 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-modal Context-aware Learning for Visual Prompt Guided Multimodal Image Understanding in Remote Sensing
Dec 12, 2025Recent advances in image understanding have enabled methods that leverage large language models for multimodal reasoning in remote sensing. However, existing approaches still struggle to steer models to the user-relevant regions when only simple, generic text prompts are available. Moreover, in large-scale aerial imagery many objects exhibit highly similar visual appearances and carry rich inter-object relationships, which further complicates accurate recognition. To address these challenges, we propose Cross-modal Context-aware Learning for Visual Prompt-Guided Multimodal Image Understanding (CLV-Net). CLV-Net lets users supply a simple visual cue, a bounding box, to indicate a region of interest, and uses that cue to guide the model to generate correlated segmentation masks and captions that faithfully reflect user intent. Central to our design is a Context-Aware Mask Decoder that models and integrates inter-object relationships to strengthen target representations and improve mask quality. In addition, we introduce a Semantic and Relationship Alignment module: a Cross-modal Semantic Consistency Loss enhances fine-grained discrimination among visually similar targets, while a Relationship Consistency Loss enforces alignment between textual relations and visual interactions. Comprehensive experiments on two benchmark datasets show that CLV-Net outperforms existing methods and establishes new state-of-the-art results. The model effectively captures user intent and produces precise, intention-aligned multimodal outputs.
Multi-period Learning for Financial Time Series Forecasting
Nov 07, 2025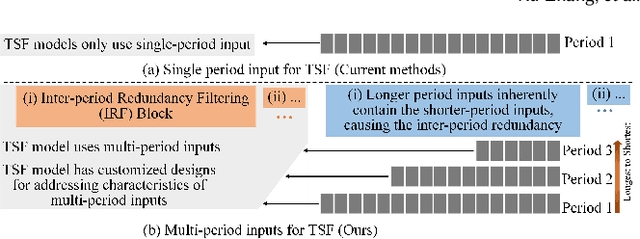
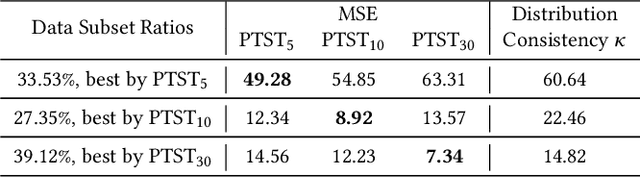
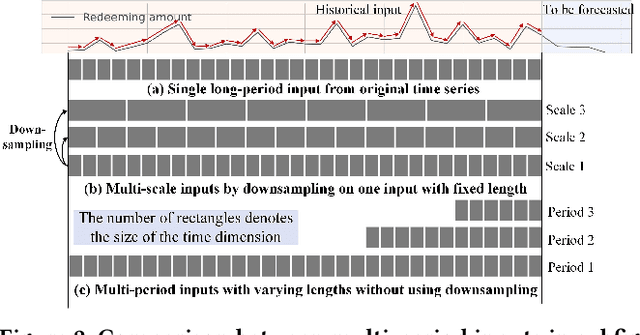
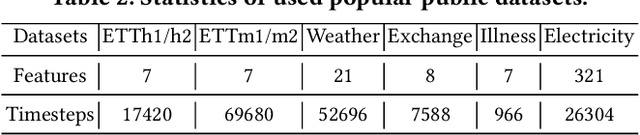
Time series forecasting is important in finance domain. Financial time series (TS) patterns are influenced by both short-term public opinions and medium-/long-term policy and market trends. Hence, processing multi-period inputs becomes crucial for accurate financial time series forecasting (TSF). However, current TSF models either use only single-period input, or lack customized designs for addressing multi-period characteristics. In this paper, we propose a Multi-period Learning Framework (MLF) to enhance financial TSF performance. MLF considers both TSF's accuracy and efficiency requirements. Specifically, we design three new modules to better integrate the multi-period inputs for improving accuracy: (i) Inter-period Redundancy Filtering (IRF), that removes the information redundancy between periods for accurate self-attention modeling, (ii) Learnable Weighted-average Integration (LWI), that effectively integrates multi-period forecasts, (iii) Multi-period self-Adaptive Patching (MAP), that mitigates the bias towards certain periods by setting the same number of patches across all periods. Furthermore, we propose a Patch Squeeze module to reduce the number of patches in self-attention modeling for maximized efficiency. MLF incorporates multiple inputs with varying lengths (periods) to achieve better accuracy and reduces the costs of selecting input lengths during training. The codes and datasets are available at https://github.com/Meteor-Stars/MLF.
Global Feature Enhancing and Fusion Framework for Strain Gauge Time Series Classification
Nov 07, 2025



Strain Gauge Status (SGS) recognition is crucial in the field of intelligent manufacturing based on the Internet of Things, as accurate identification helps timely detection of failed mechanical components, avoiding accidents. The loading and unloading sequences generated by strain gauges can be identified through time series classification (TSC) algorithms. Recently, deep learning models, e.g., convolutional neural networks (CNNs) have shown remarkable success in the TSC task, as they can extract discriminative local features from the subsequences to identify the time series. However, we observe that only the local features may not be sufficient for expressing the time series, especially when the local sub-sequences between different time series are very similar, e.g., SGS data of aircraft wings in static strength experiments. Nevertheless, CNNs suffer from the limitation in extracting global features due to the nature of convolution operations. For extracting global features to more comprehensively represent the SGS time series, we propose two insights: (i) Constructing global features through feature engineering. (ii) Learning high-order relationships between local features to capture global features. To realize and utilize them, we propose a hypergraph-based global feature learning and fusion framework, which learns and fuses global features for semantic consistency to enhance the representation of SGS time series, thereby improving recognition accuracy. Our method designs are validated on industrial SGS and public UCR datasets, showing better generalization for unseen data in SGS recognition.
BoRe-Depth: Self-supervised Monocular Depth Estimation with Boundary Refinement for Embedded Systems
Nov 06, 2025



Depth estimation is one of the key technologies for realizing 3D perception in unmanned systems. Monocular depth estimation has been widely researched because of its low-cost advantage, but the existing methods face the challenges of poor depth estimation performance and blurred object boundaries on embedded systems. In this paper, we propose a novel monocular depth estimation model, BoRe-Depth, which contains only 8.7M parameters. It can accurately estimate depth maps on embedded systems and significantly improves boundary quality. Firstly, we design an Enhanced Feature Adaptive Fusion Module (EFAF) which adaptively fuses depth features to enhance boundary detail representation. Secondly, we integrate semantic knowledge into the encoder to improve the object recognition and boundary perception capabilities. Finally, BoRe-Depth is deployed on NVIDIA Jetson Orin, and runs efficiently at 50.7 FPS. We demonstrate that the proposed model significantly outperforms previous lightweight models on multiple challenging datasets, and we provide detailed ablation studies for the proposed methods. The code is available at https://github.com/liangxiansheng093/BoRe-Depth.
Traceable Drug Recommendation over Medical Knowledge Graphs
Oct 31, 2025



Drug recommendation (DR) systems aim to support healthcare professionals in selecting appropriate medications based on patients' medical conditions. State-of-the-art approaches utilize deep learning techniques for improving DR, but fall short in providing any insights on the derivation process of recommendations -- a critical limitation in such high-stake applications. We propose TraceDR, a novel DR system operating over a medical knowledge graph (MKG), which ensures access to large-scale and high-quality information. TraceDR simultaneously predicts drug recommendations and related evidence within a multi-task learning framework, enabling traceability of medication recommendations. For covering a more diverse set of diseases and drugs than existing works, we devise a framework for automatically constructing patient health records and release DrugRec, a new large-scale testbed for DR.
Moving Beyond Diffusion: Hierarchy-to-Hierarchy Autoregression for fMRI-to-Image Reconstruction
Oct 25, 2025Reconstructing visual stimuli from fMRI signals is a central challenge bridging machine learning and neuroscience. Recent diffusion-based methods typically map fMRI activity to a single high-level embedding, using it as fixed guidance throughout the entire generation process. However, this fixed guidance collapses hierarchical neural information and is misaligned with the stage-dependent demands of image reconstruction. In response, we propose MindHier, a coarse-to-fine fMRI-to-image reconstruction framework built on scale-wise autoregressive modeling. MindHier introduces three components: a Hierarchical fMRI Encoder to extract multi-level neural embeddings, a Hierarchy-to-Hierarchy Alignment scheme to enforce layer-wise correspondence with CLIP features, and a Scale-Aware Coarse-to-Fine Neural Guidance strategy to inject these embeddings into autoregression at matching scales. These designs make MindHier an efficient and cognitively-aligned alternative to diffusion-based methods by enabling a hierarchical reconstruction process that synthesizes global semantics before refining local details, akin to human visual perception. Extensive experiments on the NSD dataset show that MindHier achieves superior semantic fidelity, 4.67x faster inference, and more deterministic results than the diffusion-based baselines.
HAD: HAllucination Detection Language Models Based on a Comprehensive Hallucination Taxonomy
Oct 22, 2025The increasing reliance on natural language generation (NLG) models, particularly large language models, has raised concerns about the reliability and accuracy of their outputs. A key challenge is hallucination, where models produce plausible but incorrect information. As a result, hallucination detection has become a critical task. In this work, we introduce a comprehensive hallucination taxonomy with 11 categories across various NLG tasks and propose the HAllucination Detection (HAD) models https://github.com/pku0xff/HAD, which integrate hallucination detection, span-level identification, and correction into a single inference process. Trained on an elaborate synthetic dataset of about 90K samples, our HAD models are versatile and can be applied to various NLG tasks. We also carefully annotate a test set for hallucination detection, called HADTest, which contains 2,248 samples. Evaluations on in-domain and out-of-domain test sets show that our HAD models generally outperform the existing baselines, achieving state-of-the-art results on HaluEval, FactCHD, and FaithBench, confirming their robustness and versatility.
GeoPurify: A Data-Efficient Geometric Distillation Framework for Open-Vocabulary 3D Segmentation
Oct 02, 2025



Recent attempts to transfer features from 2D Vision-Language Models (VLMs) to 3D semantic segmentation expose a persistent trade-off. Directly projecting 2D features into 3D yields noisy and fragmented predictions, whereas enforcing geometric coherence necessitates costly training pipelines and large-scale annotated 3D data. We argue that this limitation stems from the dominant segmentation-and-matching paradigm, which fails to reconcile 2D semantics with 3D geometric structure. The geometric cues are not eliminated during the 2D-to-3D transfer but remain latent within the noisy and view-aggregated features. To exploit this property, we propose GeoPurify that applies a small Student Affinity Network to purify 2D VLM-generated 3D point features using geometric priors distilled from a 3D self-supervised teacher model. During inference, we devise a Geometry-Guided Pooling module to further denoise the point cloud and ensure the semantic and structural consistency. Benefiting from latent geometric information and the learned affinity network, GeoPurify effectively mitigates the trade-off and achieves superior data efficiency. Extensive experiments on major 3D benchmarks demonstrate that GeoPurify achieves or surpasses state-of-the-art performance while utilizing only about 1.5% of the training data. Our codes and checkpoints are available at [https://github.com/tj12323/GeoPurify](https://github.com/tj12323/GeoPurify).
SimCroP: Radiograph Representation Learning with Similarity-driven Cross-granularity Pre-training
Sep 10, 2025Medical vision-language pre-training shows great potential in learning representative features from massive paired radiographs and reports. However, in computed tomography (CT) scans, the distribution of lesions which contain intricate structures is characterized by spatial sparsity. Besides, the complex and implicit relationships between different pathological descriptions in each sentence of the report and their corresponding sub-regions in radiographs pose additional challenges. In this paper, we propose a Similarity-Driven Cross-Granularity Pre-training (SimCroP) framework on chest CTs, which combines similarity-driven alignment and cross-granularity fusion to improve radiograph interpretation. We first leverage multi-modal masked modeling to optimize the encoder for understanding precise low-level semantics from radiographs. Then, similarity-driven alignment is designed to pre-train the encoder to adaptively select and align the correct patches corresponding to each sentence in reports. The cross-granularity fusion module integrates multimodal information across instance level and word-patch level, which helps the model better capture key pathology structures in sparse radiographs, resulting in improved performance for multi-scale downstream tasks. SimCroP is pre-trained on a large-scale paired CT-reports dataset and validated on image classification and segmentation tasks across five public datasets. Experimental results demonstrate that SimCroP outperforms both cutting-edge medical self-supervised learning methods and medical vision-language pre-training methods. Codes and models are available at https://github.com/ToniChopp/SimCroP.
Incorporating Legal Logic into Deep Learning: An Intelligent Approach to Probation Prediction
Aug 17, 2025Probation is a crucial institution in modern criminal law, embodying the principles of fairness and justice while contributing to the harmonious development of society. Despite its importance, the current Intelligent Judicial Assistant System (IJAS) lacks dedicated methods for probation prediction, and research on the underlying factors influencing probation eligibility remains limited. In addition, probation eligibility requires a comprehensive analysis of both criminal circumstances and remorse. Much of the existing research in IJAS relies primarily on data-driven methodologies, which often overlooks the legal logic underpinning judicial decision-making. To address this gap, we propose a novel approach that integrates legal logic into deep learning models for probation prediction, implemented in three distinct stages. First, we construct a specialized probation dataset that includes fact descriptions and probation legal elements (PLEs). Second, we design a distinct probation prediction model named the Multi-Task Dual-Theory Probation Prediction Model (MT-DT), which is grounded in the legal logic of probation and the \textit{Dual-Track Theory of Punishment}. Finally, our experiments on the probation dataset demonstrate that the MT-DT model outperforms baseline models, and an analysis of the underlying legal logic further validates the effectiveness of the proposed approach.