 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-Sequential Graph Script Induction via Multimedia Grounding
May 27, 2023Online resources such as WikiHow compile a wide range of scripts for performing everyday tasks, which can assist models in learning to reason about procedures. However, the scripts are always presented in a linear manner, which does not reflect the flexibility displayed by people executing tasks in real life. For example, in the CrossTask Dataset, 64.5% of consecutive step pairs are also observed in the reverse order, suggesting their ordering is not fixed. In addition, each step has an average of 2.56 frequent next steps, demonstrating "branching". In this paper, we propose the new challenging task of non-sequential graph script induction, aiming to capture optional and interchangeable steps in procedural planning. To automate the induction of such graph scripts for given tasks, we propose to take advantage of loosely aligned videos of people performing the tasks. In particular, we design a multimodal framework to ground procedural videos to WikiHow textual steps and thus transform each video into an observed step path on the latent ground truth graph script. This key transformation enables us to train a script knowledge model capable of both generating explicit graph scripts for learnt tasks and predicting future steps given a partial step sequence. Our best model outperforms the strongest pure text/vision baselines by 17.52% absolute gains on F1@3 for next step prediction and 13.8% absolute gains on Acc@1 for partial sequence completion. Human evaluation shows our model outperforming the WikiHow linear baseline by 48.76% absolute gains in capturing sequential and non-sequential step relationships.
Language Models are Causal Knowledge Extractors for Zero-shot Video Question Answering
Apr 07, 2023



Causal Video Question Answering (CVidQA) queries not only association or temporal relations but also causal relations in a video. Existing question synthesis methods pre-trained question generation (QG) systems on reading comprehension datasets with text descriptions as inputs. However, QG models only learn to ask association questions (e.g., ``what is someone doing...'') and result in inferior performance due to the poor transfer of association knowledge to CVidQA, which focuses on causal questions like ``why is someone doing ...''. Observing this, we proposed to exploit causal knowledge to generate question-answer pairs, and proposed a novel framework, Causal Knowledge Extraction from Language Models (CaKE-LM), leveraging causal commonsense knowledge from language models to tackle CVidQA. To extract knowledge from LMs, CaKE-LM generates causal questions containing two events with one triggering another (e.g., ``score a goal'' triggers ``soccer player kicking ball'') by prompting LM with the action (soccer player kicking ball) to retrieve the intention (to score a goal). CaKE-LM significantly outperforms conventional methods by 4% to 6% of zero-shot CVidQA accuracy on NExT-QA and Causal-VidQA datasets. We also conduct comprehensive analyses and provide key findings for future research.
Supervised Masked Knowledge Distillation for Few-Shot Transformers
Mar 29, 2023



Vision Transformers (ViTs) emerge to achieve impressive performance on many data-abundant computer vision tasks by capturing long-range dependencies among local features. However, under few-shot learning (FSL) settings on small datasets with only a few labeled data, ViT tends to overfit and suffers from severe performance degradation due to its absence of CNN-alike inductive bias. Previous works in FSL avoid such problem either through the help of self-supervised auxiliary losses, or through the dextile uses of label information under supervised settings. But the gap between self-supervised and supervised few-shot Transformers is still unfilled. Inspired by recent advances in self-supervised knowledge distillation and masked image modeling (MIM), we propose a novel Supervised Masked Knowledge Distillation model (SMKD) for few-shot Transformers which incorporates label information into self-distillation frameworks. Compared with previous self-supervised methods, we allow intra-class knowledge distillation on both class and patch tokens, and introduce the challenging task of masked patch tokens reconstruction across intra-class images. Experimental results on four few-shot classification benchmark datasets show that our method with simple design outperforms previous methods by a large margin and achieves a new start-of-the-art. Detailed ablation studies confirm the effectiveness of each component of our model. Code for this paper is available here: https://github.com/HL-hanlin/SMKD.
In Defense of Structural Symbolic Representation for Video Event-Relation Prediction
Jan 06, 2023Understanding event relationships in videos requires a model to understand the underlying structures of events, i.e., the event type, the associated argument roles, and corresponding entities) along with factual knowledge needed for reasoning. Structural symbolic representation (SSR) based methods directly take event types and associated argument roles/entities as inputs to perform reasoning. However, the state-of-the-art video event-relation prediction system shows the necessity of using continuous feature vectors from input videos; existing methods based solely on SSR inputs fail completely, event when given oracle event types and argument roles. In this paper, we conduct an extensive empirical analysis to answer the following questions: 1) why SSR-based method failed; 2) how to understand the evaluation setting of video event relation prediction properly; 3) how to uncover the potential of SSR-based methods. We first identify the failure of previous SSR-based video event prediction models to be caused by sub-optimal training settings. Surprisingly, we find that a simple SSR-based model with tuned hyperparameters can actually yield a 20\% absolute improvement in macro-accuracy over the state-of-the-art model. Then through qualitative and quantitative analysis, we show how evaluation that takes only video as inputs is currently unfeasible, and the reliance on oracle event information to obtain an accurate evaluation. Based on these findings, we propose to further contextualize the SSR-based model to an Event-Sequence Model and equip it with more factual knowledge through a simple yet effective way of reformulating external visual commonsense knowledge bases into an event-relation prediction pretraining dataset. The resultant new state-of-the-art model eventually establishes a 25\% Macro-accuracy performance boost.
TempCLR: Temporal Alignment Representation with Contrastive Learning
Dec 28, 2022Video representation learning has been successful in video-text pre-training for zero-shot transfer, where each sentence is trained to be close to the paired video clips in a common feature space. For long videos, given a paragraph of description where the sentences describe different segments of the video, by matching all sentence-clip pairs, the paragraph and the full video are aligned implicitly. However, such unit-level similarity measure may ignore the global temporal context over a long time span, which inevitably limits the generalization ability. In this paper, we propose a contrastive learning framework TempCLR to compare the full video and the paragraph explicitly. As the video/paragraph is formulated as a sequence of clips/sentences, under the constraint of their temporal order, we use dynamic time warping to compute the minimum cumulative cost over sentence-clip pairs as the sequence-level distance. To explore the temporal dynamics, we break the consistency of temporal order by shuffling the video clips or sentences according to the temporal granularity. In this way, we obtain the representations for clips/sentences, which perceive the temporal information and thus facilitate the sequence alignment. In addition to pre-training on the video and paragraph, our approach can also generalize on the matching between different video instances. We evaluate our approach on video retrieval, action step localization, and few-shot action recognition, and achieve consistent performance gain over all three tasks. Detailed ablation studies are provided to justify the approach design.
Video Event Extraction via Tracking Visual States of Arguments
Nov 05, 2022Video event extraction aims to detect salient events from a video and identify the arguments for each event as well as their semantic roles. Existing methods focus on capturing the overall visual scene of each frame, ignoring fine-grained argument-level information. Inspired by the definition of events as changes of states, we propose a novel framework to detect video events by tracking the changes in the visual states of all involved arguments, which are expected to provide the most informative evidence for the extraction of video events. In order to capture the visual state changes of arguments, we decompose them into changes in pixels within objects, displacements of objects, and interactions among multiple arguments. We further propose Object State Embedding, Object Motion-aware Embedding and Argument Interaction Embedding to encode and track these changes respectively. Experiments on various video event extraction tasks demonstrate significant improvements compared to state-of-the-art models. In particular, on verb classification, we achieve 3.49% absolute gains (19.53% relative gains) in F1@5 on Video Situation Recognition.
Learning to Decompose Visual Features with Latent Textual Prompts
Oct 09, 2022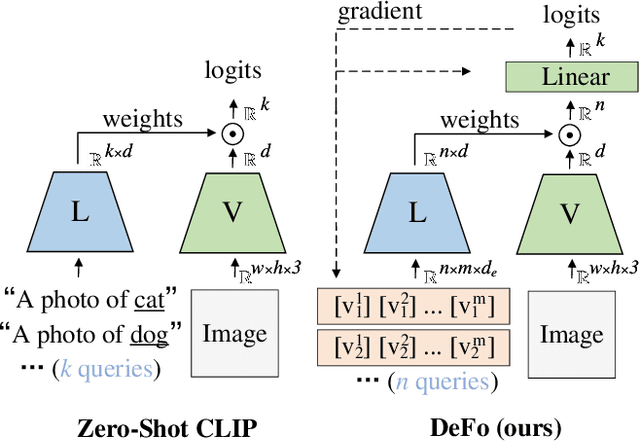
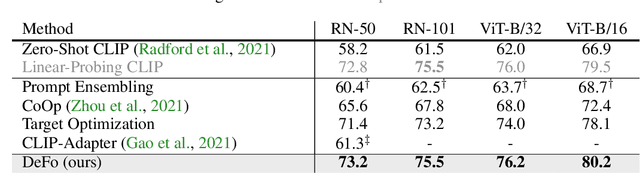

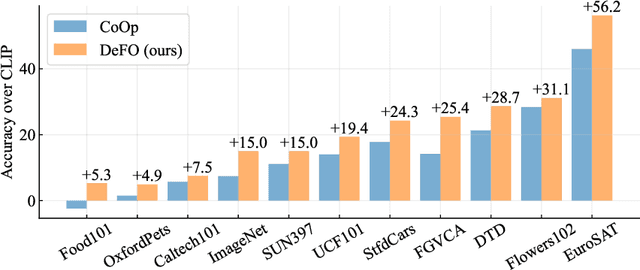
Recent advances in pre-training vision-language models like CLIP have shown great potential in learning transferable visual representations. Nonetheless, for downstream inference, CLIP-like models suffer from either 1) degraded accuracy and robustness in the case of inaccurate text descriptions during retrieval-based inference (the challenge for zero-shot protocol); or 2) breaking the well-established vision-language alignment (the challenge for linear probing). To address them, we propose Decomposed Feature Prompting (DeFo). DeFo leverages a flexible number of learnable embeddings as textual input while maintaining the vision-language dual-model architecture, which enables the model to learn decomposed visual features with the help of feature-level textual prompts. We further use an additional linear layer to perform classification, allowing a scalable size of language inputs. Our empirical study shows DeFo's significance in improving the vision-language models. For example, DeFo obtains 73.2% test accuracy on ImageNet with a ResNet-50 backbone without tuning any pretrained weights of both the vision and language encoder, outperforming zero-shot CLIP by a large margin of 15.0%, and outperforming state-of-the-art vision-language prompt tuning method by 7.6%.
Multimodal Event Graphs: Towards Event Centric Understanding of Multimodal World
Jun 14, 2022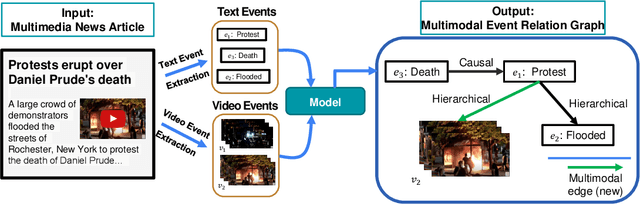
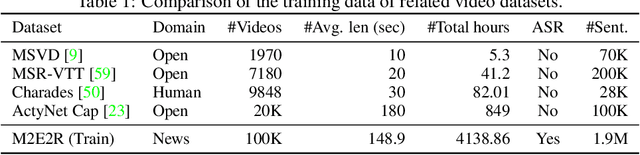
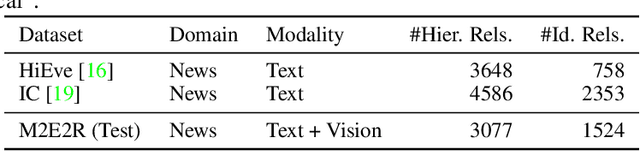

Understanding how events described or shown in multimedia content relate to one another is a critical component to developing robust artificially intelligent systems which can reason about real-world media. While much research has been devoted to event understanding in the text, image, and video domains, none have explored the complex relations that events experience across domains. For example, a news article may describe a `protest' event while a video shows an `arrest' event. Recognizing that the visual `arrest' event is a subevent of the broader `protest' event is a challenging, yet important problem that prior work has not explored. In this paper, we propose the novel task of MultiModal Event Event Relations to recognize such cross-modal event relations. We contribute a large-scale dataset consisting of 100k video-news article pairs, as well as a benchmark of densely annotated data. We also propose a weakly supervised multimodal method which integrates commonsense knowledge from an external knowledge base (KB) to predict rich multimodal event hierarchies. Experiments show that our model outperforms a number of competitive baselines on our proposed benchmark. We also perform a detailed analysis of our model's performance and suggest directions for future research.
Towards Fast Adaptation of Pretrained Contrastive Models for Multi-channel Video-Language Retrieval
Jun 05, 2022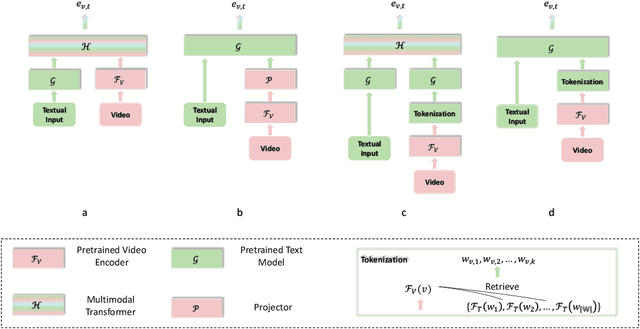

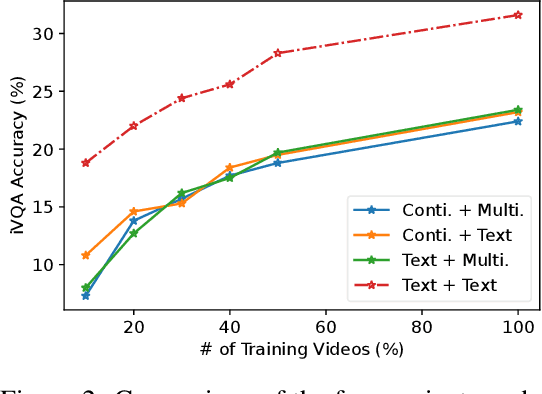
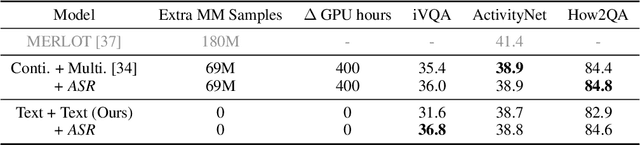
Multi-channel video-language retrieval require models to understand information from different modalities (e.g. video+question, video+speech) and real-world knowledge to correctly link a video with a textual response or query. Fortunately, multimodal contrastive models have been shown to be highly effective at aligning entities in images/videos and text, e.g., CLIP; text contrastive models have been extensively studied recently for their strong ability of producing discriminative sentence embeddings, e.g., SimCSE. Their abilities are exactly needed by multi-channel video-language retrieval. However, it is not clear how to quickly adapt these two lines of models to multi-channel video-language retrieval-style tasks. In this paper, we identify a principled model design space with two axes: how to represent videos and how to fuse video and text information. Based on categorization of recent methods, we investigate the options of representing videos using continuous feature vectors or discrete text tokens; for the fusion method, we explore a multimodal transformer or a pretrained contrastive text model. We extensively evaluate the four combinations on five video-language datasets. We surprisingly find that discrete text tokens coupled with a pretrained contrastive text model yields the best performance. This combination can even outperform state-of-the-art on the iVQA dataset without the additional training on millions of video-language data. Further analysis shows that this is because representing videos as text tokens captures the key visual information with text tokens that are naturally aligned with text models and the text models obtained rich knowledge during contrastive pretraining process. All the empirical analysis we obtain for the four variants establishes a solid foundation for future research on leveraging the rich knowledge of pretrained contrastive models.
Language Models with Image Descriptors are Strong Few-Shot Video-Language Learners
May 29, 2022
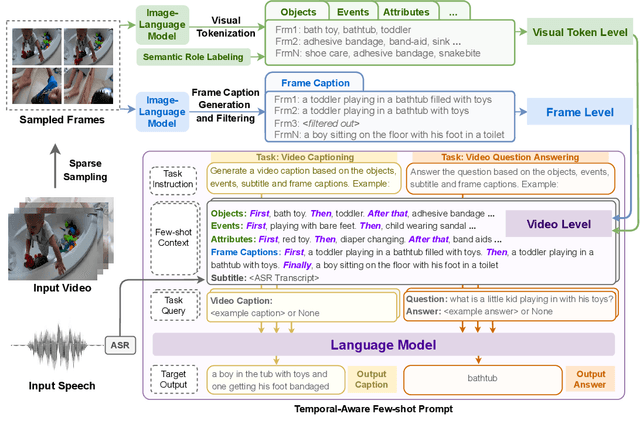
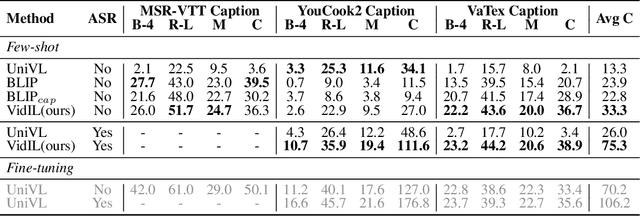

The goal of this work is to build flexible video-language models that can generalize to various video-to-text tasks from few examples, such as domain-specific captioning, question answering, and future event prediction. Existing few-shot video-language learners focus exclusively on the encoder, resulting in the absence of a video-to-text decoder to handle generative tasks. Video captioners have been pretrained on large-scale video-language datasets, but they rely heavily on finetuning and lack the ability to generate text for unseen tasks in a few-shot setting. We propose VidIL, a few-shot Video-language Learner via Image and Language models, which demonstrates strong performance on few-shot video-to-text tasks without the necessity of pretraining or finetuning on any video datasets. We use the image-language models to translate the video content into frame captions, object, attribute, and event phrases, and compose them into a temporal structure template. We then instruct a language model, with a prompt containing a few in-context examples, to generate a target output from the composed content. The flexibility of prompting allows the model to capture any form of text input, such as automatic speech recognition (ASR) transcripts. Our experiments demonstrate the power of language models in understanding videos on a wide variety of video-language tasks, including video captioning, video question answering, video caption retrieval, and video future event prediction. Especially, on video future event prediction, our few-shot model significantly outperforms state-of-the-art supervised models trained on large-scale video datasets. Code and resources are publicly available for research purposes at https://github.com/MikeWangWZHL/VidIL .