 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModality Reliability Guided Multimodal Recommendation
Apr 23, 2025



Multimodal recommendation faces an issue of the performance degradation that the uni-modal recommendation sometimes achieves the better performance. A possible reason is that the unreliable item modality data hurts the fusion result. Several existing studies have introduced weights for different modalities to reduce the contribution of the unreliable modality data in predicting the final user rating. However, they fail to provide appropriate supervisions for learning the modality weights, making the learned weights imprecise. Therefore, we propose a modality reliability guided multimodal recommendation framework that uniquely learns the modality weights supervised by the modality reliability. Considering that there is no explicit label provided for modality reliability, we resort to automatically identify it through the BPR recommendation objective. In particular, we define a modality reliability vector as the supervision label by the difference between modality-specific user ratings to positive and negative items, where a larger difference indicates a higher reliability of the modality as the BPR objective is better satisfied. Furthermore, to enhance the effectiveness of the supervision, we calculate the confidence level for the modality reliability vector, which dynamically adjusts the supervision strength and eliminates the harmful supervision. Extensive experiments on three real-world datasets show the effectiveness of the proposed method.
Preview-based Category Contrastive Learning for Knowledge Distillation
Oct 18, 2024Knowledge distillation is a mainstream algorithm in model compression by transferring knowledge from the larger model (teacher) to the smaller model (student) to improve the performance of student. Despite many efforts, existing methods mainly investigate the consistency between instance-level feature representation or prediction, which neglects the category-level information and the difficulty of each sample, leading to undesirable performance. To address these issues, we propose a novel preview-based category contrastive learning method for knowledge distillation (PCKD). It first distills the structural knowledge of both instance-level feature correspondence and the relation between instance features and category centers in a contrastive learning fashion, which can explicitly optimize the category representation and explore the distinct correlation between representations of instances and categories, contributing to discriminative category centers and better classification results. Besides, we introduce a novel preview strategy to dynamically determine how much the student should learn from each sample according to their difficulty. Different from existing methods that treat all samples equally and curriculum learning that simply filters out hard samples, our method assigns a small weight for hard instances as a preview to better guide the student training. Extensive experiments on several challenging datasets, including CIFAR-100 and ImageNet, demonstrate the superiority over state-of-the-art methods.
Tele-Aloha: A Low-budget and High-authenticity Telepresence System Using Sparse RGB Cameras
May 23, 2024



In this paper, we present a low-budget and high-authenticity bidirectional telepresence system, Tele-Aloha, targeting peer-to-peer communication scenarios. Compared to previous systems, Tele-Aloha utilizes only four sparse RGB cameras, one consumer-grade GPU, and one autostereoscopic screen to achieve high-resolution (2048x2048), real-time (30 fps), low-latency (less than 150ms) and robust distant communication. As the core of Tele-Aloha, we propose an efficient novel view synthesis algorithm for upper-body. Firstly, we design a cascaded disparity estimator for obtaining a robust geometry cue. Additionally a neural rasterizer via Gaussian Splatting is introduced to project latent features onto target view and to decode them into a reduced resolution. Further, given the high-quality captured data, we leverage weighted blending mechanism to refine the decoded image into the final resolution of 2K. Exploiting world-leading autostereoscopic display and low-latency iris tracking, users are able to experience a strong three-dimensional sense even without any wearable head-mounted display device. Altogether, our telepresence system demonstrates the sense of co-presence in real-life experiments, inspiring the next generation of communication.
Prompt-based Multi-interest Learning Method for Sequential Recommendation
Jan 09, 2024



Multi-interest learning method for sequential recommendation aims to predict the next item according to user multi-faceted interests given the user historical interactions. Existing methods mainly consist of two modules: the multi-interest extraction module that learns user multi-interest embeddings to capture the user multi-interests, and the multi-interest weight prediction module that learns the weight of each interest for aggregating the learned multi-interest embeddings to derive the user embedding, used for predicting the user rating to an item. Despite their effectiveness, existing methods have two key limitations: 1) they directly feed the user interactions into the two modules, while ignoring their different learning objectives, and 2) they merely consider the centrality of the user interactions to learn the user multi-interests, while overlooking their dispersion. To tackle these limitations, we propose a prompt-based multi-interest learning method (PoMRec), where specific prompts are inserted into user interactions to make them adaptive to different learning objectives of the two modules. Moreover, we utilize both the mean and variance embeddings of user interactions to derive the user multi-interest embeddings for comprehensively model the user multi-interests. We conduct extensive experiments on two public datasets, and the results verify that our proposed PoMRec outperforms the state-of-the-art multi-interest learning methods.
Divide and Conquer: Towards Better Embedding-based Retrieval for Recommender Systems From a Multi-task Perspective
Feb 06, 2023



Embedding-based retrieval (EBR) methods are widely used in modern recommender systems thanks to its simplicity and effectiveness. However, along the journey of deploying and iterating on EBR in production, we still identify some fundamental issues in existing methods. First, when dealing with large corpus of candidate items, EBR models often have difficulties in balancing the performance on distinguishing highly relevant items (positives) from both irrelevant ones (easy negatives) and from somewhat related yet not competitive ones (hard negatives). Also, we have little control in the diversity and fairness of the retrieval results because of the ``greedy'' nature of nearest vector search. These issues compromise the performance of EBR methods in large-scale industrial scenarios. This paper introduces a simple and proven-in-production solution to overcome these issues. The proposed solution takes a divide-and-conquer approach: the whole set of candidate items are divided into multiple clusters and we run EBR to retrieve relevant candidates from each cluster in parallel; top candidates from each cluster are then combined by some controllable merging strategies. This approach allows our EBR models to only concentrate on discriminating positives from mostly hard negatives. It also enables further improvement from a multi-tasking learning (MTL) perspective: retrieval problems within each cluster can be regarded as individual tasks; inspired by recent successes in prompting and prefix-tuning, we propose an efficient task adaption technique further boosting the retrieval performance within each cluster with negligible overheads.
Latent Evolution Model for Change Point Detection in Time-varying Networks
Dec 17, 2022



Graph-based change point detection (CPD) play an irreplaceable role in discovering anomalous graphs in the time-varying network. While several techniques have been proposed to detect change points by identifying whether there is a significant difference between the target network and successive previous ones, they neglect the natural evolution of the network. In practice, real-world graphs such as social networks, traffic networks, and rating networks are constantly evolving over time. Considering this problem, we treat the problem as a prediction task and propose a novel CPD method for dynamic graphs via a latent evolution model. Our method focuses on learning the low-dimensional representations of networks and capturing the evolving patterns of these learned latent representations simultaneously. After having the evolving patterns, a prediction of the target network can be achieved. Then, we can detect the change points by comparing the prediction and the actual network by leveraging a trade-off strategy, which balances the importance between the prediction network and the normal graph pattern extracted from previous networks. Intensive experiments conducted on both synthetic and real-world datasets show the effectiveness and superiority of our model.
Dual Preference Distribution Learning for Item Recommendation
Jan 24, 2022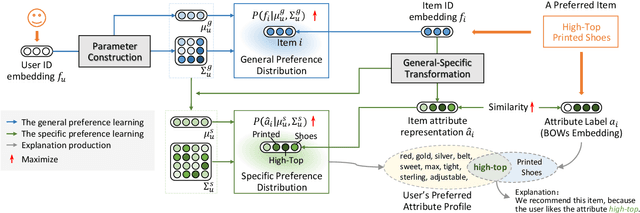
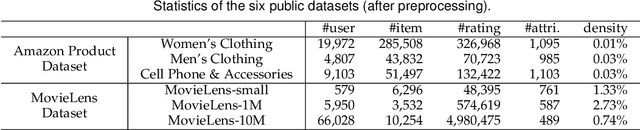
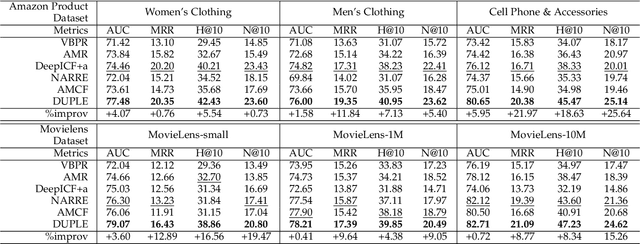
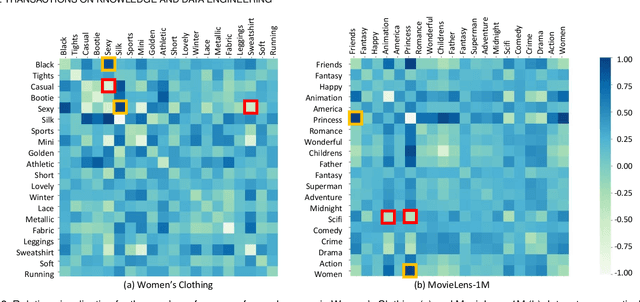
Recommender systems can automatically recommend users items that they probably like, for which the goal is to represent the user and item as well as model their interaction. Existing methods have primarily learned the user's preferences and item's features with vectorized representations, and modeled the user-item interaction by the similarity of their representations. In fact, the user's different preferences are related and capturing such relations could better understand the user's preferences for a better recommendation. Toward this end, we propose to represent the user's preference with multi-variant Gaussian distribution, and model the user-item interaction by calculating the probability density at the item in the user's preference distribution. In this manner, the mean vector of the Gaussian distribution is able to capture the center of the user's preferences, while its covariance matrix captures the relations of these preferences. In particular, in this work, we propose a dual preference distribution learning framework (DUPLE), which captures the user's preferences to both the items and attributes by a Gaussian distribution, respectively. As a byproduct, identifying the user's preference to specific attributes enables us to provide the explanation of recommending an item to the user. Extensive quantitative and qualitative experiments on six public datasets show that DUPLE achieves the best performance over all state-of-the-art recommendation methods.