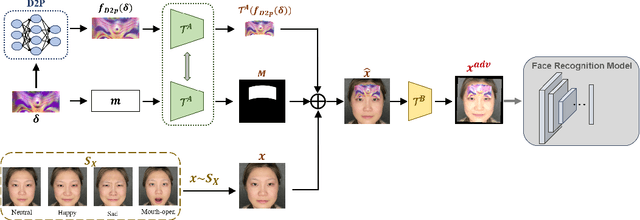

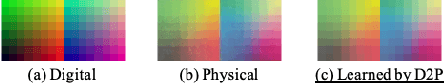

Face recognition has been greatly facilitated by the development of deep neural networks (DNNs) and has been widely applied to many safety-critical applications. However, recent studies have shown that DNNs are very vulnerable to adversarial examples, raising serious concerns on the security of real-world face recognition. In this work, we study sticker-based physical attacks on face recognition for better understanding its adversarial robustness. To this end, we first analyze in-depth the complicated physical-world conditions confronted by attacking face recognition, including the different variations of stickers, faces, and environmental conditions. Then, we propose a novel robust physical attack framework, dubbed PadvFace, to model these challenging variations specifically. Furthermore, considering the difference in attack complexity, we propose an efficient Curriculum Adversarial Attack (CAA) algorithm that gradually adapts adversarial stickers to environmental variations from easy to complex. Finally, we construct a standardized testing protocol to facilitate the fair evaluation of physical attacks on face recognition, and extensive experiments on both dodging and impersonation attacks demonstrate the superior performance of the proposed method.
High-Fidelity GAN Inversion for Image Attribute Editing
Sep 15, 2021
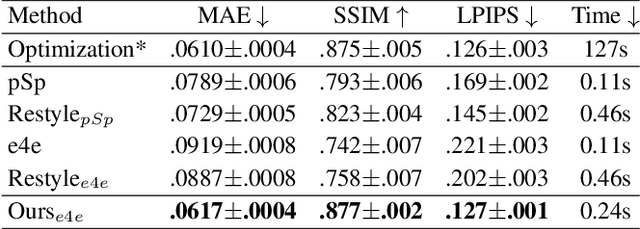
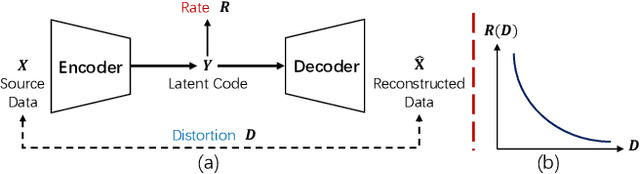

We present a novel high-fidelity generative adversarial network (GAN) inversion framework that enables attribute editing with image-specific details well-preserved (e.g., background, appearance and illumination). We first formulate GAN inversion as a lossy data compression problem and carefully discuss the Rate-Distortion-Edit trade-off. Due to this trade-off, previous works fail to achieve high-fidelity reconstruction while keeping compelling editing ability with a low bit-rate latent code only. In this work, we propose a distortion consultation approach that employs the distortion map as a reference for reconstruction. In the distortion consultation inversion (DCI), the distortion map is first projected to a high-rate latent map, which then complements the basic low-rate latent code with (lost) details via consultation fusion. To achieve high-fidelity editing, we propose an adaptive distortion alignment (ADA) module with a self-supervised training scheme. Extensive experiments in the face and car domains show a clear improvement in terms of both inversion and editing quality.
Regional Adversarial Training for Better Robust Generalization
Sep 04, 2021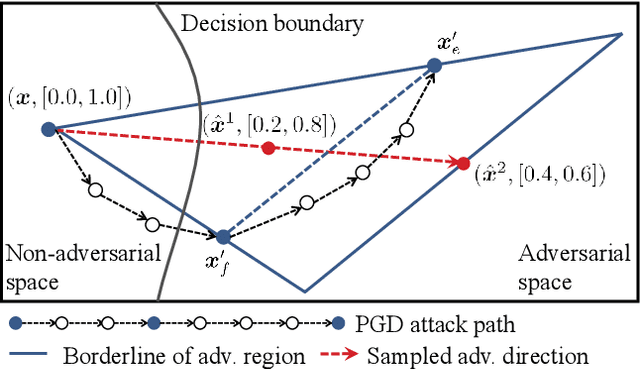
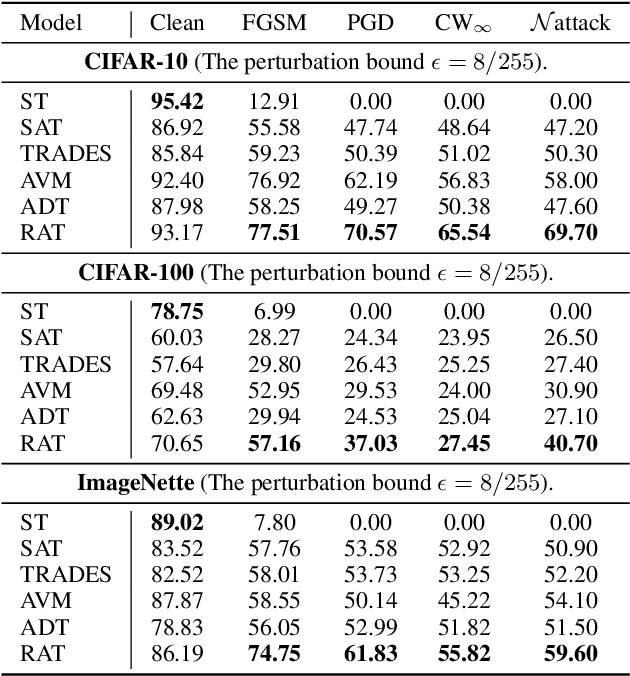
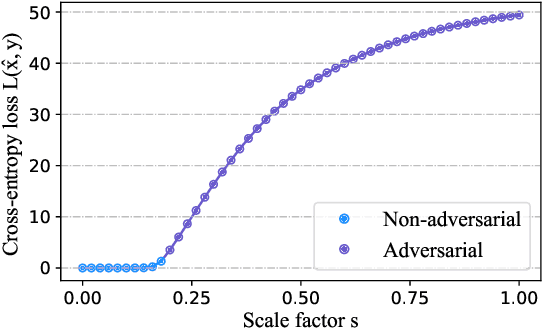
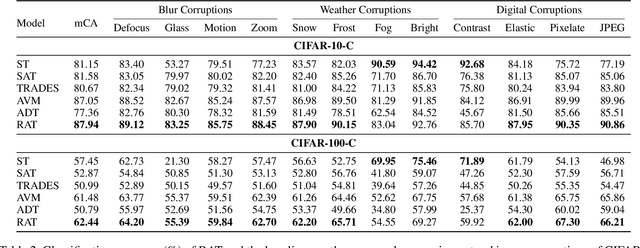
Adversarial training (AT) has been demonstrated as one of the most promising defense methods against various adversarial attacks. To our knowledge, existing AT-based methods usually train with the locally most adversarial perturbed points and treat all the perturbed points equally, which may lead to considerably weaker adversarial robust generalization on test data. In this work, we introduce a new adversarial training framework that considers the diversity as well as characteristics of the perturbed points in the vicinity of benign samples. To realize the framework, we propose a Regional Adversarial Training (RAT) defense method that first utilizes the attack path generated by the typical iterative attack method of projected gradient descent (PGD), and constructs an adversarial region based on the attack path. Then, RAT samples diverse perturbed training points efficiently inside this region, and utilizes a distance-aware label smoothing mechanism to capture our intuition that perturbed points at different locations should have different impact on the model performance. Extensive experiments on several benchmark datasets show that RAT consistently makes significant improvement on standard adversarial training (SAT), and exhibits better robust generalization.
DAE-GAN: Dynamic Aspect-aware GAN for Text-to-Image Synthesis
Aug 27, 2021
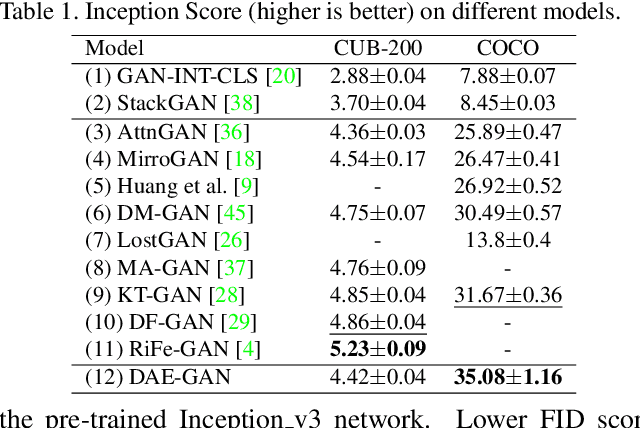
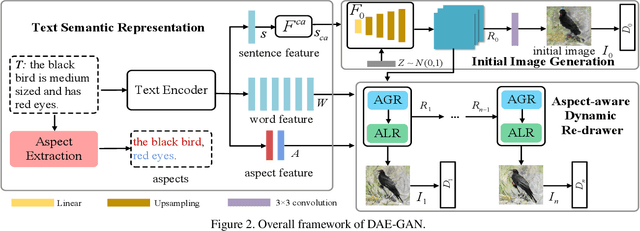
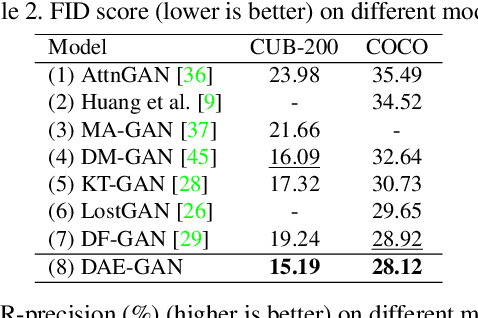
Text-to-image synthesis refers to generating an image from a given text description, the key goal of which lies in photo realism and semantic consistency. Previous methods usually generate an initial image with sentence embedding and then refine it with fine-grained word embedding. Despite the significant progress, the 'aspect' information (e.g., red eyes) contained in the text, referring to several words rather than a word that depicts 'a particular part or feature of something', is often ignored, which is highly helpful for synthesizing image details. How to make better utilization of aspect information in text-to-image synthesis still remains an unresolved challenge. To address this problem, in this paper, we propose a Dynamic Aspect-awarE GAN (DAE-GAN) that represents text information comprehensively from multiple granularities, including sentence-level, word-level, and aspect-level. Moreover, inspired by human learning behaviors, we develop a novel Aspect-aware Dynamic Re-drawer (ADR) for image refinement, in which an Attended Global Refinement (AGR) module and an Aspect-aware Local Refinement (ALR) module are alternately employed. AGR utilizes word-level embedding to globally enhance the previously generated image, while ALR dynamically employs aspect-level embedding to refine image details from a local perspective. Finally, a corresponding matching loss function is designed to ensure the text-image semantic consistency at different levels. Extensive experiments on two well-studied and publicly available datasets (i.e., CUB-200 and COCO) demonstrate the superiority and rationality of our method.
Theoretical Study of Random Noise Defense against Query-Based Black-Box Attacks
Apr 23, 2021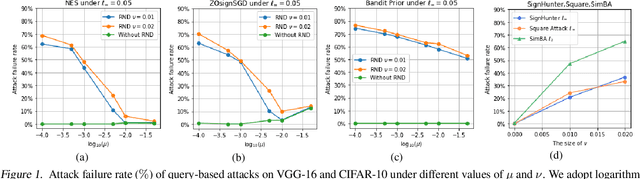
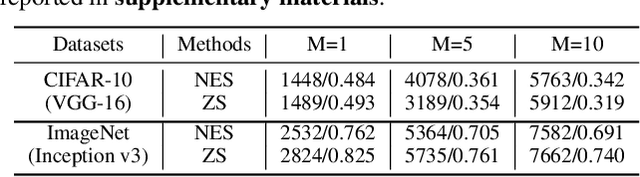
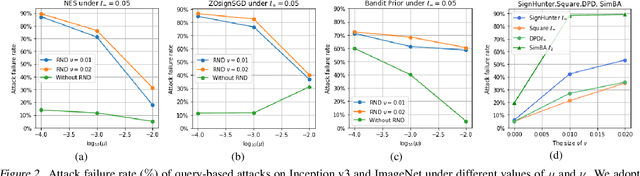
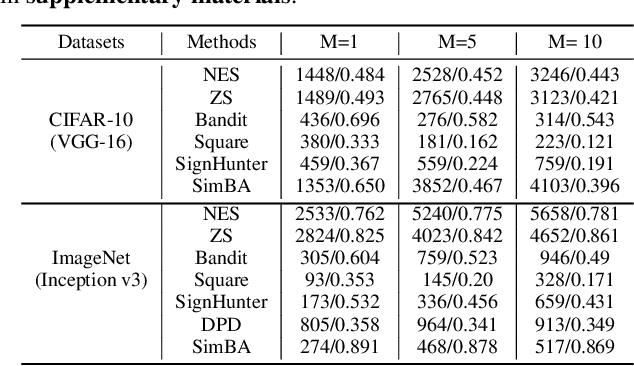
The query-based black-box attacks, which don't require any knowledge about the attacked models and datasets, have raised serious threats to machine learning models in many real applications. In this work, we study a simple but promising defense technique, dubbed Random Noise Defense (RND) against query-based black-box attacks, which adds proper Gaussian noise to each query. It is lightweight and can be directly combined with any off-the-shelf models and other defense strategies. However, the theoretical guarantee of random noise defense is missing, and the actual effectiveness of this defense is not yet fully understood. In this work, we present solid theoretical analyses to demonstrate that the defense effect of RND against the query-based black-box attack and the corresponding adaptive attack heavily depends on the magnitude ratio between the random noise added by the defender (i.e., RND) and the random noise added by the attacker for gradient estimation. Extensive experiments on CIFAR-10 and ImageNet verify our theoretical studies. Based on RND, we also propose a stronger defense method that combines RND with Gaussian augmentation training (RND-GT) and achieves better defense performance.
Dual ResGCN for Balanced Scene GraphGeneration
Nov 09, 2020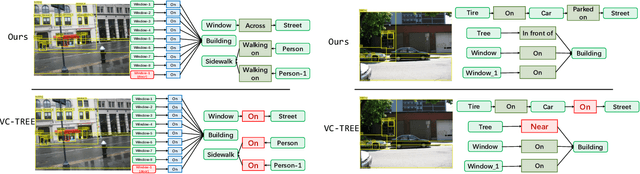
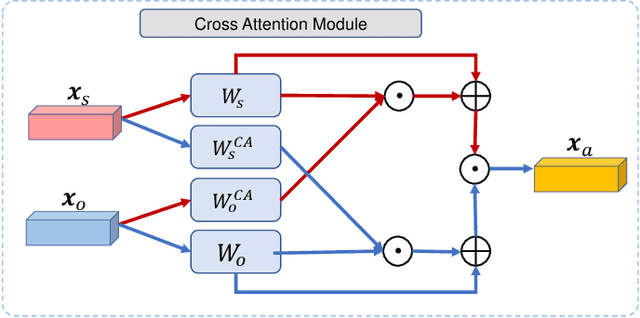
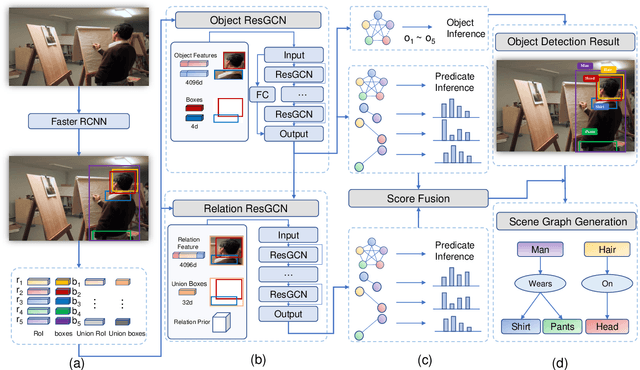
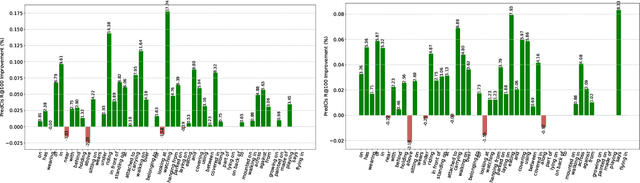
Visual scene graph generation is a challenging task. Previous works have achieved great progress, but most of them do not explicitly consider the class imbalance issue in scene graph generation. Models learned without considering the class imbalance tend to predict the majority classes, which leads to a good performance on trivial frequent predicates, but poor performance on informative infrequent predicates. However, predicates of minority classes often carry more semantic and precise information~(\textit{e.g.}, \emph{`on'} v.s \emph{`parked on'}). % which leads to a good score of recall, but a poor score of mean recall. To alleviate the influence of the class imbalance, we propose a novel model, dubbed \textit{dual ResGCN}, which consists of an object residual graph convolutional network and a relation residual graph convolutional network. The two networks are complementary to each other. The former captures object-level context information, \textit{i.e.,} the connections among objects. We propose a novel ResGCN that enhances object features in a cross attention manner. Besides, we stack multiple contextual coefficients to alleviate the imbalance issue and enrich the prediction diversity. The latter is carefully designed to explicitly capture relation-level context information \textit{i.e.,} the connections among relations. We propose to incorporate the prior about the co-occurrence of relation pairs into the graph to further help alleviate the class imbalance issue. Extensive evaluations of three tasks are performed on the large-scale database VG to demonstrate the superiority of the proposed method.
Efficient Black-Box Adversarial Attack Guided by the Distribution of Adversarial Perturbations
Jun 15, 2020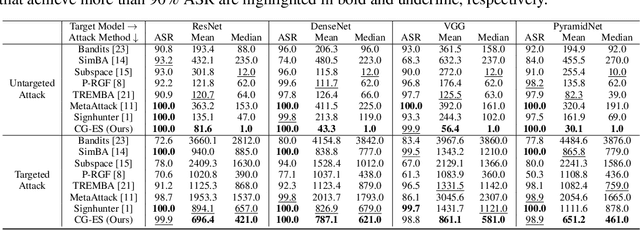
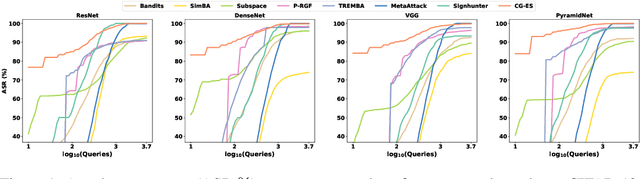
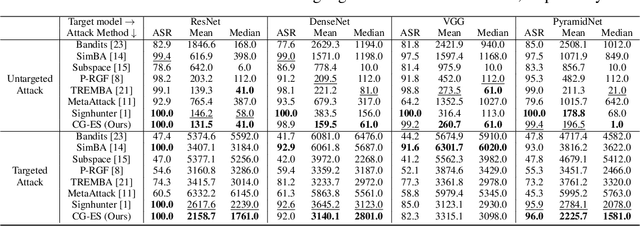
This work studied the score-based black-box adversarial attack problem, where only a continuous score is returned for each query, while the structure and parameters of the attacked model are unknown. A promising approach to solve this problem is evolution strategies (ES), which introduces a search distribution to sample perturbations that are likely to be adversarial. Gaussian distribution is widely adopted as the search distribution in the standard ES algorithm. However, it may not be flexible enough to capture the diverse distributions of adversarial perturbations around different benign examples. In this work, we propose to transform the Gaussian-distributed variable to another space through a conditional flow-based model, to enhance the capability and flexibility of capturing the intrinsic distribution of adversarial perturbations conditioned on the benign example. Besides, to further enhance the query efficiency, we propose to pre-train the conditional flow model based on some white-box surrogate models, utilizing the transferability of adversarial perturbations across different models, which has been widely observed in the literature of adversarial examples. Consequently, the proposed method could take advantage of both query-based and transfer-based attack methods, to achieve satisfying attack performance on both effectiveness and efficiency. Extensive experiments of attacking four target models on CIFAR-10 and Tiny-ImageNet verify the superior performance of the proposed method to state-of-the-art methods.
Effective and Robust Detection of Adversarial Examples via Benford-Fourier Coefficients
May 12, 2020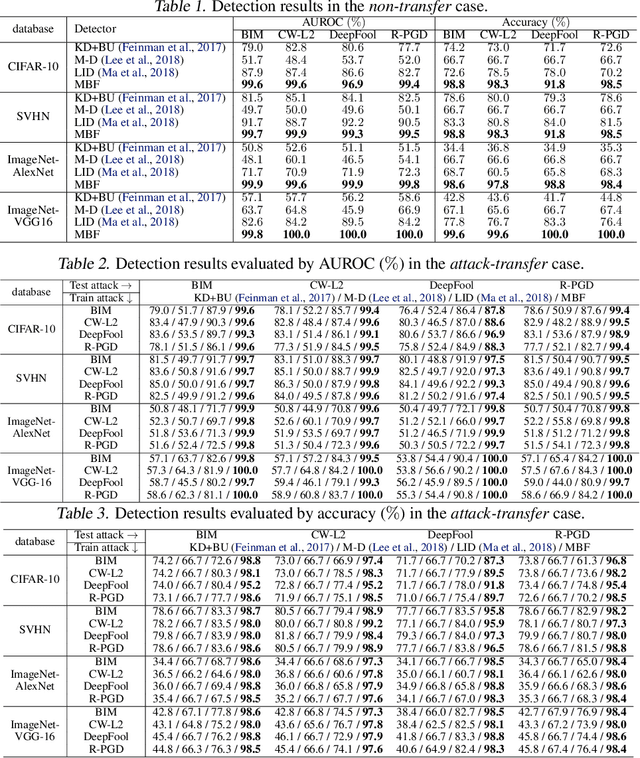
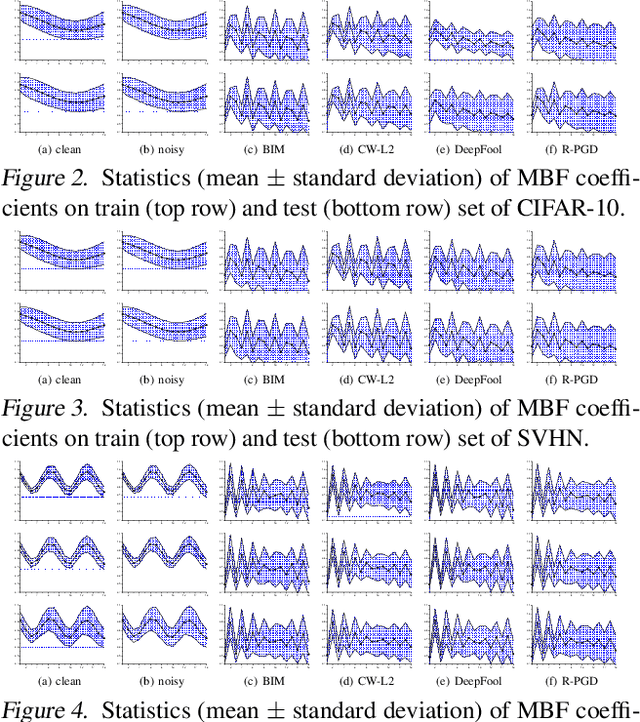
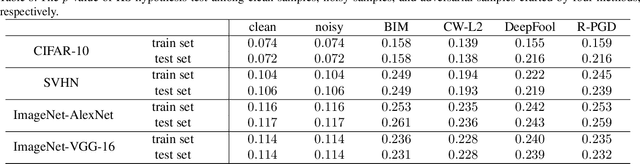
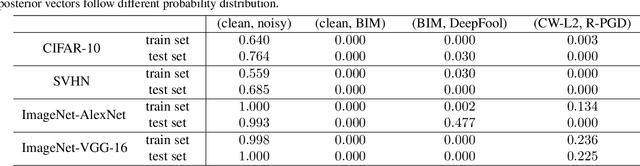
Adversarial examples have been well known as a serious threat to deep neural networks (DNNs). In this work, we study the detection of adversarial examples, based on the assumption that the output and internal responses of one DNN model for both adversarial and benign examples follow the generalized Gaussian distribution (GGD), but with different parameters (i.e., shape factor, mean, and variance). GGD is a general distribution family to cover many popular distributions (e.g., Laplacian, Gaussian, or uniform). It is more likely to approximate the intrinsic distributions of internal responses than any specific distribution. Besides, since the shape factor is more robust to different databases rather than the other two parameters, we propose to construct discriminative features via the shape factor for adversarial detection, employing the magnitude of Benford-Fourier coefficients (MBF), which can be easily estimated using responses. Finally, a support vector machine is trained as the adversarial detector through leveraging the MBF features. Extensive experiments in terms of image classification demonstrate that the proposed detector is much more effective and robust on detecting adversarial examples of different crafting methods and different sources, compared to state-of-the-art adversarial detection methods.