 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Reasoning Vision-Language Models Robust to Semantic Visual Distractions?
Jun 08, 2026Reasoning Vision-Language Models (VLMs) achieve strong performance on complex multimodal tasks, but reliable real-world application requires handling visual inputs that are messier than clean, curated benchmarks. Existing works mainly evaluate such reliability of VLMs through input corruptions, such as noise, blur and weather effects, which make visual evidence harder to perceive. This leaves a critical reliability failure mode underexplored: a model may perceive the evidence correctly, yet reason from plausible but irrelevant and distracting evidence and propagate this mistake to its final answer. To address this gap, we introduce \textbf{Distract-Bench}, a benchmark for evaluating VLM robustness to \textbf{semantic visual distractions}, defined as meaningful but task-irrelevant visual cues added to inputs while preserving the ground-truth answer. We comprehensively evaluate eight leading open-source and two closed-source VLMs across conventional vision corruptions and Distract-Bench. Our results show that Distract-Bench exposes a robustness failure distinct from vision corruptions: reasoning VLMs largely track their non-reasoning base models under perceptual degradation, but show consistently lower robustness to semantic distractions. Further analysis shows that these distractions often enter the reasoning process of VLMs, are treated as evidence, and lead to incorrect answers. Together, these findings reframe robustness evaluation for reasoning VLMs, shifting the focus from degraded perception to distractions for reliable real-world visual reasoning. Our data and code are available at https://github.com/Yizheng-Sun/Distract-Bench.
V2XCrafter: Learning to Generate Driving Scene Across Agents
May 28, 2026Collaborative driving systems leverage vehicle-to-everything (V2X) communication for multi-agent collaborative perception to enhance driving safety, yet they remain constrained by scarce annotated real-world V2X driving datasets and limited generalization across diverse driving conditions. While image generation technology offers a feasible solution for data augmentation, existing methods tailored for single-vehicle multi-view scenarios face two fundamental challenges in multi-agent driving settings: (1) the expansion of the learning objective degrades generation quality, and (2) the highly dynamic variations across agents hinder the modeling of consistency for physical attributes (e.g., color, category) in jointly observed objects. To bridge this gap, we propose V2XCrafter, the first framework for generating controllable and realistic collaborative driving scene across agents' camera views. For effective learning, we develop a progressive multi-agent diffusion model based on a single-agent backbone, using neighboring agents' latent states as reference signals to progressively guide the single-to-multi diffusion. To address cross-vehicle inconsistency, we propose a cross-agent attention module that leverages a collaboration view graph and learnable jointly observed object representation to model the dynamic cross-agent camera view relationships. Experiments have shown that V2XCrafter can generate high-fidelity and controllable street views with consistency across agents, thereby effectively enhancing the downstream collaborative 3D object detection tasks.
CXR-ContraBench: Benchmarking Negated-Option Attraction in Medical VLMs
May 07, 2026When a chest X-ray shows consolidation but the question asks which finding is present, a medical vision-language model may answer "No consolidation." This is more than an incorrect choice: it is a polarity reversal that emits a clinical statement contradicting the image. We study this failure as negated-option attraction, where a model is drawn to a negated answer option even when it conflicts with both the visual evidence and the question. We introduce CXR-ContraBench (Chest X-Ray Contradiction Benchmark), a diagnostic benchmark spanning internal ReXVQA slices and external OpenI and CheXpert protocols. The benchmark centers on present-finding questions, where selecting "No X" despite visible X creates the main clinical risk, and uses absent-finding questions as secondary tests of whether models copy negated wording. Across CheXpert protocols, the failure is substantial and persistent. On a strict direct presence probe, MedGemma and Qwen2.5-VL reach only 31.49% and 30.21% accuracy, respectively; on a matched 135,754-record CheXpert training-split protocol, both models select negated options on over 62% of presence questions. Chain-of-thought prompting reduces some presence-side reversals but does not eliminate them and can amplify absence-side contradictions. Finally, QCCV-Neg (Question-Conditioned Consistency Verifier for Negation) deterministically repairs the measured polarity-confused subset without retraining, raising MedGemma and Qwen2.5-VL to 96.60% and 95.32% accuracy on the direct presence probe. These results show that standard accuracy can hide a clinically meaningful inference-time polarity failure. Source code and benchmark construction scripts are available at https://github.com/fangzr/cxr-contrabench-code.
HFedMoE: Resource-aware Heterogeneous Federated Learning with Mixture-of-Experts
Jan 02, 2026While federated learning (FL) enables fine-tuning of large language models (LLMs) without compromising data privacy, the substantial size of an LLM renders on-device training impractical for resource-constrained clients, such as mobile devices. Thus, Mixture-of-Experts (MoE) models have emerged as a computation-efficient solution, which activates only a sparse subset of experts during model training to reduce computing burden without sacrificing performance. Though integrating MoE into FL fine-tuning holds significant potential, it still encounters three key challenges: i) selecting appropriate experts for clients remains challenging due to the lack of a reliable metric to measure each expert's impact on local fine-tuning performance, ii) the heterogeneous computing resources across clients severely hinder MoE-based LLM fine-tuning, as dynamic expert activations across diverse input samples can overwhelm resource-constrained devices, and iii) client-specific expert subsets and routing preference undermine global aggregation, where misaligned expert updates and inconsistent gating networks in troduce destructive interference. To address these challenges, we propose HFedMoE, a heterogeneous MoE-based FL fine-tuning framework that customizes a subset of experts to each client for computation-efficient LLM fine-tuning. Specifically, HFedMoE identifies the expert importance based on its contributions to fine-tuning performance, and then adaptively selects a subset of experts from an information bottleneck perspective to align with each client' s computing budget. A sparsity-aware model aggregation strategy is also designed to aggregate the actively fine-tuned experts and gating parameters with importance weighted contributions. Extensive experiments demonstrate that HFedMoE outperforms state-of-the-art benchmarks in training accuracy and convergence speed.
CAST: Corpus-Aware Self-similarity Enhanced Topic modelling
Oct 19, 2024



Topic modelling is a pivotal unsupervised machine learning technique for extracting valuable insights from large document collections. Existing neural topic modelling methods often encode contextual information of documents, while ignoring contextual details of candidate centroid words, leading to the inaccurate selection of topic words due to the contextualization gap. In parallel, it is found that functional words are frequently selected over topical words. To address these limitations, we introduce CAST: Corpus-Aware Self-similarity Enhanced Topic modelling, a novel topic modelling method that builds upon candidate centroid word embeddings contextualized on the dataset, and a novel self-similarity-based method to filter out less meaningful tokens. Inspired by findings in contrastive learning that self-similarities of functional token embeddings in different contexts are much lower than topical tokens, we find self-similarity to be an effective metric to prevent functional words from acting as candidate topic words. Our approach significantly enhances the coherence and diversity of generated topics, as well as the topic model's ability to handle noisy data. Experiments on news benchmark datasets and one Twitter dataset demonstrate the method's superiority in generating coherent, diverse topics, and handling noisy data, outperforming strong baselines.
Multi-periodicity dependency Transformer based on spectrum offset for radio frequency fingerprint identification
Aug 14, 2024



Radio Frequency Fingerprint Identification (RFFI) has emerged as a pivotal task for reliable device authentication. Despite advancements in RFFI methods, background noise and intentional modulation features result in weak energy and subtle differences in the RFF features. These challenges diminish the capability of RFFI methods in feature representation, complicating the effective identification of device identities. This paper proposes a novel Multi-Periodicity Dependency Transformer (MPDFormer) to address these challenges. The MPDFormer employs a spectrum offset-based periodic embedding representation to augment the discrepency of intrinsic features. We delve into the intricacies of the periodicity-dependency attention mechanism, integrating both inter-period and intra-period attention mechanisms. This mechanism facilitates the extraction of both long and short-range periodicity-dependency features , accentuating the feature distinction whilst concurrently attenuating the perturbations caused by background noise and weak-periodicity features. Empirical results demonstrate MPDFormer's superiority over established baseline methods, achieving a 0.07s inference time on NVIDIA Jetson Orin NX.
Optimization for Reflection and Transmission Dual-Functional Active RIS-Assisted Systems
Sep 05, 2022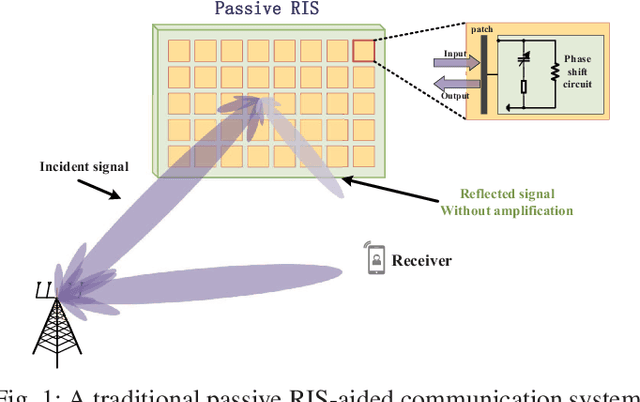
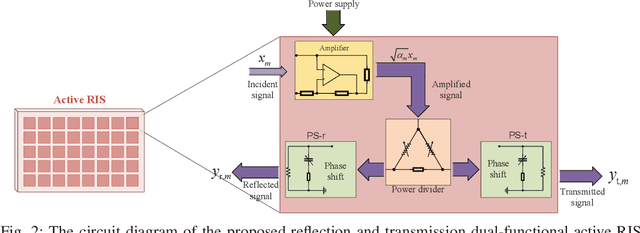
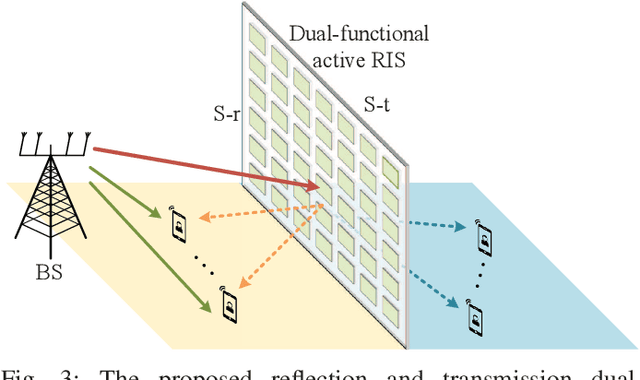
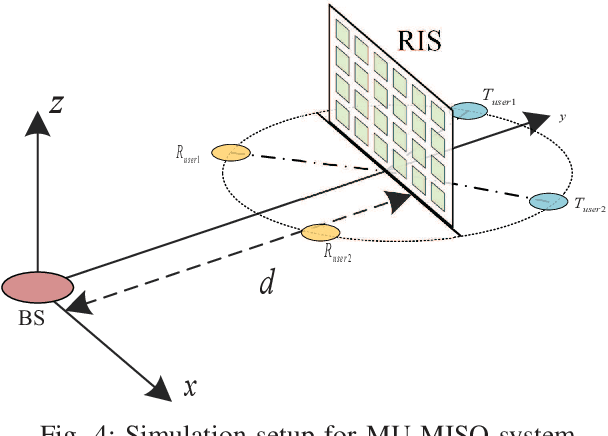
Reconfigurable intelligent surface (RIS) has been deemed as one of potential components of future wireless communication systems because it can adaptively manipulate the wireless propagation environment with low-cost passive devices. However, due to the severe double path loss, the traditional passive RIS can provide sufficient gain only when receivers are very close to the RIS. Moreover, RIS cannot provide signal coverage for the receivers at the back side of it. To address these drawbacks in practical implementation, we introduce a novel reflection and transmission dual-functional active RIS architecture in this paper, which can simultaneously realize reflection and transmission functionalities with active signal amplification to significantly extend signal coverage and enhance the quality-of-service (QoS) of all users. The problem of joint transmit beamforming and dual-functional active RIS design is investigated in RIS-enhanced multiuser multiple-input single-output (MU-MISO) systems. Both sum-rate maximization and power minimization problems are considered. To address their non-convexity, we develop efficient iterative algorithms to decompose them into separate several design problems, which are efficiently solved by exploiting fractional programming (FP) and Riemannian-manifold optimization techniques. Simulation results demonstrate the superiority of the proposed dual-functional active RIS architecture and the effectiveness of our proposed algorithms over various benchmark schemes.
Reflection and Relay Dual-Functional RIS Assisted MU-MISO Systems
Jul 24, 2021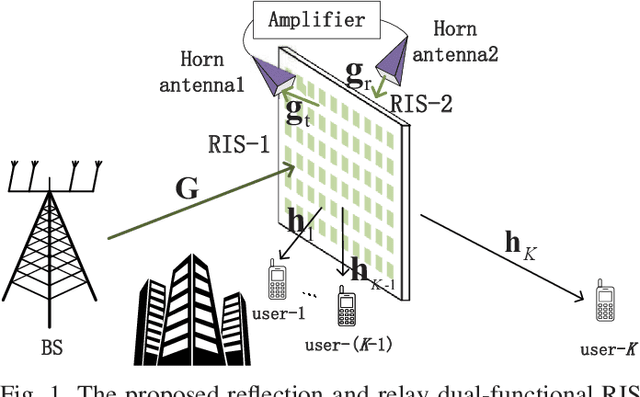

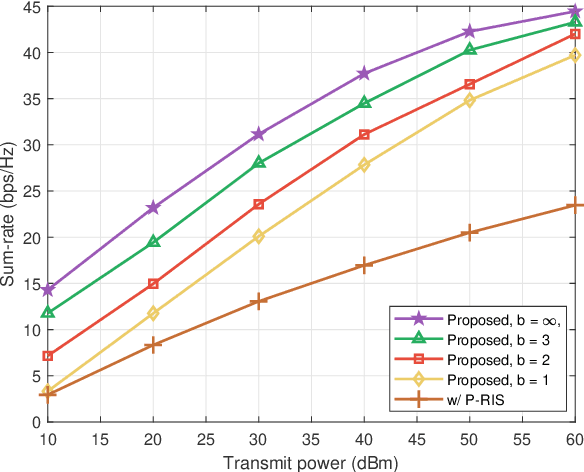
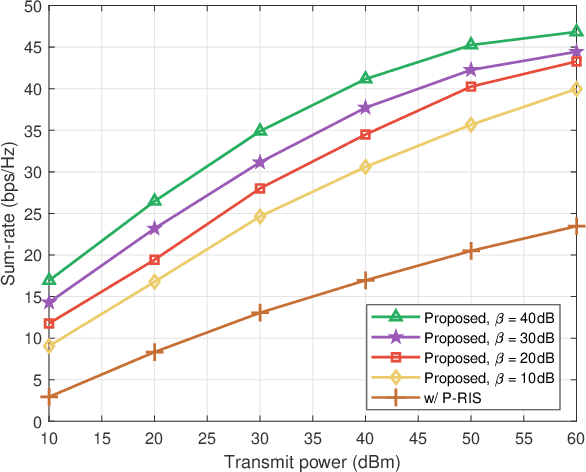
Reconfigurable intelligent surfaces (RISs) have been deemed as one of potential components of future wireless communication systems because they can adaptively manipulate the wireless propagation environment with low-cost passive devices. However, due to double fading effect, the passive RIS can offer sufficient signal strength only when receivers are nearby and located at the same side as the incident signals. Moreover, RIS cannot provide service coverage for the users at the back side of it. In this paper we introduce a novel reflection and relay dual-functional RIS architecture, which can simultaneously realize passive reflection and active relay functionalities to enhance the coverage. The problem of joint transmit beamforming and dual-functional RIS design is investigated to maximize the achievable sum-rate of a multiuser multiple-input single-output (MU-MISO) system. Based on fractional programming (FP) theory and majorization-minimization (MM) technique, we propose an efficient iterative transmit beamforming and RIS design algorithm. Simulation results demonstrate the superiority of the introduced dual-functional RIS architecture and the effectiveness of the proposed algorithm.