 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIKFST: IOO and KOO Algorithms for Accelerated and Precise WFST-based End-to-End Automatic Speech Recognition
Jan 01, 2026End-to-end automatic speech recognition has become the dominant paradigm in both academia and industry. To enhance recognition performance, the Weighted Finite-State Transducer (WFST) is widely adopted to integrate acoustic and language models through static graph composition, providing robust decoding and effective error correction. However, WFST decoding relies on a frame-by-frame autoregressive search over CTC posterior probabilities, which severely limits inference efficiency. Motivated by establishing a more principled compatibility between WFST decoding and CTC modeling, we systematically study the two fundamental components of CTC outputs, namely blank and non-blank frames, and identify a key insight: blank frames primarily encode positional information, while non-blank frames carry semantic content. Building on this observation, we introduce Keep-Only-One and Insert-Only-One, two decoding algorithms that explicitly exploit the structural roles of blank and non-blank frames to achieve significantly faster WFST-based inference without compromising recognition accuracy. Experiments on large-scale in-house, AISHELL-1, and LibriSpeech datasets demonstrate state-of-the-art recognition accuracy with substantially reduced decoding latency, enabling truly efficient and high-performance WFST decoding in modern speech recognition systems.
ParaMaP: Parallel Mapping and Collision-free Motion Planning for Reactive Robot Manipulation
Dec 27, 2025Real-time and collision-free motion planning remains challenging for robotic manipulation in unknown environments due to continuous perception updates and the need for frequent online replanning. To address these challenges, we propose a parallel mapping and motion planning framework that tightly integrates Euclidean Distance Transform (EDT)-based environment representation with a sampling-based model predictive control (SMPC) planner. On the mapping side, a dense distance-field-based representation is constructed using a GPU-based EDT and augmented with a robot-masked update mechanism to prevent false self-collision detections during online perception. On the planning side, motion generation is formulated as a stochastic optimization problem with a unified objective function and efficiently solved by evaluating large batches of candidate rollouts in parallel within a SMPC framework, in which a geometrically consistent pose tracking metric defined on SE(3) is incorporated to ensure fast and accurate convergence to the target pose. The entire mapping and planning pipeline is implemented on the GPU to support high-frequency replanning. The effectiveness of the proposed framework is validated through extensive simulations and real-world experiments on a 7-DoF robotic manipulator. More details are available at: https://zxw610.github.io/ParaMaP.
YOPO-Rally: A Sim-to-Real Single-Stage Planner for Off-Road Terrain
May 24, 2025Off-road navigation remains challenging for autonomous robots due to the harsh terrain and clustered obstacles. In this letter, we extend the YOPO (You Only Plan Once) end-to-end navigation framework to off-road environments, explicitly focusing on forest terrains, consisting of a high-performance, multi-sensor supported off-road simulator YOPO-Sim, a zero-shot transfer sim-to-real planner YOPO-Rally, and an MPC controller. Built on the Unity engine, the simulator can generate randomized forest environments and export depth images and point cloud maps for expert demonstrations, providing competitive performance with mainstream simulators. Terrain Traversability Analysis (TTA) processes cost maps, generating expert trajectories represented as non-uniform cubic Hermite curves. The planner integrates TTA and the pathfinding into a single neural network that inputs the depth image, current velocity, and the goal vector, and outputs multiple trajectory candidates with costs. The planner is trained by behavior cloning in the simulator and deployed directly into the real-world without fine-tuning. Finally, a series of simulated and real-world experiments is conducted to validate the performance of the proposed framework.
YOPOv2-Tracker: An End-to-End Agile Tracking and Navigation Framework from Perception to Action
May 11, 2025Traditional target tracking pipelines including detection, mapping, navigation, and control are comprehensive but introduce high latency, limitting the agility of quadrotors. On the contrary, we follow the design principle of "less is more", striving to simplify the process while maintaining effectiveness. In this work, we propose an end-to-end agile tracking and navigation framework for quadrotors that directly maps the sensory observations to control commands. Importantly, leveraging the multimodal nature of navigation and detection tasks, our network maintains interpretability by explicitly integrating the independent modules of the traditional pipeline, rather than a crude action regression. In detail, we adopt a set of motion primitives as anchors to cover the searching space regarding the feasible region and potential target. Then we reformulate the trajectory optimization as regression of primitive offsets and associated costs considering the safety, smoothness, and other metrics. For tracking task, the trajectories are expected to approach the target and additional objectness scores are predicted. Subsequently, the predictions, after compensation for the estimated lumped disturbance, are transformed into thrust and attitude as control commands for swift response. During training, we seamlessly integrate traditional motion planning with deep learning by directly back-propagating the gradients of trajectory costs to the network, eliminating the need for expert demonstration in imitation learning and providing more direct guidance than reinforcement learning. Finally, we deploy the algorithm on a compact quadrotor and conduct real-world validations in both forest and building environments to demonstrate the efficiency of the proposed method.
Sampling-Based Hierarchical Trajectory Planning for Formation Flight
Jul 24, 2024Formation flight of unmanned aerial vehicles (UAVs) poses significant challenges in terms of safety and formation keeping, particularly in cluttered environments. However, existing methods often struggle to simultaneously satisfy these two critical requirements. To address this issue, this paper proposes a sampling-based trajectory planning method with a hierarchical structure for formation flight in dense obstacle environments. To ensure reliable local sensing information sharing among UAVs, each UAV generates a safe flight corridor (SFC), which is transmitted to the leader UAV. Subsequently, a sampling-based formation guidance path generation method is designed as the front-end strategy, steering the formation to fly in the desired shape safely with the formation connectivity provided by the SFCs. Furthermore, a model predictive path integral (MPPI) based distributed trajectory optimization method is developed as the back-end part, which ensures the smoothness, safety and dynamics feasibility of the executable trajectory. To validate the efficiency of the developed algorithm, comprehensive simulation comparisons are conducted. The supplementary simulation video can be seen at https://www.youtube.com/watch?v=xSxbUN0tn1M.
Analysis and Optimization of Service Delay for Multi-quality Videos in Multi-tier Heterogeneous Network with Random Caching
Jul 21, 2020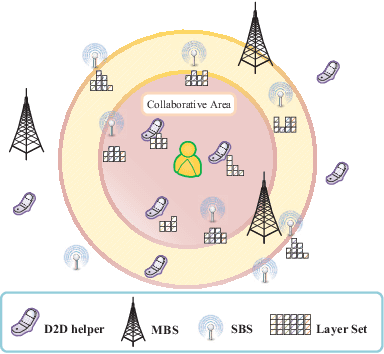
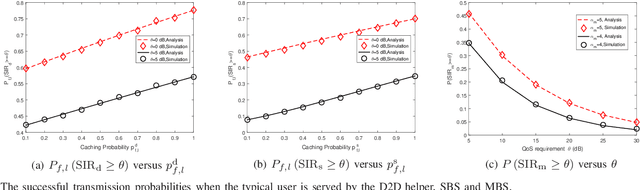
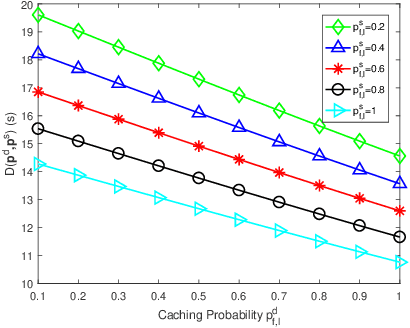
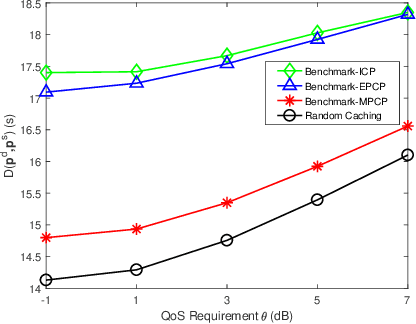
Aiming to minimize service delay, we propose a new random caching scheme in device-to-device (D2D)-assisted heterogeneous network. To support diversified viewing qualities of multimedia video services, each video file is encoded into a base layer (BL) and multiple enhancement layers (ELs) by scalable video coding (SVC). A super layer, including the BL and several ELs, is transmitted to every user. We define and quantify the service delay of multi-quality videos by deriving successful transmission probabilities when a user is served by a D2D helper, a small-cell base station (SBS) and a macro-cell base station (MBS). We formulate a delay minimization problem subject to the limited cache sizes of D2D helpers and SBSs. The structure of the optimal solutions to the problem is revealed, and then an improved standard gradient projection method is designed to effectively obtain the solutions. Both theoretical analysis and Monte-Carlo simulations validate the successful transmission probabilities. Compared with three benchmark caching policies, the proposed SVC-based random caching scheme is superior in terms of reducing the service delay.
Deep Speaker: an End-to-End Neural Speaker Embedding System
May 05, 2017
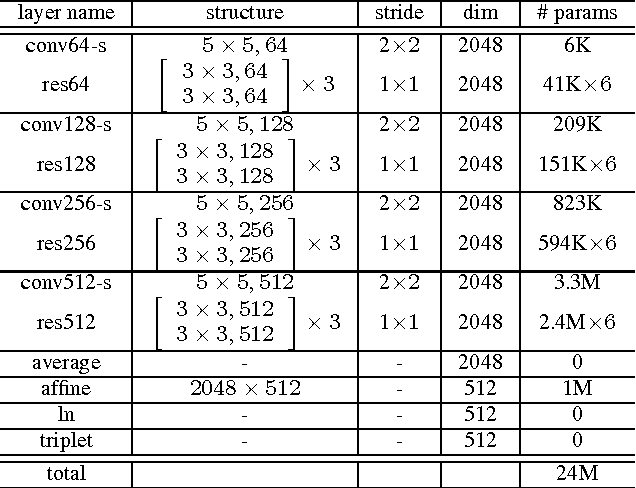
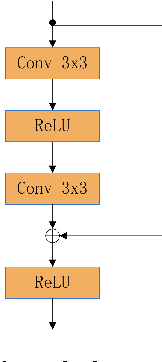
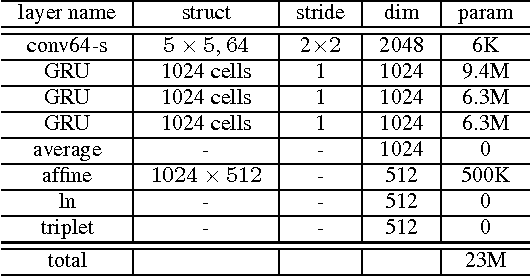
We present Deep Speaker, a neural speaker embedding system that maps utterances to a hypersphere where speaker similarity is measured by cosine similarity. The embeddings generated by Deep Speaker can be used for many tasks, including speaker identification, verification, and clustering. We experiment with ResCNN and GRU architectures to extract the acoustic features, then mean pool to produce utterance-level speaker embeddings, and train using triplet loss based on cosine similarity. Experiments on three distinct datasets suggest that Deep Speaker outperforms a DNN-based i-vector baseline. For example, Deep Speaker reduces the verification equal error rate by 50% (relatively) and improves the identification accuracy by 60% (relatively) on a text-independent dataset. We also present results that suggest adapting from a model trained with Mandarin can improve accuracy for English speaker recognition.
THCHS-30 : A Free Chinese Speech Corpus
Dec 10, 2015
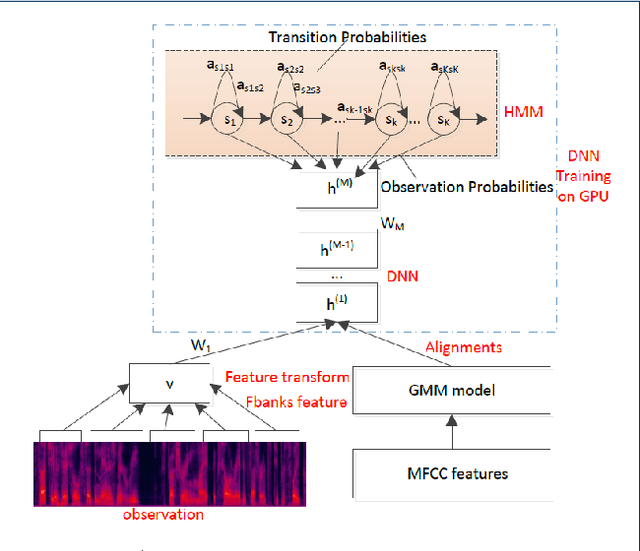
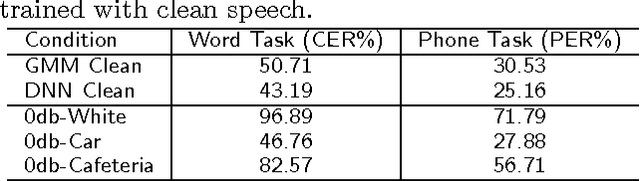
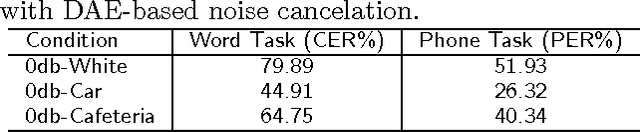
Speech data is crucially important for speech recognition research. There are quite some speech databases that can be purchased at prices that are reasonable for most research institutes. However, for young people who just start research activities or those who just gain initial interest in this direction, the cost for data is still an annoying barrier. We support the `free data' movement in speech recognition: research institutes (particularly supported by public funds) publish their data freely so that new researchers can obtain sufficient data to kick of their career. In this paper, we follow this trend and release a free Chinese speech database THCHS-30 that can be used to build a full- edged Chinese speech recognition system. We report the baseline system established with this database, including the performance under highly noisy conditions.