 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributionally Robust Set Representation Learning Under Inference-Time Element Corruption
May 28, 2026Standard Set Representation Learning methods typically excel on curated data but often overlook the challenge of inference-time element corruption. This refers to scenarios where deployed models encounter element-level degradations, such as outliers or missing components, that may distort set representation and degrade performance. We propose SW-DRSO, a distributionally robust optimization framework tailored for sets. Rather than minimizing loss solely on observed training data, SW-DRSO optimizes a tractable surrogate of the worst-case expected loss over a family of plausible inference-time variations. We introduce a barycentric adversary that approximates the intractable search over corrupted sets by a differentiable training-time optimization over simplex weights. Extensive experiments across four tasks demonstrate that SW-DRSO effectively enhances robustness against corruption while maintaining high overall performance.
Insights Generator: Systematic Corpus-Level Trace Diagnostics for LLM Agents
May 21, 2026Diagnosing failures in LLM agents remains largely manual. Practitioners inspect a small subset of execution traces, form ad-hoc hypotheses, and iterate. This process misses patterns that only emerge across trace populations and does not scale to production corpora where individual traces span tens of thousands of tokens. We formalize the problem of corpus-level trace diagnostics. Given a corpus of execution traces, the goal is to produce grounded natural-language insights that characterize systematic behavioral patterns across trace groups, each linked to supporting evidence. We present the Insights Generator (IG), a multi-agent system that answers diagnostic questions by proposing and testing hypotheses across the trace corpus to produce an evidence-backed insights report. We evaluate IG across qualitative and objective dimensions, spanning rubric-based report assessment and downstream performance improvements achieved by implementing IG insights. Human experts using IG reports improve scaffold performance by 30.4pp over the unmodified baseline scaffold, and coding agents leveraging IG-derived insights show consistent and stable gains. Across benchmarks, IG's scout-investigator architecture produces findings comparable in detection coverage to competing approaches, while domain experts rated IG reports as leading depth and evidence quality.
FinReporting: An Agentic Workflow for Localized Reporting of Cross-Jurisdiction Financial Disclosures
Apr 07, 2026Financial reporting systems increasingly use large language models (LLMs) to extract and summarize corporate disclosures. However, most assume a single-market setting and do not address structural differences across jurisdictions. Variations in accounting taxonomies, tagging infrastructures (e.g., XBRL vs. PDF), and aggregation conventions make cross-jurisdiction reporting a semantic alignment and verification challenge. We present FinReporting, an agentic workflow for localized cross-jurisdiction financial reporting. The system builds a unified canonical ontology over Income Statement, Balance Sheet, and Cash Flow, and decomposes reporting into auditable stages including filing acquisition, extraction, canonical mapping, and anomaly logging. Rather than using LLMs as free-form generators, FinReporting deploys them as constrained verifiers under explicit decision rules and evidence grounding. Evaluated on annual filings from the US, Japan, and China, the system improves consistency and reliability under heterogeneous reporting regimes. We release an interactive demo supporting cross-market inspection and structured export of localized financial statements. Our demo is available at https://huggingface.co/spaces/BoomQ/FinReporting-Demo . The video describing our system is available at https://www.youtube.com/watch?v=f65jdEL31Kk
VeRO: An Evaluation Harness for Agents to Optimize Agents
Feb 25, 2026An important emerging application of coding agents is agent optimization: the iterative improvement of a target agent through edit-execute-evaluate cycles. Despite its relevance, the community lacks a systematic understanding of coding agent performance on this task. Agent optimization differs fundamentally from conventional software engineering: the target agent interleaves deterministic code with stochastic LLM completions, requiring structured capture of both intermediate reasoning and downstream execution outcomes. To address these challenges, we introduce VERO (Versioning, Rewards, and Observations), which provides (1) a reproducible evaluation harness with versioned agent snapshots, budget-controlled evaluation, and structured execution traces, and (2) a benchmark suite of target agents and tasks with reference evaluation procedures. Using VERO, we conduct an empirical study comparing optimizer configurations across tasks and analyzing which modifications reliably improve target agent performance. We release VERO to support research on agent optimization as a core capability for coding agents.
Reinforcement Unlearning
Dec 26, 2023



Machine unlearning refers to the process of mitigating the influence of specific training data on machine learning models based on removal requests from data owners. However, one important area that has been largely overlooked in the research of unlearning is reinforcement learning. Reinforcement learning focuses on training an agent to make optimal decisions within an environment to maximize its cumulative rewards. During the training, the agent tends to memorize the features of the environment, which raises a significant concern about privacy. As per data protection regulations, the owner of the environment holds the right to revoke access to the agent's training data, thus necessitating the development of a novel and pressing research field, known as \emph{reinforcement unlearning}. Reinforcement unlearning focuses on revoking entire environments rather than individual data samples. This unique characteristic presents three distinct challenges: 1) how to propose unlearning schemes for environments; 2) how to avoid degrading the agent's performance in remaining environments; and 3) how to evaluate the effectiveness of unlearning. To tackle these challenges, we propose two reinforcement unlearning methods. The first method is based on decremental reinforcement learning, which aims to erase the agent's previously acquired knowledge gradually. The second method leverages environment poisoning attacks, which encourage the agent to learn new, albeit incorrect, knowledge to remove the unlearning environment. Particularly, to tackle the third challenge, we introduce the concept of ``environment inference attack'' to evaluate the unlearning outcomes. The source code is available at \url{https://anonymous.4open.science/r/Reinforcement-Unlearning-D347}.
Explainability-based Backdoor Attacks Against Graph Neural Networks
Apr 08, 2021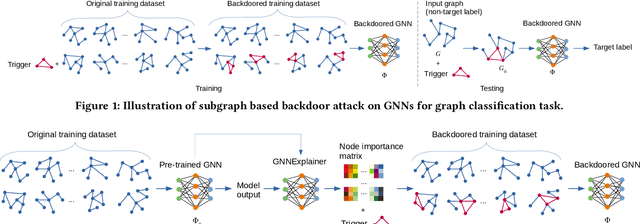



Backdoor attacks represent a serious threat to neural network models. A backdoored model will misclassify the trigger-embedded inputs into an attacker-chosen target label while performing normally on other benign inputs. There are already numerous works on backdoor attacks on neural networks, but only a few works consider graph neural networks (GNNs). As such, there is no intensive research on explaining the impact of trigger injecting position on the performance of backdoor attacks on GNNs. To bridge this gap, we conduct an experimental investigation on the performance of backdoor attacks on GNNs. We apply two powerful GNN explainability approaches to select the optimal trigger injecting position to achieve two attacker objectives -- high attack success rate and low clean accuracy drop. Our empirical results on benchmark datasets and state-of-the-art neural network models demonstrate the proposed method's effectiveness in selecting trigger injecting position for backdoor attacks on GNNs. For instance, on the node classification task, the backdoor attack with trigger injecting position selected by GraphLIME reaches over $84 \%$ attack success rate with less than $2.5 \%$ accuracy drop