 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Pixels and Words: Mask-Aware Local Semantic Fusion for Multimodal Media Verification
Mar 27, 2026As multimodal misinformation becomes more sophisticated, its detection and grounding are crucial. However, current multimodal verification methods, relying on passive holistic fusion, struggle with sophisticated misinformation. Due to 'feature dilution,' global alignments tend to average out subtle local semantic inconsistencies, effectively masking the very conflicts they are designed to find. We introduce MaLSF (Mask-aware Local Semantic Fusion), a novel framework that shifts the paradigm to active, bidirectional verification, mimicking human cognitive cross-referencing. MaLSF utilizes mask-label pairs as semantic anchors to bridge pixels and words. Its core mechanism features two innovations: 1) a Bidirectional Cross-modal Verification (BCV) module that acts as an interrogator, using parallel query streams (Text-as-Query and Image-as-Query) to explicitly pinpoint conflicts; and 2) a Hierarchical Semantic Aggregation (HSA) module that intelligently aggregates these multi-granularity conflict signals for task-specific reasoning. In addition, to extract fine-grained mask-label pairs, we introduce a set of diverse mask-label pair extraction parsers. MaLSF achieves state-of-the-art performance on both the DGM4 and multimodal fake news detection tasks. Extensive ablation studies and visualization results further verify its effectiveness and interpretability.
Hyperbolic Multiview Pretraining for Robotic Manipulation
Mar 05, 20263D-aware visual pretraining has proven effective in improving the performance of downstream robotic manipulation tasks. However, existing methods are constrained to Euclidean embedding spaces, whose flat geometry limits their ability to model structural relations among embeddings. As a result, they struggle to learn structured embeddings that are essential for robust spatial perception in robotic applications. To this end, we propose HyperMVP, a self-supervised framework for \underline{Hyper}bolic \underline{M}ulti\underline{V}iew \underline{P}retraining. Hyperbolic space offers geometric properties well suited for capturing structural relations. Methodologically, we extend the masked autoencoder paradigm and design a GeoLink encoder to learn multiview hyperbolic representations. The pretrained encoder is then finetuned with visuomotor policies on manipulation tasks. In addition, we introduce 3D-MOV, a large-scale dataset comprising multiple types of 3D point clouds to support pretraining. We evaluate HyperMVP on COLOSSEUM, RLBench, and real-world scenarios, where it consistently outperforms strong baselines across diverse tasks and perturbation settings. Our results highlight the potential of 3D-aware pretraining in a non-Euclidean space for learning robust and generalizable robotic manipulation policies.
R^3-VQA: "Read the Room" by Video Social Reasoning
May 07, 2025



"Read the room" is a significant social reasoning capability in human daily life. Humans can infer others' mental states from subtle social cues. Previous social reasoning tasks and datasets lack complexity (e.g., simple scenes, basic interactions, incomplete mental state variables, single-step reasoning, etc.) and fall far short of the challenges present in real-life social interactions. In this paper, we contribute a valuable, high-quality, and comprehensive video dataset named R^3-VQA with precise and fine-grained annotations of social events and mental states (i.e., belief, intent, desire, and emotion) as well as corresponding social causal chains in complex social scenarios. Moreover, we include human-annotated and model-generated QAs. Our task R^3-VQA includes three aspects: Social Event Understanding, Mental State Estimation, and Social Causal Reasoning. As a benchmark, we comprehensively evaluate the social reasoning capabilities and consistencies of current state-of-the-art large vision-language models (LVLMs). Comprehensive experiments show that (i) LVLMs are still far from human-level consistent social reasoning in complex social scenarios; (ii) Theory of Mind (ToM) prompting can help LVLMs perform better on social reasoning tasks. We provide some of our dataset and codes in supplementary material and will release our full dataset and codes upon acceptance.
STCOcc: Sparse Spatial-Temporal Cascade Renovation for 3D Occupancy and Scene Flow Prediction
Apr 28, 2025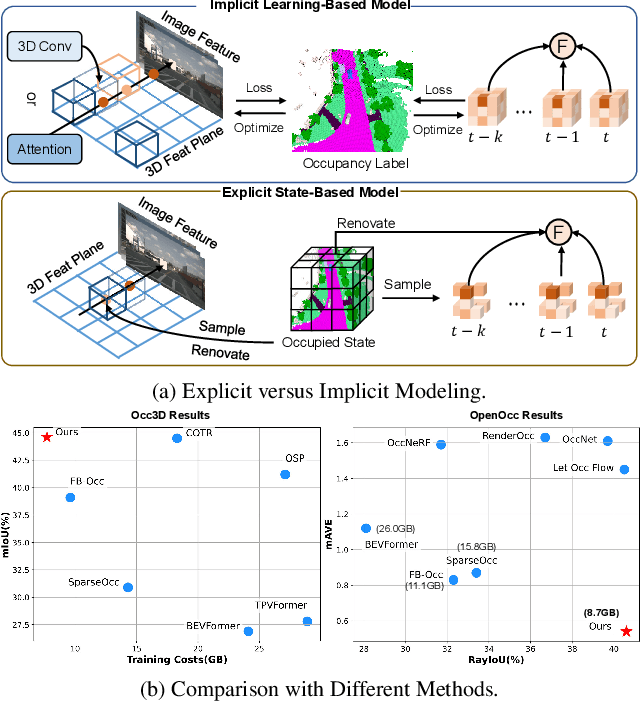
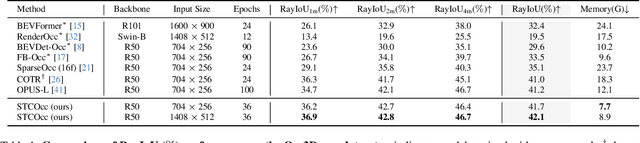
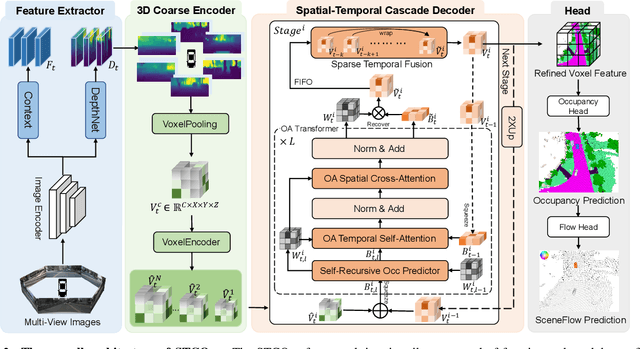
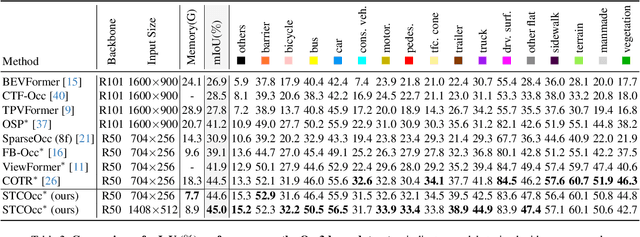
3D occupancy and scene flow offer a detailed and dynamic representation of 3D scene. Recognizing the sparsity and complexity of 3D space, previous vision-centric methods have employed implicit learning-based approaches to model spatial and temporal information. However, these approaches struggle to capture local details and diminish the model's spatial discriminative ability. To address these challenges, we propose a novel explicit state-based modeling method designed to leverage the occupied state to renovate the 3D features. Specifically, we propose a sparse occlusion-aware attention mechanism, integrated with a cascade refinement strategy, which accurately renovates 3D features with the guidance of occupied state information. Additionally, we introduce a novel method for modeling long-term dynamic interactions, which reduces computational costs and preserves spatial information. Compared to the previous state-of-the-art methods, our efficient explicit renovation strategy not only delivers superior performance in terms of RayIoU and mAVE for occupancy and scene flow prediction but also markedly reduces GPU memory usage during training, bringing it down to 8.7GB. Our code is available on https://github.com/lzzzzzm/STCOcc
Alchemy: Amplifying Theorem-Proving Capability through Symbolic Mutation
Oct 21, 2024



Formal proofs are challenging to write even for experienced experts. Recent progress in Neural Theorem Proving (NTP) shows promise in expediting this process. However, the formal corpora available on the Internet are limited compared to the general text, posing a significant data scarcity challenge for NTP. To address this issue, this work proposes Alchemy, a general framework for data synthesis that constructs formal theorems through symbolic mutation. Specifically, for each candidate theorem in Mathlib, we identify all invocable theorems that can be used to rewrite or apply to it. Subsequently, we mutate the candidate theorem by replacing the corresponding term in the statement with its equivalent form or antecedent. As a result, our method increases the number of theorems in Mathlib by an order of magnitude, from 110k to 6M. Furthermore, we perform continual pretraining and supervised finetuning on this augmented corpus for large language models. Experimental results demonstrate the effectiveness of our approach, achieving a 5% absolute performance improvement on Leandojo benchmark. Additionally, our synthetic data achieve a 2.5% absolute performance gain on the out-of-distribution miniF2F benchmark. To provide further insights, we conduct a comprehensive analysis of synthetic data composition and the training paradigm, offering valuable guidance for developing a strong theorem prover.
Relation DETR: Exploring Explicit Position Relation Prior for Object Detection
Jul 16, 2024This paper presents a general scheme for enhancing the convergence and performance of DETR (DEtection TRansformer). We investigate the slow convergence problem in transformers from a new perspective, suggesting that it arises from the self-attention that introduces no structural bias over inputs. To address this issue, we explore incorporating position relation prior as attention bias to augment object detection, following the verification of its statistical significance using a proposed quantitative macroscopic correlation (MC) metric. Our approach, termed Relation-DETR, introduces an encoder to construct position relation embeddings for progressive attention refinement, which further extends the traditional streaming pipeline of DETR into a contrastive relation pipeline to address the conflicts between non-duplicate predictions and positive supervision. Extensive experiments on both generic and task-specific datasets demonstrate the effectiveness of our approach. Under the same configurations, Relation-DETR achieves a significant improvement (+2.0% AP compared to DINO), state-of-the-art performance (51.7% AP for 1x and 52.1% AP for 2x settings), and a remarkably faster convergence speed (over 40% AP with only 2 training epochs) than existing DETR detectors on COCO val2017. Moreover, the proposed relation encoder serves as a universal plug-in-and-play component, bringing clear improvements for theoretically any DETR-like methods. Furthermore, we introduce a class-agnostic detection dataset, SA-Det-100k. The experimental results on the dataset illustrate that the proposed explicit position relation achieves a clear improvement of 1.3% AP, highlighting its potential towards universal object detection. The code and dataset are available at https://github.com/xiuqhou/Relation-DETR.
Task-Driven Exploration: Decoupling and Inter-Task Feedback for Joint Moment Retrieval and Highlight Detection
Apr 14, 2024



Video moment retrieval and highlight detection are two highly valuable tasks in video understanding, but until recently they have been jointly studied. Although existing studies have made impressive advancement recently, they predominantly follow the data-driven bottom-up paradigm. Such paradigm overlooks task-specific and inter-task effects, resulting in poor model performance. In this paper, we propose a novel task-driven top-down framework TaskWeave for joint moment retrieval and highlight detection. The framework introduces a task-decoupled unit to capture task-specific and common representations. To investigate the interplay between the two tasks, we propose an inter-task feedback mechanism, which transforms the results of one task as guiding masks to assist the other task. Different from existing methods, we present a task-dependent joint loss function to optimize the model. Comprehensive experiments and in-depth ablation studies on QVHighlights, TVSum, and Charades-STA datasets corroborate the effectiveness and flexibility of the proposed framework. Codes are available at https://github.com/EdenGabriel/TaskWeave.
Salience DETR: Enhancing Detection Transformer with Hierarchical Salience Filtering Refinement
Mar 24, 2024



DETR-like methods have significantly increased detection performance in an end-to-end manner. The mainstream two-stage frameworks of them perform dense self-attention and select a fraction of queries for sparse cross-attention, which is proven effective for improving performance but also introduces a heavy computational burden and high dependence on stable query selection. This paper demonstrates that suboptimal two-stage selection strategies result in scale bias and redundancy due to the mismatch between selected queries and objects in two-stage initialization. To address these issues, we propose hierarchical salience filtering refinement, which performs transformer encoding only on filtered discriminative queries, for a better trade-off between computational efficiency and precision. The filtering process overcomes scale bias through a novel scale-independent salience supervision. To compensate for the semantic misalignment among queries, we introduce elaborate query refinement modules for stable two-stage initialization. Based on above improvements, the proposed Salience DETR achieves significant improvements of +4.0% AP, +0.2% AP, +4.4% AP on three challenging task-specific detection datasets, as well as 49.2% AP on COCO 2017 with less FLOPs. The code is available at https://github.com/xiuqhou/Salience-DETR.
Efficient Monaural Speech Enhancement using Spectrum Attention Fusion
Aug 04, 2023Speech enhancement is a demanding task in automated speech processing pipelines, focusing on separating clean speech from noisy channels. Transformer based models have recently bested RNN and CNN models in speech enhancement, however at the same time they are much more computationally expensive and require much more high quality training data, which is always hard to come by. In this paper, we present an improvement for speech enhancement models that maintains the expressiveness of self-attention while significantly reducing model complexity, which we have termed Spectrum Attention Fusion. We carefully construct a convolutional module to replace several self-attention layers in a speech Transformer, allowing the model to more efficiently fuse spectral features. Our proposed model is able to achieve comparable or better results against SOTA models but with significantly smaller parameters (0.58M) on the Voice Bank + DEMAND dataset.
Generative Steganographic Flow
May 10, 2023



Generative steganography (GS) is a new data hiding manner, featuring direct generation of stego media from secret data. Existing GS methods are generally criticized for their poor performances. In this paper, we propose a novel flow based GS approach -- Generative Steganographic Flow (GSF), which provides direct generation of stego images without cover image. We take the stego image generation and secret data recovery process as an invertible transformation, and build a reversible bijective mapping between input secret data and generated stego images. In the forward mapping, secret data is hidden in the input latent of Glow model to generate stego images. By reversing the mapping, hidden data can be extracted exactly from generated stego images. Furthermore, we propose a novel latent optimization strategy to improve the fidelity of stego images. Experimental results show our proposed GSF has far better performances than SOTA works.