 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Aware Risk Estimation of Perception Failures for Autonomous Vehicles
May 03, 2023



Safety and performance are key enablers for autonomous driving: on the one hand we want our autonomous vehicles (AVs) to be safe, while at the same time their performance (e.g., comfort or progression) is key to adoption. To effectively walk the tight-rope between safety and performance, AVs need to be risk-averse, but not entirely risk-avoidant. To facilitate safe-yet-performant driving, in this paper, we develop a task-aware risk estimator that assesses the risk a perception failure poses to the AV's motion plan. If the failure has no bearing on the safety of the AV's motion plan, then regardless of how egregious the perception failure is, our task-aware risk estimator considers the failure to have a low risk; on the other hand, if a seemingly benign perception failure severely impacts the motion plan, then our estimator considers it to have a high risk. In this paper, we propose a task-aware risk estimator to decide whether a safety maneuver needs to be triggered. To estimate the task-aware risk, first, we leverage the perception failure - detected by a perception monitor - to synthesize an alternative plausible model for the vehicle's surroundings. The risk due to the perception failure is then formalized as the "relative" risk to the AV's motion plan between the perceived and the alternative plausible scenario. We employ a statistical tool called copula, which models tail dependencies between distributions, to estimate this risk. The theoretical properties of the copula allow us to compute probably approximately correct (PAC) estimates of the risk. We evaluate our task-aware risk estimator using NuPlan and compare it with established baselines, showing that the proposed risk estimator achieves the best F1-score (doubling the score of the best baseline) and exhibits a good balance between recall and precision, i.e., a good balance of safety and performance.
Tree-structured Policy Planning with Learned Behavior Models
Jan 27, 2023Autonomous vehicles (AVs) need to reason about the multimodal behavior of neighboring agents while planning their own motion. Many existing trajectory planners seek a single trajectory that performs well under \emph{all} plausible futures simultaneously, ignoring bi-directional interactions and thus leading to overly conservative plans. Policy planning, whereby the ego agent plans a policy that reacts to the environment's multimodal behavior, is a promising direction as it can account for the action-reaction interactions between the AV and the environment. However, most existing policy planners do not scale to the complexity of real autonomous vehicle applications: they are either not compatible with modern deep learning prediction models, not interpretable, or not able to generate high quality trajectories. To fill this gap, we propose Tree Policy Planning (TPP), a policy planner that is compatible with state-of-the-art deep learning prediction models, generates multistage motion plans, and accounts for the influence of ego agent on the environment behavior. The key idea of TPP is to reduce the continuous optimization problem into a tractable discrete MDP through the construction of two tree structures: an ego trajectory tree for ego trajectory options, and a scenario tree for multi-modal ego-conditioned environment predictions. We demonstrate the efficacy of TPP in closed-loop simulations based on real-world nuScenes dataset and results show that TPP scales to realistic AV scenarios and significantly outperforms non-policy baselines.
Robust Trajectory Prediction against Adversarial Attacks
Jul 29, 2022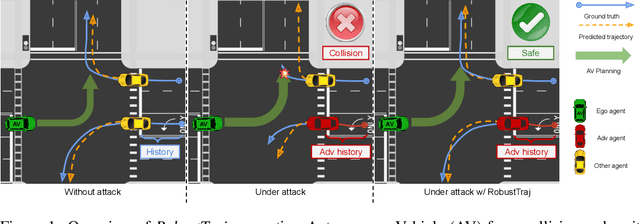
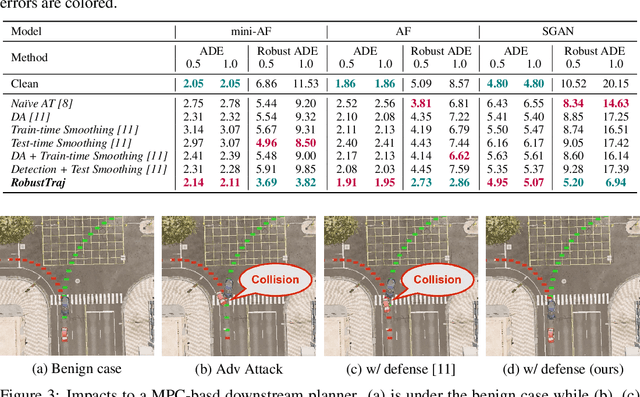

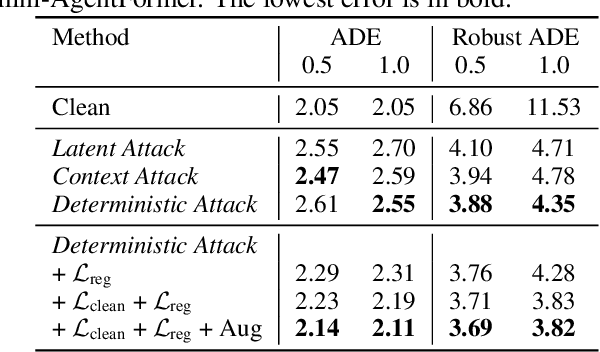
Trajectory prediction using deep neural networks (DNNs) is an essential component of autonomous driving (AD) systems. However, these methods are vulnerable to adversarial attacks, leading to serious consequences such as collisions. In this work, we identify two key ingredients to defend trajectory prediction models against adversarial attacks including (1) designing effective adversarial training methods and (2) adding domain-specific data augmentation to mitigate the performance degradation on clean data. We demonstrate that our method is able to improve the performance by 46% on adversarial data and at the cost of only 3% performance degradation on clean data, compared to the model trained with clean data. Additionally, compared to existing robust methods, our method can improve performance by 21% on adversarial examples and 9% on clean data. Our robust model is evaluated with a planner to study its downstream impacts. We demonstrate that our model can significantly reduce the severe accident rates (e.g., collisions and off-road driving).
Multiface: A Dataset for Neural Face Rendering
Jul 22, 2022



Photorealistic avatars of human faces have come a long way in recent years, yet research along this area is limited by a lack of publicly available, high-quality datasets covering both, dense multi-view camera captures, and rich facial expressions of the captured subjects. In this work, we present Multiface, a new multi-view, high-resolution human face dataset collected from 13 identities at Reality Labs Research for neural face rendering. We introduce Mugsy, a large scale multi-camera apparatus to capture high-resolution synchronized videos of a facial performance. The goal of Multiface is to close the gap in accessibility to high quality data in the academic community and to enable research in VR telepresence. Along with the release of the dataset, we conduct ablation studies on the influence of different model architectures toward the model's interpolation capacity of novel viewpoint and expressions. With a conditional VAE model serving as our baseline, we found that adding spatial bias, texture warp field, and residual connections improves performance on novel view synthesis. Our code and data is available at: https://github.com/facebookresearch/multiface
Observation-Centric SORT: Rethinking SORT for Robust Multi-Object Tracking
Mar 27, 2022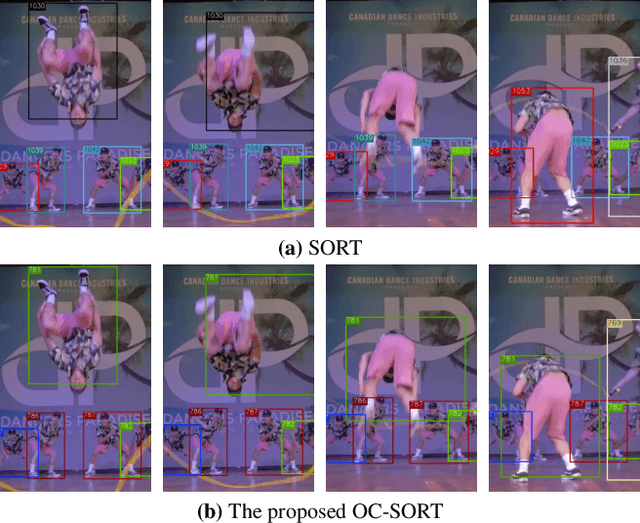



Multi-Object Tracking (MOT) has rapidly progressed with the development of object detection and re-identification. However, motion modeling, which facilitates object association by forecasting short-term trajectories with past observations, has been relatively under-explored in recent years. Current motion models in MOT typically assume that the object motion is linear in a small time window and needs continuous observations, so these methods are sensitive to occlusions and non-linear motion and require high frame-rate videos. In this work, we show that a simple motion model can obtain state-of-the-art tracking performance without other cues like appearance. We emphasize the role of "observation" when recovering tracks from being lost and reducing the error accumulated by linear motion models during the lost period. We thus name the proposed method as Observation-Centric SORT, OC-SORT for short. It remains simple, online, and real-time but improves robustness over occlusion and non-linear motion. It achieves 63.2 and 62.1 HOTA on MOT17 and MOT20, respectively, surpassing all published methods. It also sets new states of the art on KITTI Pedestrian Tracking and DanceTrack where the object motion is highly non-linear. The code and model are available at https://github.com/noahcao/OC_SORT.
MTP: Multi-Hypothesis Tracking and Prediction for Reduced Error Propagation
Oct 18, 2021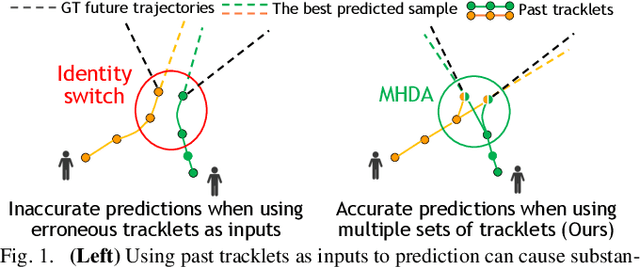

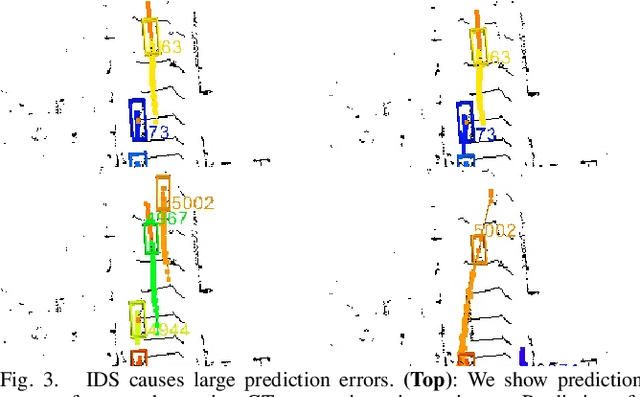
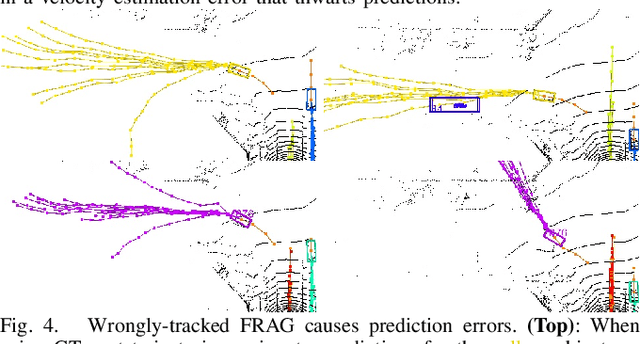
Recently, there has been tremendous progress in developing each individual module of the standard perception-planning robot autonomy pipeline, including detection, tracking, prediction of other agents' trajectories, and ego-agent trajectory planning. Nevertheless, there has been less attention given to the principled integration of these components, particularly in terms of the characterization and mitigation of cascading errors. This paper addresses the problem of cascading errors by focusing on the coupling between the tracking and prediction modules. First, by using state-of-the-art tracking and prediction tools, we conduct a comprehensive experimental evaluation of how severely errors stemming from tracking can impact prediction performance. On the KITTI and nuScenes datasets, we find that predictions consuming tracked trajectories as inputs (the typical case in practice) can experience a significant (even order of magnitude) drop in performance in comparison to the idealized setting where ground truth past trajectories are used as inputs. To address this issue, we propose a multi-hypothesis tracking and prediction framework. Rather than relying on a single set of tracking results for prediction, our framework simultaneously reasons about multiple sets of tracking results, thereby increasing the likelihood of including accurate tracking results as inputs to prediction. We show that this framework improves overall prediction performance over the standard single-hypothesis tracking-prediction pipeline by up to 34.2% on the nuScenes dataset, with even more significant improvements (up to ~70%) when restricting the evaluation to challenging scenarios involving identity switches and fragments -- all with an acceptable computation overhead.
Multi-Echo LiDAR for 3D Object Detection
Jul 23, 2021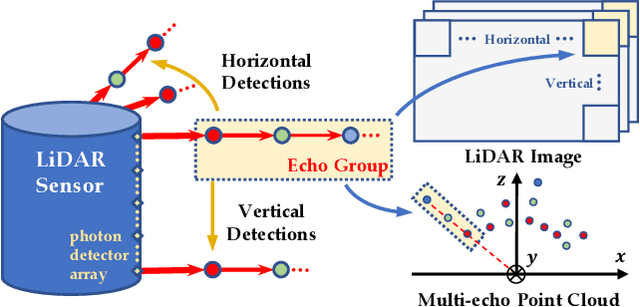
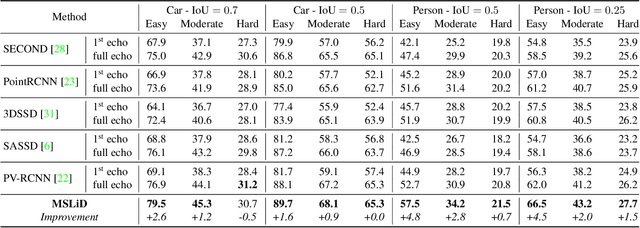
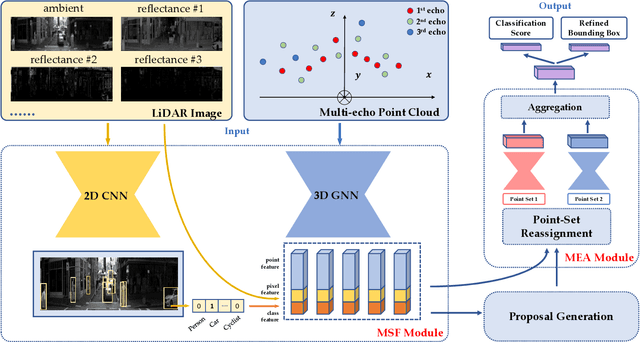
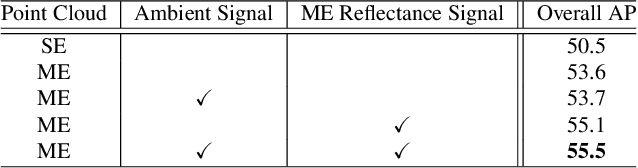
LiDAR sensors can be used to obtain a wide range of measurement signals other than a simple 3D point cloud, and those signals can be leveraged to improve perception tasks like 3D object detection. A single laser pulse can be partially reflected by multiple objects along its path, resulting in multiple measurements called echoes. Multi-echo measurement can provide information about object contours and semi-transparent surfaces which can be used to better identify and locate objects. LiDAR can also measure surface reflectance (intensity of laser pulse return), as well as ambient light of the scene (sunlight reflected by objects). These signals are already available in commercial LiDAR devices but have not been used in most LiDAR-based detection models. We present a 3D object detection model which leverages the full spectrum of measurement signals provided by LiDAR. First, we propose a multi-signal fusion (MSF) module to combine (1) the reflectance and ambient features extracted with a 2D CNN, and (2) point cloud features extracted using a 3D graph neural network (GNN). Second, we propose a multi-echo aggregation (MEA) module to combine the information encoded in different set of echo points. Compared with traditional single echo point cloud methods, our proposed Multi-Signal LiDAR Detector (MSLiD) extracts richer context information from a wider range of sensing measurements and achieves more accurate 3D object detection. Experiments show that by incorporating the multi-modality of LiDAR, our method outperforms the state-of-the-art by up to 9.1%.
Multi-Modality Task Cascade for 3D Object Detection
Jul 08, 2021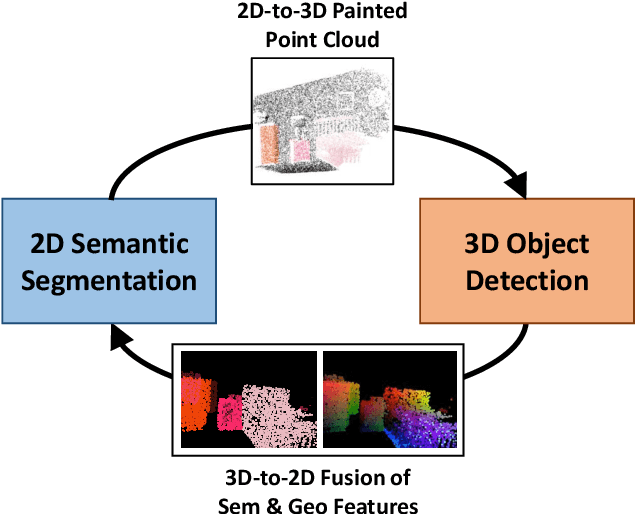
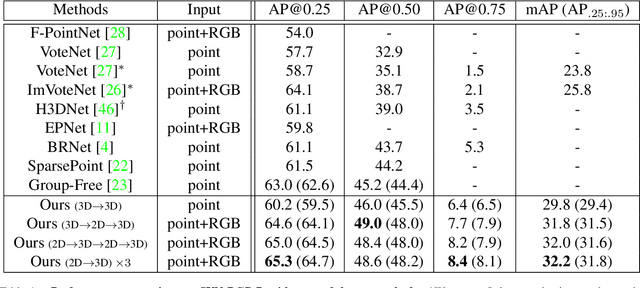
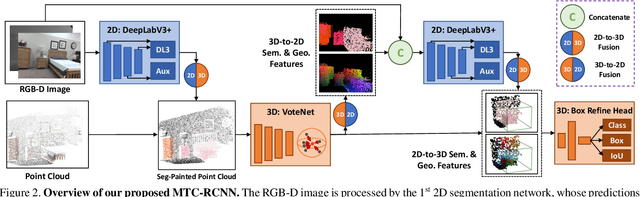
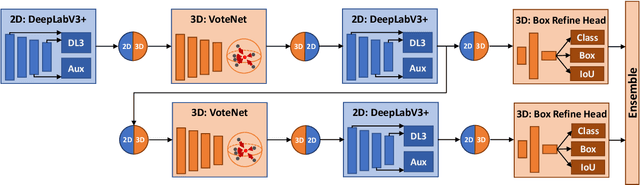
Point clouds and RGB images are naturally complementary modalities for 3D visual understanding - the former provides sparse but accurate locations of points on objects, while the latter contains dense color and texture information. Despite this potential for close sensor fusion, many methods train two models in isolation and use simple feature concatenation to represent 3D sensor data. This separated training scheme results in potentially sub-optimal performance and prevents 3D tasks from being used to benefit 2D tasks that are often useful on their own. To provide a more integrated approach, we propose a novel Multi-Modality Task Cascade network (MTC-RCNN) that leverages 3D box proposals to improve 2D segmentation predictions, which are then used to further refine the 3D boxes. We show that including a 2D network between two stages of 3D modules significantly improves both 2D and 3D task performance. Moreover, to prevent the 3D module from over-relying on the overfitted 2D predictions, we propose a dual-head 2D segmentation training and inference scheme, allowing the 2nd 3D module to learn to interpret imperfect 2D segmentation predictions. Evaluating our model on the challenging SUN RGB-D dataset, we improve upon state-of-the-art results of both single modality and fusion networks by a large margin ($\textbf{+3.8}$ mAP@0.5). Code will be released $\href{https://github.com/Divadi/MTC_RCNN}{\text{here.}}$
Wide-Baseline Multi-Camera Calibration using Person Re-Identification
Apr 17, 2021
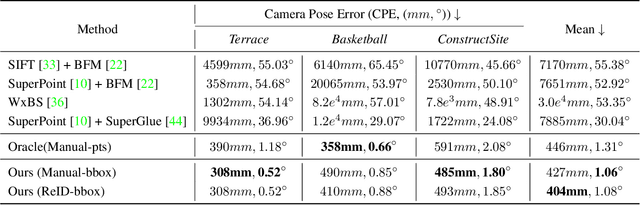
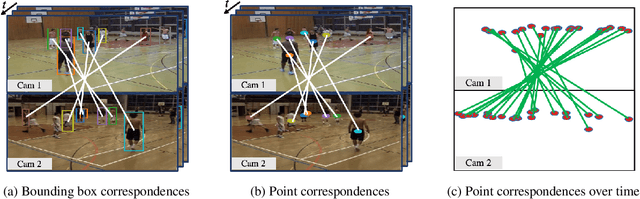
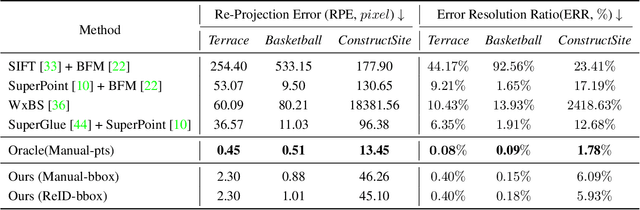
We address the problem of estimating the 3D pose of a network of cameras for large-environment wide-baseline scenarios, e.g., cameras for construction sites, sports stadiums, and public spaces. This task is challenging since detecting and matching the same 3D keypoint observed from two very different camera views is difficult, making standard structure-from-motion (SfM) pipelines inapplicable. In such circumstances, treating people in the scene as "keypoints" and associating them across different camera views can be an alternative method for obtaining correspondences. Based on this intuition, we propose a method that uses ideas from person re-identification (re-ID) for wide-baseline camera calibration. Our method first employs a re-ID method to associate human bounding boxes across cameras, then converts bounding box correspondences to point correspondences, and finally solves for camera pose using multi-view geometry and bundle adjustment. Since our method does not require specialized calibration targets except for visible people, it applies to situations where frequent calibration updates are required. We perform extensive experiments on datasets captured from scenes of different sizes, camera settings (indoor and outdoor), and human activities (walking, playing basketball, construction). Experiment results show that our method achieves similar performance to standard SfM methods relying on manually labeled point correspondences.
AgentFormer: Agent-Aware Transformers for Socio-Temporal Multi-Agent Forecasting
Mar 25, 2021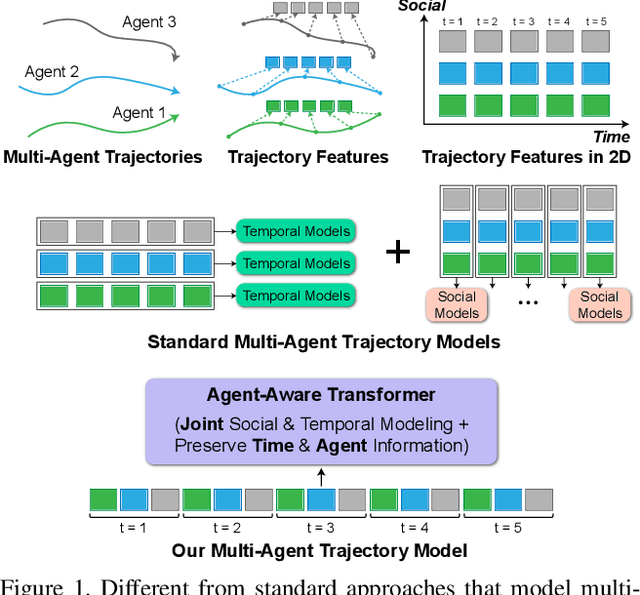

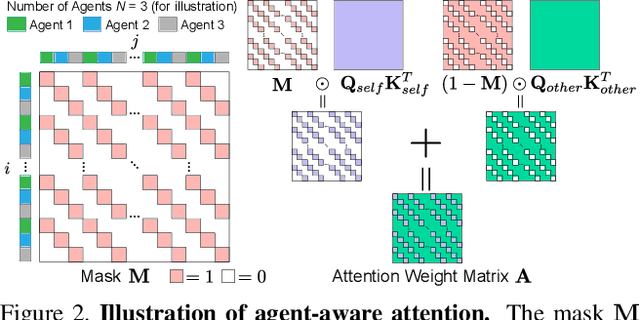

Predicting accurate future trajectories of multiple agents is essential for autonomous systems, but is challenging due to the complex agent interaction and the uncertainty in each agent's future behavior. Forecasting multi-agent trajectories requires modeling two key dimensions: (1) time dimension, where we model the influence of past agent states over future states; (2) social dimension, where we model how the state of each agent affects others. Most prior methods model these two dimensions separately; e.g., first using a temporal model to summarize features over time for each agent independently and then modeling the interaction of the summarized features with a social model. This approach is suboptimal since independent feature encoding over either the time or social dimension can result in a loss of information. Instead, we would prefer a method that allows an agent's state at one time to directly affect another agent's state at a future time. To this end, we propose a new Transformer, AgentFormer, that jointly models the time and social dimensions. The model leverages a sequence representation of multi-agent trajectories by flattening trajectory features across time and agents. Since standard attention operations disregard the agent identity of each element in the sequence, AgentFormer uses a novel agent-aware attention mechanism that preserves agent identities by attending to elements of the same agent differently than elements of other agents. Based on AgentFormer, we propose a stochastic multi-agent trajectory prediction model that can attend to features of any agent at any previous timestep when inferring an agent's future position. The latent intent of all agents is also jointly modeled, allowing the stochasticity in one agent's behavior to affect other agents. Our method significantly improves the state of the art on well-established pedestrian and autonomous driving datasets.