 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoTemp-o3: Harmonizing Temporal Grounding and Video Understanding in Agentic Thinking-with-Videos
Feb 08, 2026In long-video understanding, conventional uniform frame sampling often fails to capture key visual evidence, leading to degraded performance and increased hallucinations. To address this, recent agentic thinking-with-videos paradigms have emerged, adopting a localize-clip-answer pipeline in which the model actively identifies relevant video segments, performs dense sampling within those clips, and then produces answers. However, existing methods remain inefficient, suffer from weak localization, and adhere to rigid workflows. To solve these issues, we propose VideoTemp-o3, a unified agentic thinking-with-videos framework that jointly models video grounding and question answering. VideoTemp-o3 exhibits strong localization capability, supports on-demand clipping, and can refine inaccurate localizations. Specifically, in the supervised fine-tuning stage, we design a unified masking mechanism that encourages exploration while preventing noise. For reinforcement learning, we introduce dedicated rewards to mitigate reward hacking. Besides, from the data perspective, we develop an effective pipeline to construct high-quality long video grounded QA data, along with a corresponding benchmark for systematic evaluation across various video durations. Experimental results demonstrate that our method achieves remarkable performance on both long video understanding and grounding.
Dual Knowledge-Enhanced Two-Stage Reasoner for Multimodal Dialog Systems
Sep 09, 2025



Textual response generation is pivotal for multimodal \mbox{task-oriented} dialog systems, which aims to generate proper textual responses based on the multimodal context. While existing efforts have demonstrated remarkable progress, there still exist the following limitations: 1) \textit{neglect of unstructured review knowledge} and 2) \textit{underutilization of large language models (LLMs)}. Inspired by this, we aim to fully utilize dual knowledge (\textit{i.e., } structured attribute and unstructured review knowledge) with LLMs to promote textual response generation in multimodal task-oriented dialog systems. However, this task is non-trivial due to two key challenges: 1) \textit{dynamic knowledge type selection} and 2) \textit{intention-response decoupling}. To address these challenges, we propose a novel dual knowledge-enhanced two-stage reasoner by adapting LLMs for multimodal dialog systems (named DK2R). To be specific, DK2R first extracts both structured attribute and unstructured review knowledge from external knowledge base given the dialog context. Thereafter, DK2R uses an LLM to evaluate each knowledge type's utility by analyzing LLM-generated provisional probe responses. Moreover, DK2R separately summarizes the intention-oriented key clues via dedicated reasoning, which are further used as auxiliary signals to enhance LLM-based textual response generation. Extensive experiments conducted on a public dataset verify the superiority of DK2R. We have released the codes and parameters.
Mitigating Hallucination Through Theory-Consistent Symmetric Multimodal Preference Optimization
Jun 13, 2025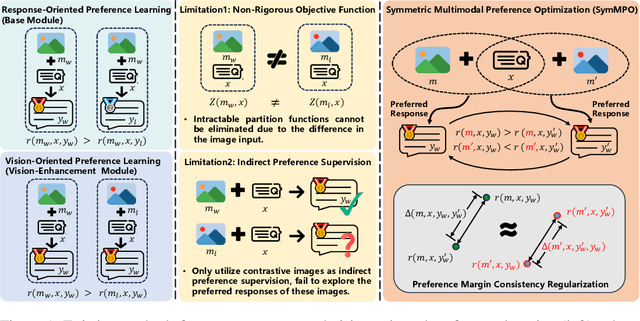


Direct Preference Optimization (DPO) has emerged as an effective approach for mitigating hallucination in Multimodal Large Language Models (MLLMs). Although existing methods have achieved significant progress by utilizing vision-oriented contrastive objectives for enhancing MLLMs' attention to visual inputs and hence reducing hallucination, they suffer from non-rigorous optimization objective function and indirect preference supervision. To address these limitations, we propose a Symmetric Multimodal Preference Optimization (SymMPO), which conducts symmetric preference learning with direct preference supervision (i.e., response pairs) for visual understanding enhancement, while maintaining rigorous theoretical alignment with standard DPO. In addition to conventional ordinal preference learning, SymMPO introduces a preference margin consistency loss to quantitatively regulate the preference gap between symmetric preference pairs. Comprehensive evaluation across five benchmarks demonstrate SymMPO's superior performance, validating its effectiveness in hallucination mitigation of MLLMs.
Modality Reliability Guided Multimodal Recommendation
Apr 23, 2025



Multimodal recommendation faces an issue of the performance degradation that the uni-modal recommendation sometimes achieves the better performance. A possible reason is that the unreliable item modality data hurts the fusion result. Several existing studies have introduced weights for different modalities to reduce the contribution of the unreliable modality data in predicting the final user rating. However, they fail to provide appropriate supervisions for learning the modality weights, making the learned weights imprecise. Therefore, we propose a modality reliability guided multimodal recommendation framework that uniquely learns the modality weights supervised by the modality reliability. Considering that there is no explicit label provided for modality reliability, we resort to automatically identify it through the BPR recommendation objective. In particular, we define a modality reliability vector as the supervision label by the difference between modality-specific user ratings to positive and negative items, where a larger difference indicates a higher reliability of the modality as the BPR objective is better satisfied. Furthermore, to enhance the effectiveness of the supervision, we calculate the confidence level for the modality reliability vector, which dynamically adjusts the supervision strength and eliminates the harmful supervision. Extensive experiments on three real-world datasets show the effectiveness of the proposed method.
Fine-grained Textual Inversion Network for Zero-Shot Composed Image Retrieval
Mar 25, 2025Composed Image Retrieval (CIR) allows users to search target images with a multimodal query, comprising a reference image and a modification text that describes the user's modification demand over the reference image. Nevertheless, due to the expensive labor cost of training data annotation, recent researchers have shifted to the challenging task of zero-shot CIR (ZS-CIR), which targets fulfilling CIR without annotated triplets. The pioneer ZS-CIR studies focus on converting the CIR task into a standard text-to-image retrieval task by pre-training a textual inversion network that can map a given image into a single pseudo-word token. Despite their significant progress, their coarse-grained textual inversion may be insufficient to capture the full content of the image accurately. To overcome this issue, in this work, we propose a novel Fine-grained Textual Inversion Network for ZS-CIR, named FTI4CIR. In particular, FTI4CIR comprises two main components: fine-grained pseudo-word token mapping and tri-wise caption-based semantic regularization. The former maps the image into a subject-oriented pseudo-word token and several attribute-oriented pseudo-word tokens to comprehensively express the image in the textual form, while the latter works on jointly aligning the fine-grained pseudo-word tokens to the real-word token embedding space based on a BLIP-generated image caption template. Extensive experiments conducted on three benchmark datasets demonstrate the superiority of our proposed method.
A Comprehensive Survey on Composed Image Retrieval
Feb 19, 2025



Composed Image Retrieval (CIR) is an emerging yet challenging task that allows users to search for target images using a multimodal query, comprising a reference image and a modification text specifying the user's desired changes to the reference image. Given its significant academic and practical value, CIR has become a rapidly growing area of interest in the computer vision and machine learning communities, particularly with the advances in deep learning. To the best of our knowledge, there is currently no comprehensive review of CIR to provide a timely overview of this field. Therefore, we synthesize insights from over 120 publications in top conferences and journals, including ACM TOIS, SIGIR, and CVPR In particular, we systematically categorize existing supervised CIR and zero-shot CIR models using a fine-grained taxonomy. For a comprehensive review, we also briefly discuss approaches for tasks closely related to CIR, such as attribute-based CIR and dialog-based CIR. Additionally, we summarize benchmark datasets for evaluation and analyze existing supervised and zero-shot CIR methods by comparing experimental results across multiple datasets. Furthermore, we present promising future directions in this field, offering practical insights for researchers interested in further exploration.
Content-aware Balanced Spectrum Encoding in Masked Modeling for Time Series Classification
Dec 17, 2024



Due to the superior ability of global dependency, transformer and its variants have become the primary choice in Masked Time-series Modeling (MTM) towards time-series classification task. In this paper, we experimentally analyze that existing transformer-based MTM methods encounter with two under-explored issues when dealing with time series data: (1) they encode features by performing long-dependency ensemble averaging, which easily results in rank collapse and feature homogenization as the layer goes deeper; (2) they exhibit distinct priorities in fitting different frequency components contained in the time-series, inevitably leading to spectrum energy imbalance of encoded feature. To tackle these issues, we propose an auxiliary content-aware balanced decoder (CBD) to optimize the encoding quality in the spectrum space within masked modeling scheme. Specifically, the CBD iterates on a series of fundamental blocks, and thanks to two tailored units, each block could progressively refine the masked representation via adjusting the interaction pattern based on local content variations of time-series and learning to recalibrate the energy distribution across different frequency components. Moreover, a dual-constraint loss is devised to enhance the mutual optimization of vanilla decoder and our CBD. Extensive experimental results on ten time-series classification datasets show that our method nearly surpasses a bunch of baselines. Meanwhile, a series of explanatory results are showcased to sufficiently demystify the behaviors of our method.
Vision-guided and Mask-enhanced Adaptive Denoising for Prompt-based Image Editing
Oct 14, 2024



Text-to-image diffusion models have demonstrated remarkable progress in synthesizing high-quality images from text prompts, which boosts researches on prompt-based image editing that edits a source image according to a target prompt. Despite their advances, existing methods still encounter three key issues: 1) limited capacity of the text prompt in guiding target image generation, 2) insufficient mining of word-to-patch and patch-to-patch relationships for grounding editing areas, and 3) unified editing strength for all regions during each denoising step. To address these issues, we present a Vision-guided and Mask-enhanced Adaptive Editing (ViMAEdit) method with three key novel designs. First, we propose to leverage image embeddings as explicit guidance to enhance the conventional textual prompt-based denoising process, where a CLIP-based target image embedding estimation strategy is introduced. Second, we devise a self-attention-guided iterative editing area grounding strategy, which iteratively exploits patch-to-patch relationships conveyed by self-attention maps to refine those word-to-patch relationships contained in cross-attention maps. Last, we present a spatially adaptive variance-guided sampling, which highlights sampling variances for critical image regions to promote the editing capability. Experimental results demonstrate the superior editing capacity of ViMAEdit over all existing methods.
Pseudo-triplet Guided Few-shot Composed Image Retrieval
Jul 08, 2024



Composed Image Retrieval (CIR) is a challenging task that aims to retrieve the target image based on a multimodal query, i.e., a reference image and its corresponding modification text. While previous supervised or zero-shot learning paradigms all fail to strike a good trade-off between time-consuming annotation cost and retrieval performance, recent researchers introduced the task of few-shot CIR (FS-CIR) and proposed a textual inversion-based network based on pretrained CLIP model to realize it. Despite its promising performance, the approach suffers from two key limitations: insufficient multimodal query composition training and indiscriminative training triplet selection. To address these two limitations, in this work, we propose a novel two-stage pseudo triplet guided few-shot CIR scheme, dubbed PTG-FSCIR. In the first stage, we employ a masked training strategy and advanced image caption generator to construct pseudo triplets from pure image data to enable the model to acquire primary knowledge related to multimodal query composition. In the second stage, based on active learning, we design a pseudo modification text-based query-target distance metric to evaluate the challenging score for each unlabeled sample. Meanwhile, we propose a robust top range-based random sampling strategy according to the 3-$\sigma$ rule in statistics, to sample the challenging samples for fine-tuning the pretrained model. Notably, our scheme is plug-and-play and compatible with any existing supervised CIR models. We tested our scheme across three backbones on three public datasets (i.e., FashionIQ, CIRR, and Birds-to-Words), achieving maximum improvements of 26.4%, 25.5% and 21.6% respectively, demonstrating our scheme's effectiveness.
MMGRec: Multimodal Generative Recommendation with Transformer Model
Apr 25, 2024Multimodal recommendation aims to recommend user-preferred candidates based on her/his historically interacted items and associated multimodal information. Previous studies commonly employ an embed-and-retrieve paradigm: learning user and item representations in the same embedding space, then retrieving similar candidate items for a user via embedding inner product. However, this paradigm suffers from inference cost, interaction modeling, and false-negative issues. Toward this end, we propose a new MMGRec model to introduce a generative paradigm into multimodal recommendation. Specifically, we first devise a hierarchical quantization method Graph RQ-VAE to assign Rec-ID for each item from its multimodal and CF information. Consisting of a tuple of semantically meaningful tokens, Rec-ID serves as the unique identifier of each item. Afterward, we train a Transformer-based recommender to generate the Rec-IDs of user-preferred items based on historical interaction sequences. The generative paradigm is qualified since this model systematically predicts the tuple of tokens identifying the recommended item in an autoregressive manner. Moreover, a relation-aware self-attention mechanism is devised for the Transformer to handle non-sequential interaction sequences, which explores the element pairwise relation to replace absolute positional encoding. Extensive experiments evaluate MMGRec's effectiveness compared with state-of-the-art methods.