 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Effective and Compact Contextual Representation for Conformer Transducer Speech Recognition Systems
Jun 26, 2023Current ASR systems are mainly trained and evaluated at the utterance level. Long range cross utterance context can be incorporated. A key task is to derive a suitable compact representation of the most relevant history contexts. In contrast to previous researches based on either LSTM-RNN encoded histories that attenuate the information from longer range contexts, or frame level concatenation of transformer context embeddings, in this paper compact low-dimensional cross utterance contextual features are learned in the Conformer-Transducer Encoder using specially designed attention pooling layers that are applied over efficiently cached preceding utterances history vectors. Experiments on the 1000-hr Gigaspeech corpus demonstrate that the proposed contextualized streaming Conformer-Transducers outperform the baseline using utterance internal context only with statistically significant WER reductions of 0.7% to 0.5% absolute (4.3% to 3.1% relative) on the dev and test data.
Use of Speech Impairment Severity for Dysarthric Speech Recognition
May 18, 2023A key challenge in dysarthric speech recognition is the speaker-level diversity attributed to both speaker-identity associated factors such as gender, and speech impairment severity. Most prior researches on addressing this issue focused on using speaker-identity only. To this end, this paper proposes a novel set of techniques to use both severity and speaker-identity in dysarthric speech recognition: a) multitask training incorporating severity prediction error; b) speaker-severity aware auxiliary feature adaptation; and c) structured LHUC transforms separately conditioned on speaker-identity and severity. Experiments conducted on UASpeech suggest incorporating additional speech impairment severity into state-of-the-art hybrid DNN, E2E Conformer and pre-trained Wav2vec 2.0 ASR systems produced statistically significant WER reductions up to 4.78% (14.03% relative). Using the best system the lowest published WER of 17.82% (51.25% on very low intelligibility) was obtained on UASpeech.
Leveraging Pretrained Representations with Task-related Keywords for Alzheimer's Disease Detection
Mar 14, 2023With the global population aging rapidly, Alzheimer's disease (AD) is particularly prominent in older adults, which has an insidious onset and leads to a gradual, irreversible deterioration in cognitive domains (memory, communication, etc.). Speech-based AD detection opens up the possibility of widespread screening and timely disease intervention. Recent advances in pre-trained models motivate AD detection modeling to shift from low-level features to high-level representations. This paper presents several efficient methods to extract better AD-related cues from high-level acoustic and linguistic features. Based on these features, the paper also proposes a novel task-oriented approach by modeling the relationship between the participants' description and the cognitive task. Experiments are carried out on the ADReSS dataset in a binary classification setup, and models are evaluated on the unseen test set. Results and comparison with recent literature demonstrate the efficiency and superior performance of proposed acoustic, linguistic and task-oriented methods. The findings also show the importance of semantic and syntactic information, and feasibility of automation and generalization with the promising audio-only and task-oriented methods for the AD detection task.
A Hierarchical Regression Chain Framework for Affective Vocal Burst Recognition
Mar 14, 2023



As a common way of emotion signaling via non-linguistic vocalizations, vocal burst (VB) plays an important role in daily social interaction. Understanding and modeling human vocal bursts are indispensable for developing robust and general artificial intelligence. Exploring computational approaches for understanding vocal bursts is attracting increasing research attention. In this work, we propose a hierarchical framework, based on chain regression models, for affective recognition from VBs, that explicitly considers multiple relationships: (i) between emotional states and diverse cultures; (ii) between low-dimensional (arousal & valence) and high-dimensional (10 emotion classes) emotion spaces; and (iii) between various emotion classes within the high-dimensional space. To address the challenge of data sparsity, we also use self-supervised learning (SSL) representations with layer-wise and temporal aggregation modules. The proposed systems participated in the ACII Affective Vocal Burst (A-VB) Challenge 2022 and ranked first in the "TWO'' and "CULTURE'' tasks. Experimental results based on the ACII Challenge 2022 dataset demonstrate the superior performance of the proposed system and the effectiveness of considering multiple relationships using hierarchical regression chain models.
Exploring Self-supervised Pre-trained ASR Models For Dysarthric and Elderly Speech Recognition
Feb 28, 2023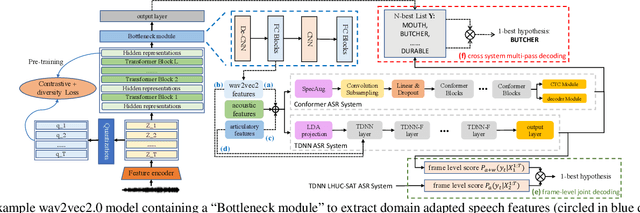
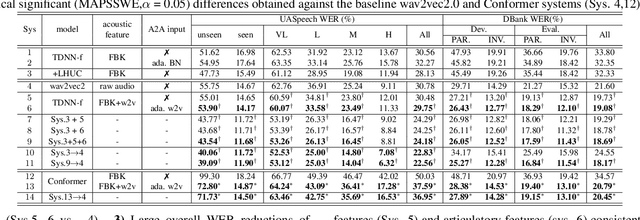


Automatic recognition of disordered and elderly speech remains a highly challenging task to date due to the difficulty in collecting such data in large quantities. This paper explores a series of approaches to integrate domain adapted SSL pre-trained models into TDNN and Conformer ASR systems for dysarthric and elderly speech recognition: a) input feature fusion between standard acoustic frontends and domain adapted wav2vec2.0 speech representations; b) frame-level joint decoding of TDNN systems separately trained using standard acoustic features alone and with additional wav2vec2.0 features; and c) multi-pass decoding involving the TDNN/Conformer system outputs to be rescored using domain adapted wav2vec2.0 models. In addition, domain adapted wav2vec2.0 representations are utilized in acoustic-to-articulatory (A2A) inversion to construct multi-modal dysarthric and elderly speech recognition systems. Experiments conducted on the UASpeech dysarthric and DementiaBank Pitt elderly speech corpora suggest TDNN and Conformer ASR systems integrated domain adapted wav2vec2.0 models consistently outperform the standalone wav2vec2.0 models by statistically significant WER reductions of 8.22% and 3.43% absolute (26.71% and 15.88% relative) on the two tasks respectively. The lowest published WERs of 22.56% (52.53% on very low intelligibility, 39.09% on unseen words) and 18.17% are obtained on the UASpeech test set of 16 dysarthric speakers, and the DementiaBank Pitt test set respectively.
Confidence Score Based Speaker Adaptation of Conformer Speech Recognition Systems
Feb 15, 2023



Speaker adaptation techniques provide a powerful solution to customise automatic speech recognition (ASR) systems for individual users. Practical application of unsupervised model-based speaker adaptation techniques to data intensive end-to-end ASR systems is hindered by the scarcity of speaker-level data and performance sensitivity to transcription errors. To address these issues, a set of compact and data efficient speaker-dependent (SD) parameter representations are used to facilitate both speaker adaptive training and test-time unsupervised speaker adaptation of state-of-the-art Conformer ASR systems. The sensitivity to supervision quality is reduced using a confidence score-based selection of the less erroneous subset of speaker-level adaptation data. Two lightweight confidence score estimation modules are proposed to produce more reliable confidence scores. The data sparsity issue, which is exacerbated by data selection, is addressed by modelling the SD parameter uncertainty using Bayesian learning. Experiments on the benchmark 300-hour Switchboard and the 233-hour AMI datasets suggest that the proposed confidence score-based adaptation schemes consistently outperformed the baseline speaker-independent (SI) Conformer model and conventional non-Bayesian, point estimate-based adaptation using no speaker data selection. Similar consistent performance improvements were retained after external Transformer and LSTM language model rescoring. In particular, on the 300-hour Switchboard corpus, statistically significant WER reductions of 1.0%, 1.3%, and 1.4% absolute (9.5%, 10.9%, and 11.3% relative) were obtained over the baseline SI Conformer on the NIST Hub5'00, RT02, and RT03 evaluation sets respectively. Similar WER reductions of 2.7% and 3.3% absolute (8.9% and 10.2% relative) were also obtained on the AMI development and evaluation sets.
Unsupervised Model-based speaker adaptation of end-to-end lattice-free MMI model for speech recognition
Nov 17, 2022Modeling the speaker variability is a key challenge for automatic speech recognition (ASR) systems. In this paper, the learning hidden unit contributions (LHUC) based adaptation techniques with compact speaker dependent (SD) parameters are used to facilitate both speaker adaptive training (SAT) and unsupervised test-time speaker adaptation for end-to-end (E2E) lattice-free MMI (LF-MMI) models. An unsupervised model-based adaptation framework is proposed to estimate the SD parameters in E2E paradigm using LF-MMI and cross entropy (CE) criterions. Various regularization methods of the standard LHUC adaptation, e.g., the Bayesian LHUC (BLHUC) adaptation, are systematically investigated to mitigate the risk of overfitting, on E2E LF-MMI CNN-TDNN and CNN-TDNN-BLSTM models. Lattice-based confidence score estimation is used for adaptation data selection to reduce the supervision label uncertainty. Experiments on the 300-hour Switchboard task suggest that applying BLHUC in the proposed unsupervised E2E adaptation framework to byte pair encoding (BPE) based E2E LF-MMI systems consistently outperformed the baseline systems by relative word error rate (WER) reductions up to 10.5% and 14.7% on the NIST Hub5'00 and RT03 evaluation sets, and achieved the best performance in WERs of 9.0% and 9.7%, respectively. These results are comparable to the results of state-of-the-art adapted LF-MMI hybrid systems and adapted Conformer-based E2E systems.
Adversarial Data Augmentation Using VAE-GAN for Disordered Speech Recognition
Nov 03, 2022Automatic recognition of disordered speech remains a highly challenging task to date. The underlying neuro-motor conditions, often compounded with co-occurring physical disabilities, lead to the difficulty in collecting large quantities of impaired speech required for ASR system development. This paper presents novel variational auto-encoder generative adversarial network (VAE-GAN) based personalized disordered speech augmentation approaches that simultaneously learn to encode, generate and discriminate synthesized impaired speech. Separate latent features are derived to learn dysarthric speech characteristics and phoneme context representations. Self-supervised pre-trained Wav2vec 2.0 embedding features are also incorporated. Experiments conducted on the UASpeech corpus suggest the proposed adversarial data augmentation approach consistently outperformed the baseline speed perturbation and non-VAE GAN augmentation methods with trained hybrid TDNN and End-to-end Conformer systems. After LHUC speaker adaptation, the best system using VAE-GAN based augmentation produced an overall WER of 27.78% on the UASpeech test set of 16 dysarthric speakers, and the lowest published WER of 57.31% on the subset of speakers with "Very Low" intelligibility.
Exploiting prompt learning with pre-trained language models for Alzheimer's Disease detection
Oct 29, 2022Early diagnosis of Alzheimer's disease (AD) is crucial in facilitating preventive care and to delay further progression. Speech based automatic AD screening systems provide a non-intrusive and more scalable alternative to other clinical screening techniques. Textual embedding features produced by pre-trained language models (PLMs) such as BERT are widely used in such systems. However, PLM domain fine-tuning is commonly based on the masked word or sentence prediction costs that are inconsistent with the back-end AD detection task. To this end, this paper investigates the use of prompt-based fine-tuning of PLMs that consistently uses AD classification errors as the training objective function. Disfluency features based on hesitation or pause filler token frequencies are further incorporated into prompt phrases during PLM fine-tuning. The exploit of the complementarity between BERT or RoBERTa based PLMs that are either prompt learning fine-tuned, or optimized using conventional masked word or sentence prediction costs, decision voting based system combination between them is further applied. Mean, standard deviation and the maximum among accuracy scores over 15 experiment runs are adopted as performance measurements for the AD detection system. Mean detection accuracy of 84.20% (with std 2.09%, best 87.5%) and 82.64% (with std 4.0%, best 89.58%) were obtained using manual and ASR speech transcripts respectively on the ADReSS20 test set consisting of 48 elderly speakers.
Disentangled Speech Representation Learning for One-Shot Cross-lingual Voice Conversion Using $β$-VAE
Oct 25, 2022



We propose an unsupervised learning method to disentangle speech into content representation and speaker identity representation. We apply this method to the challenging one-shot cross-lingual voice conversion task to demonstrate the effectiveness of the disentanglement. Inspired by $\beta$-VAE, we introduce a learning objective that balances between the information captured by the content and speaker representations. In addition, the inductive biases from the architectural design and the training dataset further encourage the desired disentanglement. Both objective and subjective evaluations show the effectiveness of the proposed method in speech disentanglement and in one-shot cross-lingual voice conversion.