 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBottleneck Tokens for Unified Multimodal Retrieval
Apr 13, 2026Adapting decoder-only multimodal large language models (MLLMs) for unified multimodal retrieval faces two structural gaps. First, existing methods rely on implicit pooling, which overloads the hidden state of a standard vocabulary token (e.g., <EOS>) as the sequence-level representation, a mechanism never designed for information aggregation. Second, contrastive fine-tuning specifies what the embedding should match but provides no token-level guidance on how information should be compressed into it. We address both gaps with two complementary components. Architecturally, we introduce Bottleneck Tokens (BToks), a small set of learnable tokens that serve as a fixed-capacity explicit pooling mechanism. For training, we propose Generative Information Condensation: a next-token prediction objective coupled with a Condensation Mask that severs the direct attention path from target tokens to query tokens. All predictive signals are thereby forced through the BToks, converting the generative loss into dense, token-level supervision for semantic compression. At inference time, only the input and BToks are processed in a single forward pass with negligible overhead over conventional last-token pooling. On MMEB-V2 (78 datasets, 3 modalities, 9 meta-tasks), our approach achieves state-of-the-art among 2B-scale methods under comparable data conditions, attaining an Overall score of 59.0 (+3.6 over VLM2Vec-V2) with substantial gains on semantically demanding tasks (e.g., +12.6 on Video-QA).
LEMUR: Large scale End-to-end MUltimodal Recommendation
Nov 17, 2025Traditional ID-based recommender systems often struggle with cold-start and generalization challenges. Multimodal recommendation systems, which leverage textual and visual data, offer a promising solution to mitigate these issues. However, existing industrial approaches typically adopt a two-stage training paradigm: first pretraining a multimodal model, then applying its frozen representations to train the recommendation model. This decoupled framework suffers from misalignment between multimodal learning and recommendation objectives, as well as an inability to adapt dynamically to new data. To address these limitations, we propose LEMUR, the first large-scale multimodal recommender system trained end-to-end from raw data. By jointly optimizing both the multimodal and recommendation components, LEMUR ensures tighter alignment with downstream objectives while enabling real-time parameter updates. Constructing multimodal sequential representations from user history often entails prohibitively high computational costs. To alleviate this bottleneck, we propose a novel memory bank mechanism that incrementally accumulates historical multimodal representations throughout the training process. After one month of deployment in Douyin Search, LEMUR has led to a 0.843% reduction in query change rate decay and a 0.81% improvement in QAUC. Additionally, LEMUR has shown significant gains across key offline metrics for Douyin Advertisement. Our results validate the superiority of end-to-end multimodal recommendation in real-world industrial scenarios.
A Metric for MLLM Alignment in Large-scale Recommendation
Aug 07, 2025



Multimodal recommendation has emerged as a critical technique in modern recommender systems, leveraging content representations from advanced multimodal large language models (MLLMs). To ensure these representations are well-adapted, alignment with the recommender system is essential. However, evaluating the alignment of MLLMs for recommendation presents significant challenges due to three key issues: (1) static benchmarks are inaccurate because of the dynamism in real-world applications, (2) evaluations with online system, while accurate, are prohibitively expensive at scale, and (3) conventional metrics fail to provide actionable insights when learned representations underperform. To address these challenges, we propose the Leakage Impact Score (LIS), a novel metric for multimodal recommendation. Rather than directly assessing MLLMs, LIS efficiently measures the upper bound of preference data. We also share practical insights on deploying MLLMs with LIS in real-world scenarios. Online A/B tests on both Content Feed and Display Ads of Xiaohongshu's Explore Feed production demonstrate the effectiveness of our proposed method, showing significant improvements in user spent time and advertiser value.
An Aligning and Training Framework for Multimodal Recommendations
Mar 20, 2024



With the development of multimedia applications, multimodal recommendations are playing an essential role, as they can leverage rich contexts beyond user interactions. Existing methods mainly regard multimodal information as an auxiliary, using them to help learn ID features; however, there exist semantic gaps among multimodal content features and ID features, for which directly using multimodal information as an auxiliary would lead to misalignment in representations of users and items. In this paper, we first systematically investigate the misalignment issue in multimodal recommendations, and propose a solution named AlignRec. In AlignRec, the recommendation objective is decomposed into three alignments, namely alignment within contents, alignment between content and categorical ID, and alignment between users and items. Each alignment is characterized by a specific objective function and is integrated into our multimodal recommendation framework. To effectively train our AlignRec, we propose starting from pre-training the first alignment to obtain unified multimodal features and subsequently training the following two alignments together with these features as input. As it is essential to analyze whether each multimodal feature helps in training, we design three new classes of metrics to evaluate intermediate performance. Our extensive experiments on three real-world datasets consistently verify the superiority of AlignRec compared to nine baselines. We also find that the multimodal features generated by AlignRec are better than currently used ones, which are to be open-sourced.
SNP-S3: Shared Network Pre-training and Significant Semantic Strengthening for Various Video-Text Tasks
Jan 31, 2024We present a framework for learning cross-modal video representations by directly pre-training on raw data to facilitate various downstream video-text tasks. Our main contributions lie in the pre-training framework and proxy tasks. First, based on the shortcomings of two mainstream pixel-level pre-training architectures (limited applications or less efficient), we propose Shared Network Pre-training (SNP). By employing one shared BERT-type network to refine textual and cross-modal features simultaneously, SNP is lightweight and could support various downstream applications. Second, based on the intuition that people always pay attention to several "significant words" when understanding a sentence, we propose the Significant Semantic Strengthening (S3) strategy, which includes a novel masking and matching proxy task to promote the pre-training performance. Experiments conducted on three downstream video-text tasks and six datasets demonstrate that, we establish a new state-of-the-art in pixel-level video-text pre-training; we also achieve a satisfactory balance between the pre-training efficiency and the fine-tuning performance. The codebase are available at https://github.com/alipay/Ant-Multi-Modal-Framework/tree/main/prj/snps3_vtp.
Large-scale Pretraining for Neural Machine Translation with Tens of Billions of Sentence Pairs
Oct 06, 2019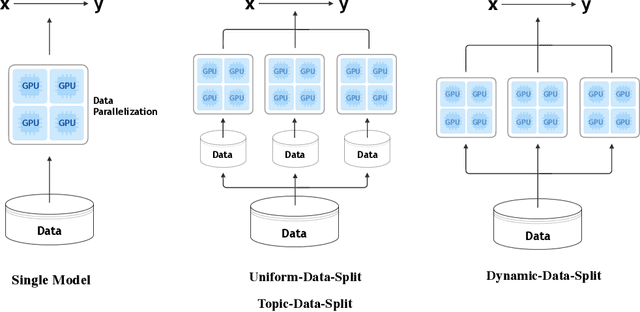
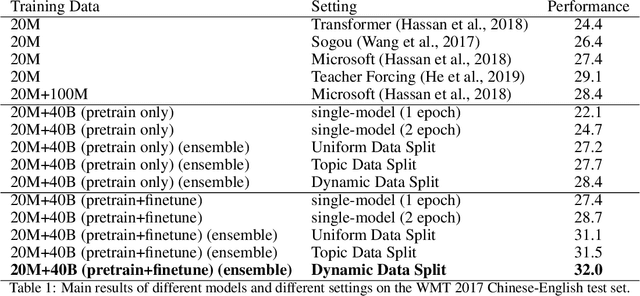
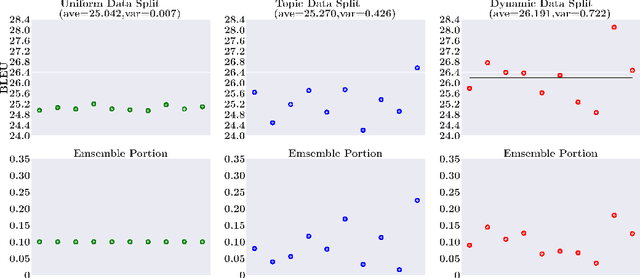

In this paper, we investigate the problem of training neural machine translation (NMT) systems with a dataset of more than 40 billion bilingual sentence pairs, which is larger than the largest dataset to date by orders of magnitude. Unprecedented challenges emerge in this situation compared to previous NMT work, including severe noise in the data and prohibitively long training time. We propose practical solutions to handle these issues and demonstrate that large-scale pretraining significantly improves NMT performance. We are able to push the BLEU score of WMT17 Chinese-English dataset to 32.3, with a significant performance boost of +3.2 over existing state-of-the-art results.