 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE-RNN: Design Optimization for Efficient Recurrent Neural Networks in FPGAs
Dec 12, 2018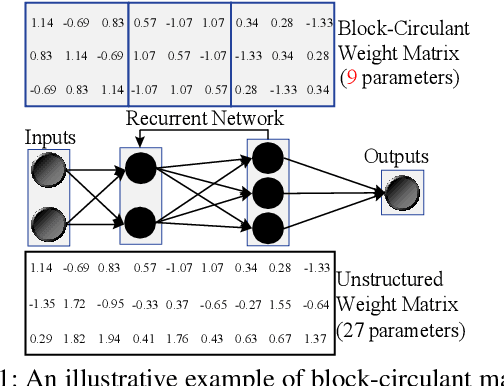

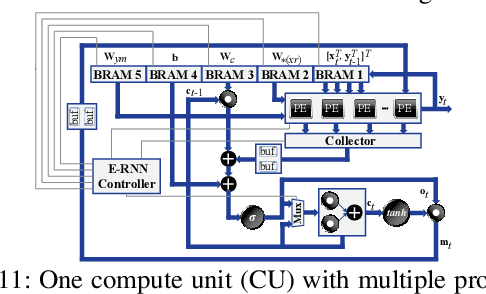
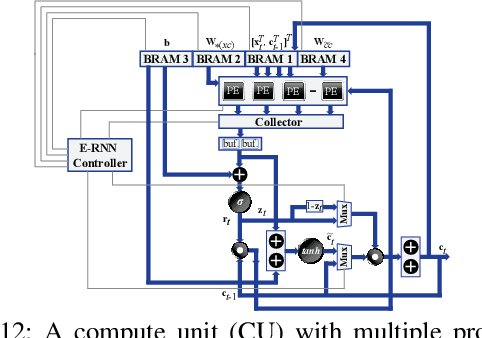
Recurrent Neural Networks (RNNs) are becoming increasingly important for time series-related applications which require efficient and real-time implementations. The two major types are Long Short-Term Memory (LSTM) and Gated Recurrent Unit (GRU) networks. It is a challenging task to have real-time, efficient, and accurate hardware RNN implementations because of the high sensitivity to imprecision accumulation and the requirement of special activation function implementations. A key limitation of the prior works is the lack of a systematic design optimization framework of RNN model and hardware implementations, especially when the block size (or compression ratio) should be jointly optimized with RNN type, layer size, etc. In this paper, we adopt the block-circulant matrix-based framework, and present the Efficient RNN (E-RNN) framework for FPGA implementations of the Automatic Speech Recognition (ASR) application. The overall goal is to improve performance/energy efficiency under accuracy requirement. We use the alternating direction method of multipliers (ADMM) technique for more accurate block-circulant training, and present two design explorations providing guidance on block size and reducing RNN training trials. Based on the two observations, we decompose E-RNN in two phases: Phase I on determining RNN model to reduce computation and storage subject to accuracy requirement, and Phase II on hardware implementations given RNN model, including processing element design/optimization, quantization, activation implementation, etc. Experimental results on actual FPGA deployments show that E-RNN achieves a maximum energy efficiency improvement of 37.4$\times$ compared with ESE, and more than 2$\times$ compared with C-LSTM, under the same accuracy.
Towards Ultra-High Performance and Energy Efficiency of Deep Learning Systems: An Algorithm-Hardware Co-Optimization Framework
Feb 18, 2018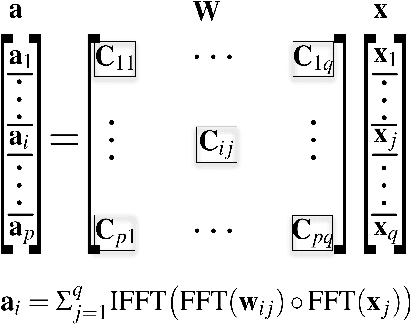
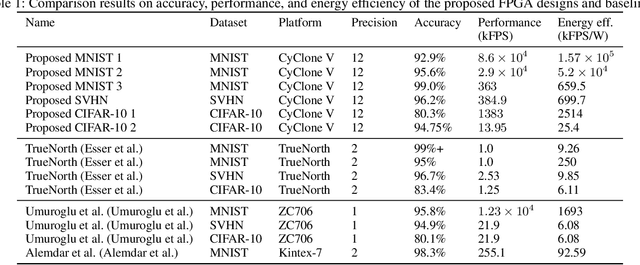
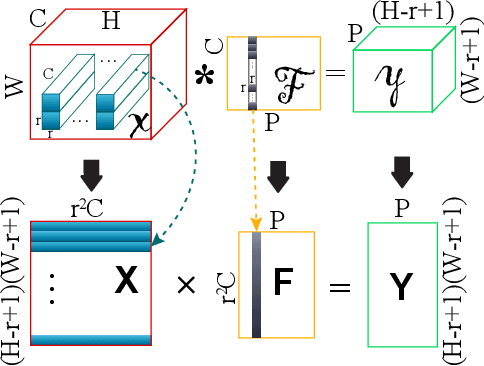
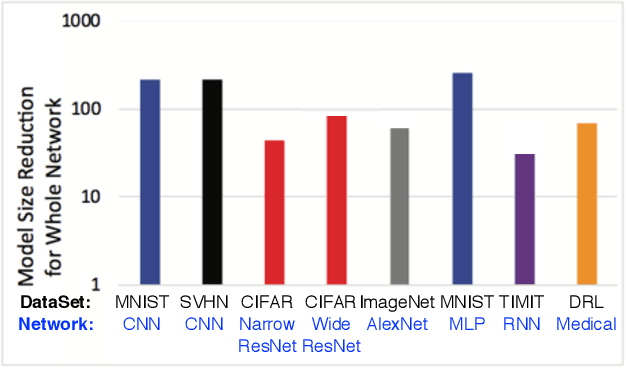
Hardware accelerations of deep learning systems have been extensively investigated in industry and academia. The aim of this paper is to achieve ultra-high energy efficiency and performance for hardware implementations of deep neural networks (DNNs). An algorithm-hardware co-optimization framework is developed, which is applicable to different DNN types, sizes, and application scenarios. The algorithm part adopts the general block-circulant matrices to achieve a fine-grained tradeoff between accuracy and compression ratio. It applies to both fully-connected and convolutional layers and contains a mathematically rigorous proof of the effectiveness of the method. The proposed algorithm reduces computational complexity per layer from O($n^2$) to O($n\log n$) and storage complexity from O($n^2$) to O($n$), both for training and inference. The hardware part consists of highly efficient Field Programmable Gate Array (FPGA)-based implementations using effective reconfiguration, batch processing, deep pipelining, resource re-using, and hierarchical control. Experimental results demonstrate that the proposed framework achieves at least 152X speedup and 71X energy efficiency gain compared with IBM TrueNorth processor under the same test accuracy. It achieves at least 31X energy efficiency gain compared with the reference FPGA-based work.
VIBNN: Hardware Acceleration of Bayesian Neural Networks
Feb 02, 2018
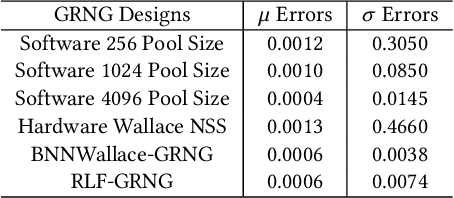
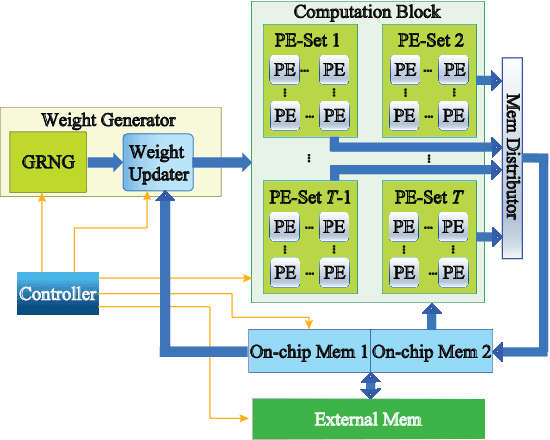
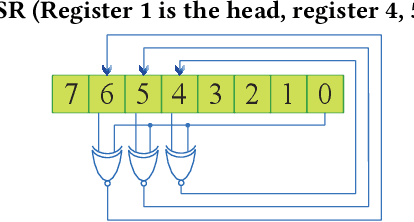
Bayesian Neural Networks (BNNs) have been proposed to address the problem of model uncertainty in training and inference. By introducing weights associated with conditioned probability distributions, BNNs are capable of resolving the overfitting issue commonly seen in conventional neural networks and allow for small-data training, through the variational inference process. Frequent usage of Gaussian random variables in this process requires a properly optimized Gaussian Random Number Generator (GRNG). The high hardware cost of conventional GRNG makes the hardware implementation of BNNs challenging. In this paper, we propose VIBNN, an FPGA-based hardware accelerator design for variational inference on BNNs. We explore the design space for massive amount of Gaussian variable sampling tasks in BNNs. Specifically, we introduce two high performance Gaussian (pseudo) random number generators: the RAM-based Linear Feedback Gaussian Random Number Generator (RLF-GRNG), which is inspired by the properties of binomial distribution and linear feedback logics; and the Bayesian Neural Network-oriented Wallace Gaussian Random Number Generator. To achieve high scalability and efficient memory access, we propose a deep pipelined accelerator architecture with fast execution and good hardware utilization. Experimental results demonstrate that the proposed VIBNN implementations on an FPGA can achieve throughput of 321,543.4 Images/s and energy efficiency upto 52,694.8 Images/J while maintaining similar accuracy as its software counterpart.
CirCNN: Accelerating and Compressing Deep Neural Networks Using Block-CirculantWeight Matrices
Aug 29, 2017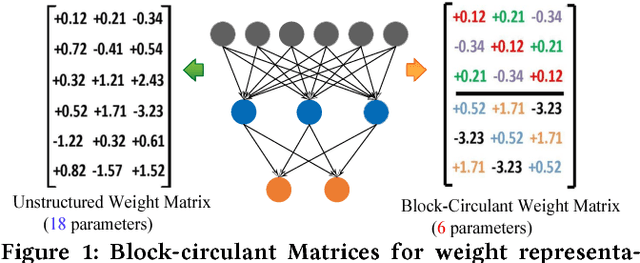
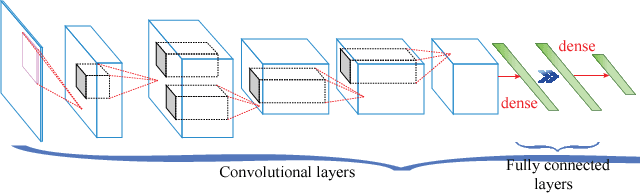
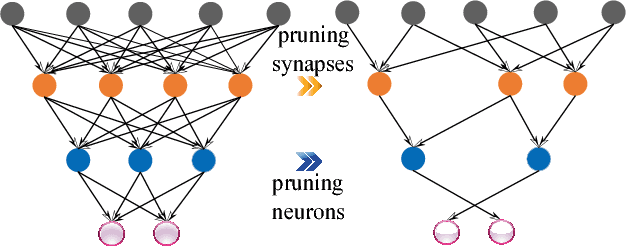
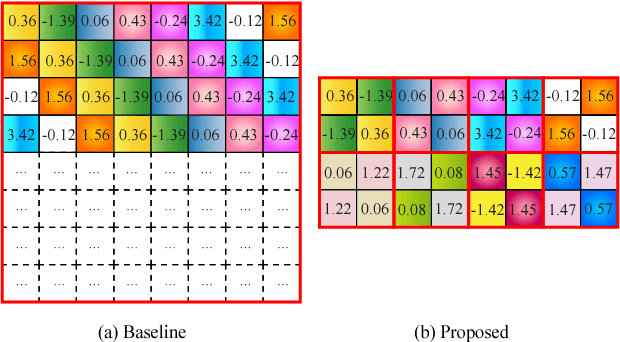
Large-scale deep neural networks (DNNs) are both compute and memory intensive. As the size of DNNs continues to grow, it is critical to improve the energy efficiency and performance while maintaining accuracy. For DNNs, the model size is an important factor affecting performance, scalability and energy efficiency. Weight pruning achieves good compression ratios but suffers from three drawbacks: 1) the irregular network structure after pruning; 2) the increased training complexity; and 3) the lack of rigorous guarantee of compression ratio and inference accuracy. To overcome these limitations, this paper proposes CirCNN, a principled approach to represent weights and process neural networks using block-circulant matrices. CirCNN utilizes the Fast Fourier Transform (FFT)-based fast multiplication, simultaneously reducing the computational complexity (both in inference and training) from O(n2) to O(nlogn) and the storage complexity from O(n2) to O(n), with negligible accuracy loss. Compared to other approaches, CirCNN is distinct due to its mathematical rigor: it can converge to the same effectiveness as DNNs without compression. The CirCNN architecture, a universal DNN inference engine that can be implemented on various hardware/software platforms with configurable network architecture. To demonstrate the performance and energy efficiency, we test CirCNN in FPGA, ASIC and embedded processors. Our results show that CirCNN architecture achieves very high energy efficiency and performance with a small hardware footprint. Based on the FPGA implementation and ASIC synthesis results, CirCNN achieves 6-102X energy efficiency improvements compared with the best state-of-the-art results.
SC-DCNN: Highly-Scalable Deep Convolutional Neural Network using Stochastic Computing
Jan 31, 2017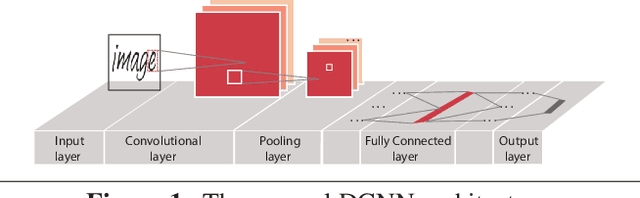
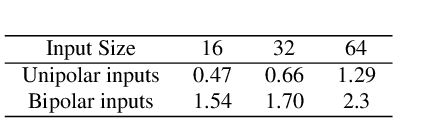
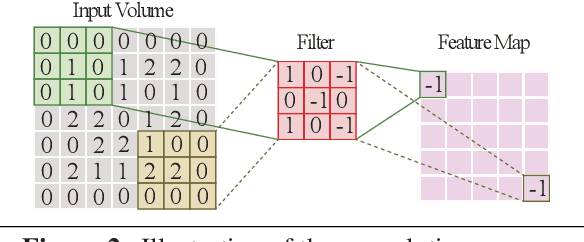
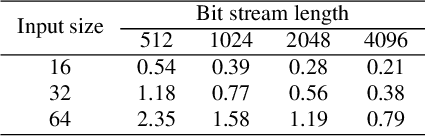
With recent advancing of Internet of Things (IoTs), it becomes very attractive to implement the deep convolutional neural networks (DCNNs) onto embedded/portable systems. Presently, executing the software-based DCNNs requires high-performance server clusters in practice, restricting their widespread deployment on the mobile devices. To overcome this issue, considerable research efforts have been conducted in the context of developing highly-parallel and specific DCNN hardware, utilizing GPGPUs, FPGAs, and ASICs. Stochastic Computing (SC), which uses bit-stream to represent a number within [-1, 1] by counting the number of ones in the bit-stream, has a high potential for implementing DCNNs with high scalability and ultra-low hardware footprint. Since multiplications and additions can be calculated using AND gates and multiplexers in SC, significant reductions in power/energy and hardware footprint can be achieved compared to the conventional binary arithmetic implementations. The tremendous savings in power (energy) and hardware resources bring about immense design space for enhancing scalability and robustness for hardware DCNNs. This paper presents the first comprehensive design and optimization framework of SC-based DCNNs (SC-DCNNs). We first present the optimal designs of function blocks that perform the basic operations, i.e., inner product, pooling, and activation function. Then we propose the optimal design of four types of combinations of basic function blocks, named feature extraction blocks, which are in charge of extracting features from input feature maps. Besides, weight storage methods are investigated to reduce the area and power/energy consumption for storing weights. Finally, the whole SC-DCNN implementation is optimized, with feature extraction blocks carefully selected, to minimize area and power/energy consumption while maintaining a high network accuracy level.