 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Cross-Modal Knowledge Distillation for Unconstrained Videos
Apr 27, 2023Cross-modal distillation has been widely used to transfer knowledge across different modalities, enriching the representation of the target unimodal one. Recent studies highly relate the temporal synchronization between vision and sound to the semantic consistency for cross-modal distillation. However, such semantic consistency from the synchronization is hard to guarantee in unconstrained videos, due to the irrelevant modality noise and differentiated semantic correlation. To this end, we first propose a \textit{Modality Noise Filter} (MNF) module to erase the irrelevant noise in teacher modality with cross-modal context. After this purification, we then design a \textit{Contrastive Semantic Calibration} (CSC) module to adaptively distill useful knowledge for target modality, by referring to the differentiated sample-wise semantic correlation in a contrastive fashion. Extensive experiments show that our method could bring a performance boost compared with other distillation methods in both visual action recognition and video retrieval task. We also extend to the audio tagging task to prove the generalization of our method. The source code is available at \href{https://github.com/GeWu-Lab/cross-modal-distillation}{https://github.com/GeWu-Lab/cross-modal-distillation}.
Large-scale Knowledge Distillation with Elastic Heterogeneous Computing Resources
Jul 14, 2022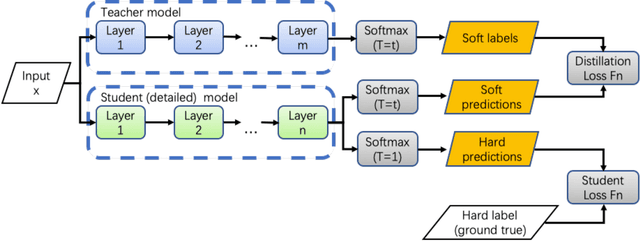

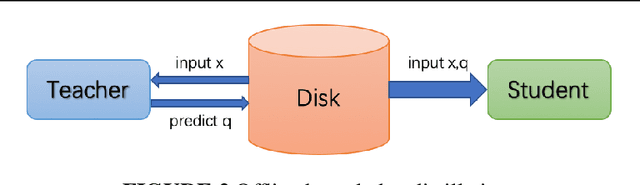
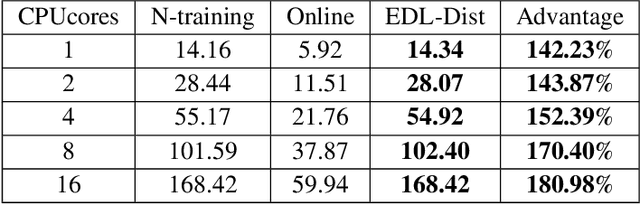
Although more layers and more parameters generally improve the accuracy of the models, such big models generally have high computational complexity and require big memory, which exceed the capacity of small devices for inference and incurs long training time. In addition, it is difficult to afford long training time and inference time of big models even in high performance servers, as well. As an efficient approach to compress a large deep model (a teacher model) to a compact model (a student model), knowledge distillation emerges as a promising approach to deal with the big models. Existing knowledge distillation methods cannot exploit the elastic available computing resources and correspond to low efficiency. In this paper, we propose an Elastic Deep Learning framework for knowledge Distillation, i.e., EDL-Dist. The advantages of EDL-Dist are three-fold. First, the inference and the training process is separated. Second, elastic available computing resources can be utilized to improve the efficiency. Third, fault-tolerance of the training and inference processes is supported. We take extensive experimentation to show that the throughput of EDL-Dist is up to 3.125 times faster than the baseline method (online knowledge distillation) while the accuracy is similar or higher.
Fine-tuning Pre-trained Language Models with Noise Stability Regularization
Jun 12, 2022
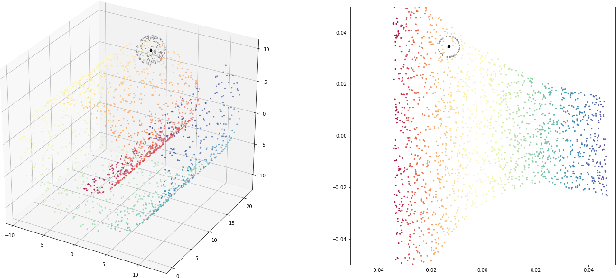
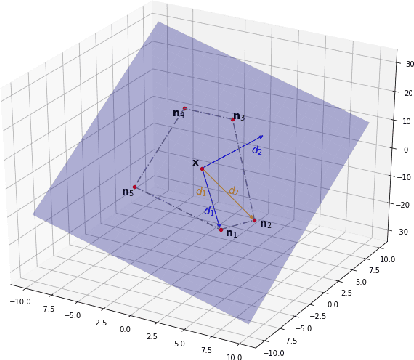
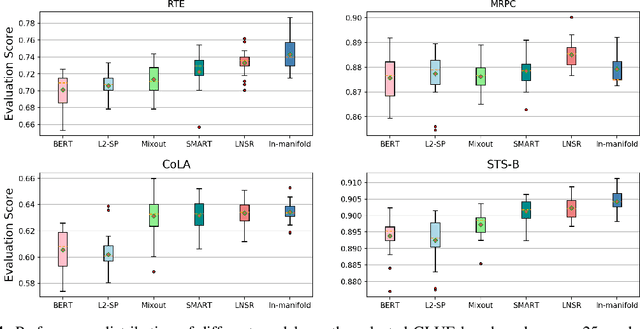
The advent of large-scale pre-trained language models has contributed greatly to the recent progress in natural language processing. Many state-of-the-art language models are first trained on a large text corpus and then fine-tuned on downstream tasks. Despite its recent success and wide adoption, fine-tuning a pre-trained language model often suffers from overfitting, which leads to poor generalizability due to the extremely high complexity of the model and the limited training samples from downstream tasks. To address this problem, we propose a novel and effective fine-tuning framework, named Layerwise Noise Stability Regularization (LNSR). Specifically, we propose to inject the standard Gaussian noise or In-manifold noise and regularize hidden representations of the fine-tuned model. We first provide theoretical analyses to support the efficacy of our method. We then demonstrate the advantages of the proposed method over other state-of-the-art algorithms including L2-SP, Mixout and SMART. While these previous works only verify the effectiveness of their methods on relatively simple text classification tasks, we also verify the effectiveness of our method on question answering tasks, where the target problem is much more difficult and more training examples are available. Furthermore, extensive experimental results indicate that the proposed algorithm can not only enhance the in-domain performance of the language models but also improve the domain generalization performance on out-of-domain data.
Deep Active Learning with Noise Stability
May 26, 2022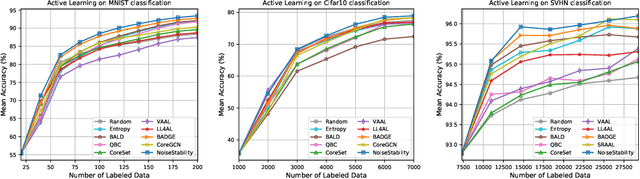
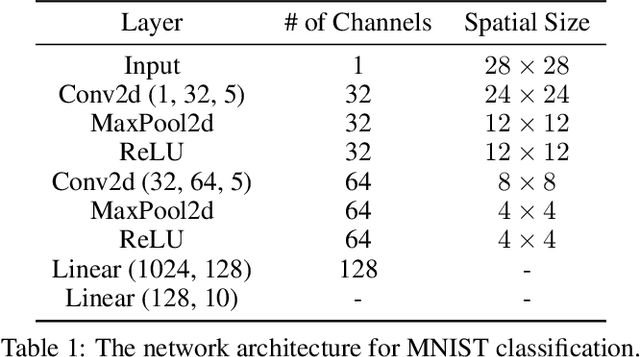
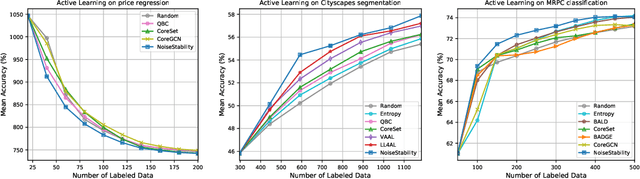
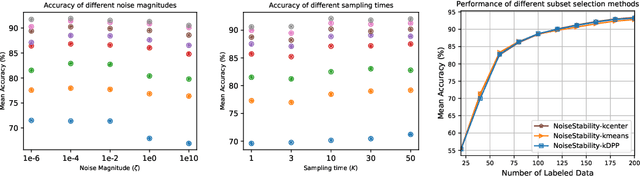
Uncertainty estimation for unlabeled data is crucial to active learning. With a deep neural network employed as the backbone model, the data selection process is highly challenging due to the potential over-confidence of the model inference. Existing methods resort to special learning fashions (e.g. adversarial) or auxiliary models to address this challenge. This tends to result in complex and inefficient pipelines, which would render the methods impractical. In this work, we propose a novel algorithm that leverages noise stability to estimate data uncertainty in a Single-Training Multi-Inference fashion. The key idea is to measure the output derivation from the original observation when the model parameters are randomly perturbed by noise. We provide theoretical analyses by leveraging the small Gaussian noise theory and demonstrate that our method favors a subset with large and diverse gradients. Despite its simplicity, our method outperforms the state-of-the-art active learning baselines in various tasks, including computer vision, natural language processing, and structural data analysis.
Inadequately Pre-trained Models are Better Feature Extractors
Mar 09, 2022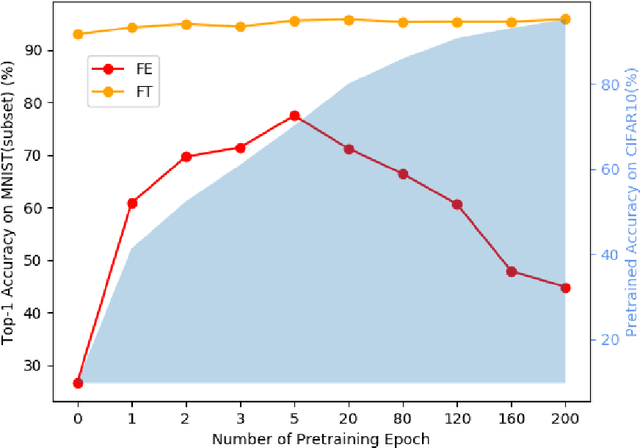
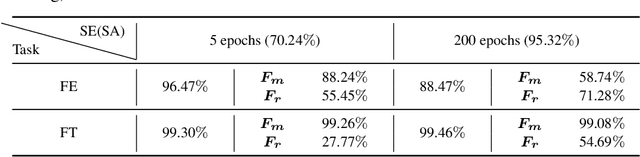
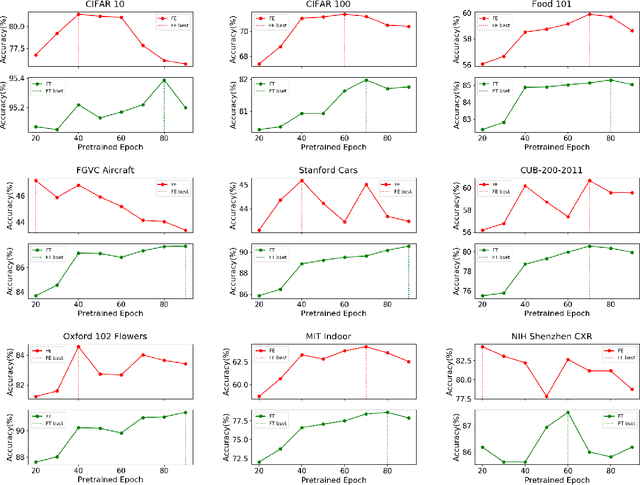
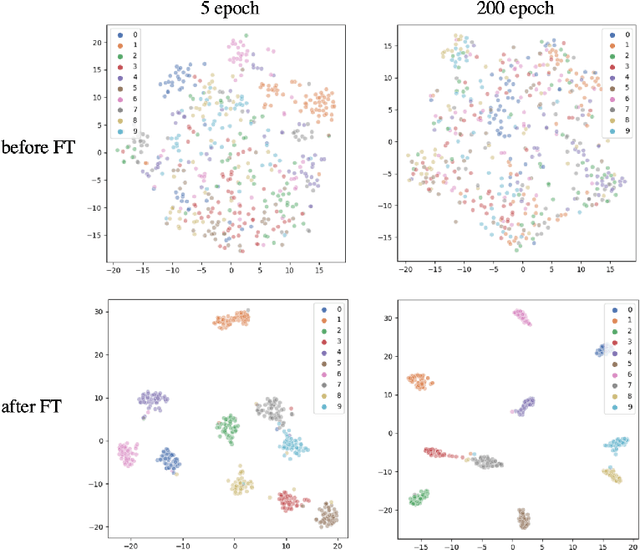
Pre-training has been a popular learning paradigm in deep learning era, especially in annotation-insufficient scenario. Better ImageNet pre-trained models have been demonstrated, from the perspective of architecture, by previous research to have better transferability to downstream tasks. However, in this paper, we found that during the same pre-training process, models at middle epochs, which is inadequately pre-trained, can outperform fully trained models when used as feature extractors (FE), while the fine-tuning (FT) performance still grows with the source performance. This reveals that there is not a solid positive correlation between top-1 accuracy on ImageNet and the transferring result on target data. Based on the contradictory phenomenon between FE and FT that better feature extractor fails to be fine-tuned better accordingly, we conduct comprehensive analyses on features before softmax layer to provide insightful explanations. Our discoveries suggest that, during pre-training, models tend to first learn spectral components corresponding to large singular values and the residual components contribute more when fine-tuning.
Boosting Active Learning via Improving Test Performance
Dec 10, 2021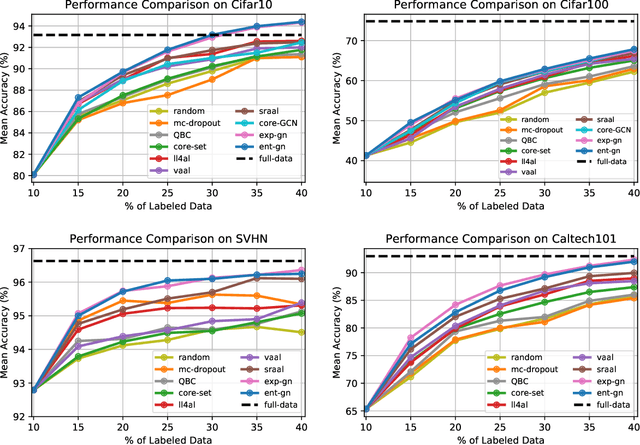

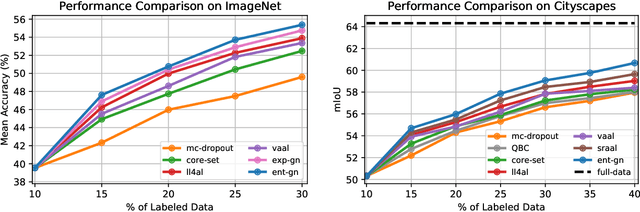
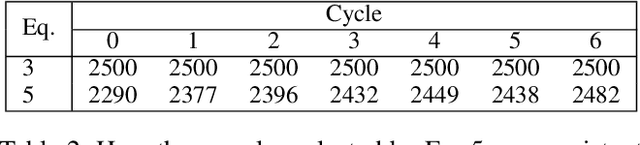
Central to active learning (AL) is what data should be selected for annotation. Existing works attempt to select highly uncertain or informative data for annotation. Nevertheless, it remains unclear how selected data impacts the test performance of the task model used in AL. In this work, we explore such an impact by theoretically proving that selecting unlabeled data of higher gradient norm leads to a lower upper bound of test loss, resulting in a better test performance. However, due to the lack of label information, directly computing gradient norm for unlabeled data is infeasible. To address this challenge, we propose two schemes, namely expected-gradnorm and entropy-gradnorm. The former computes the gradient norm by constructing an expected empirical loss while the latter constructs an unsupervised loss with entropy. Furthermore, we integrate the two schemes in a universal AL framework. We evaluate our method on classical image classification and semantic segmentation tasks. To demonstrate its competency in domain applications and its robustness to noise, we also validate our method on a cellular imaging analysis task, namely cryo-Electron Tomography subtomogram classification. Results demonstrate that our method achieves superior performance against the state-of-the-art. Our source code is available at https://github.com/xulabs/aitom
* 13 pages
Noise Stability Regularization for Improving BERT Fine-tuning
Jul 10, 2021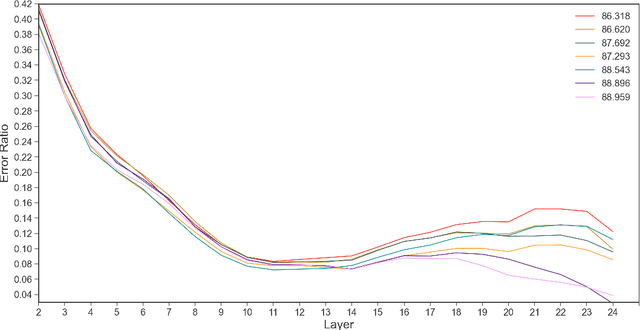
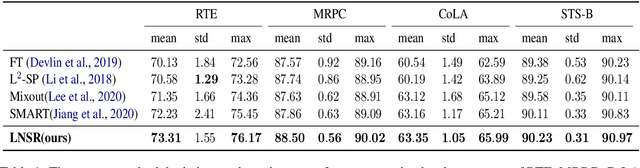

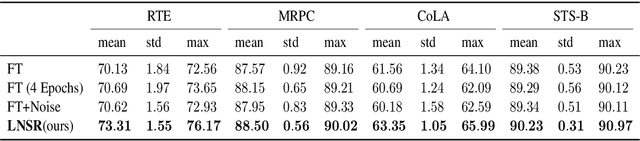
Fine-tuning pre-trained language models such as BERT has become a common practice dominating leaderboards across various NLP tasks. Despite its recent success and wide adoption, this process is unstable when there are only a small number of training samples available. The brittleness of this process is often reflected by the sensitivity to random seeds. In this paper, we propose to tackle this problem based on the noise stability property of deep nets, which is investigated in recent literature (Arora et al., 2018; Sanyal et al., 2020). Specifically, we introduce a novel and effective regularization method to improve fine-tuning on NLP tasks, referred to as Layer-wise Noise Stability Regularization (LNSR). We extend the theories about adding noise to the input and prove that our method gives a stabler regularization effect. We provide supportive evidence by experimentally confirming that well-performing models show a low sensitivity to noise and fine-tuning with LNSR exhibits clearly higher generalizability and stability. Furthermore, our method also demonstrates advantages over other state-of-the-art algorithms including L2-SP (Li et al., 2018), Mixout (Lee et al., 2020) and SMART (Jiang et al., 2020).
SMILE: Self-Distilled MIxup for Efficient Transfer LEarning
Mar 25, 2021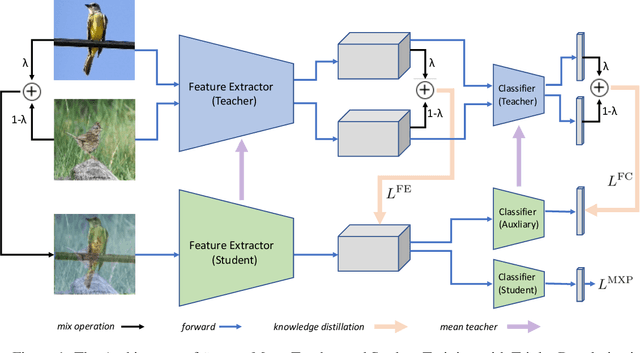
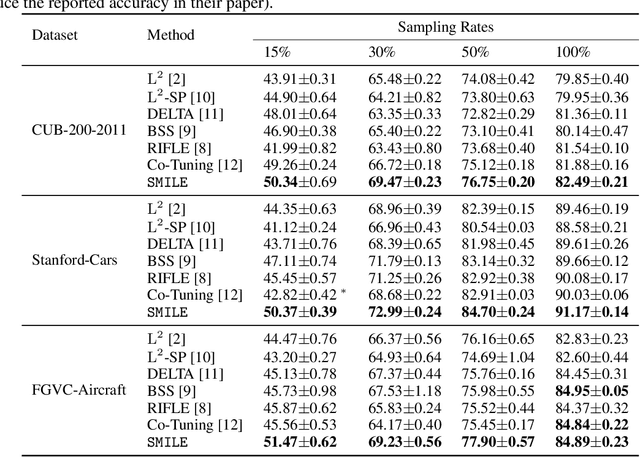
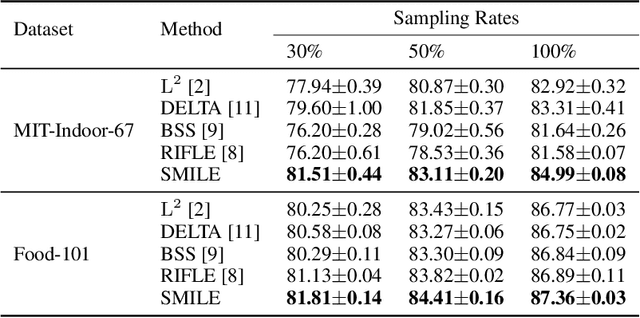
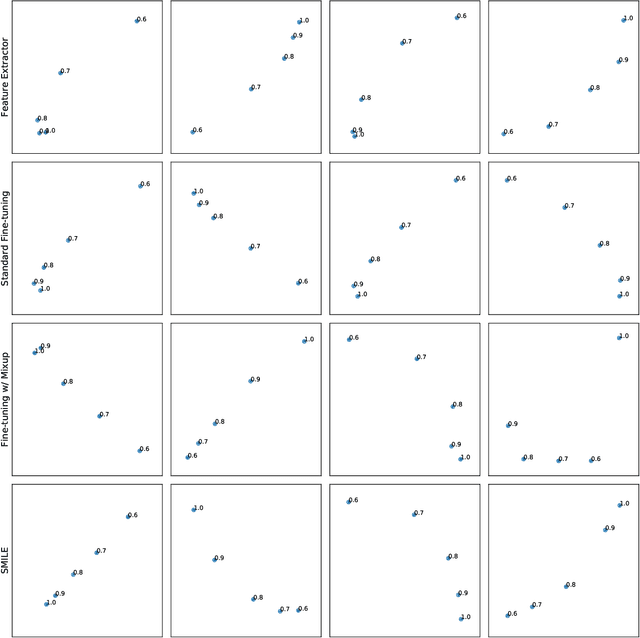
To improve the performance of deep learning, mixup has been proposed to force the neural networks favoring simple linear behaviors in-between training samples. Performing mixup for transfer learning with pre-trained models however is not that simple, a high capacity pre-trained model with a large fully-connected (FC) layer could easily overfit to the target dataset even with samples-to-labels mixed up. In this work, we propose SMILE - Self-Distilled Mixup for EffIcient Transfer LEarning. With mixed images as inputs, SMILE regularizes the outputs of CNN feature extractors to learn from the mixed feature vectors of inputs (sample-to-feature mixup), in addition to the mixed labels. Specifically, SMILE incorporates a mean teacher, inherited from the pre-trained model, to provide the feature vectors of input samples in a self-distilling fashion, and mixes up the feature vectors accordingly via a novel triplet regularizer. The triple regularizer balances the mixup effects in both feature and label spaces while bounding the linearity in-between samples for pre-training tasks. Extensive experiments have been done to verify the performance improvement made by SMILE, in comparisons with a wide spectrum of transfer learning algorithms, including fine-tuning, L2-SP, DELTA, and RIFLE, even with mixup strategies combined. Ablation studies show that the vanilla sample-to-label mixup strategies could marginally increase the linearity in-between training samples but lack of generalizability, while SMILE significantly improve the mixup effects in both label and feature spaces with both training and testing datasets. The empirical observations backup our design intuition and purposes.
Interpretable Deep Learning: Interpretations, Interpretability, Trustworthiness, and Beyond
Mar 19, 2021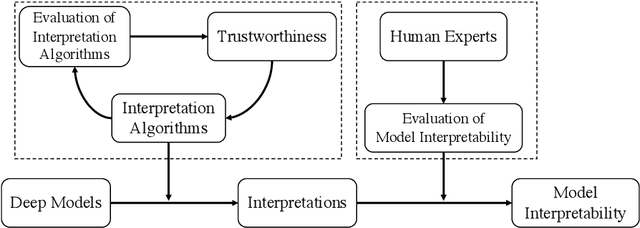
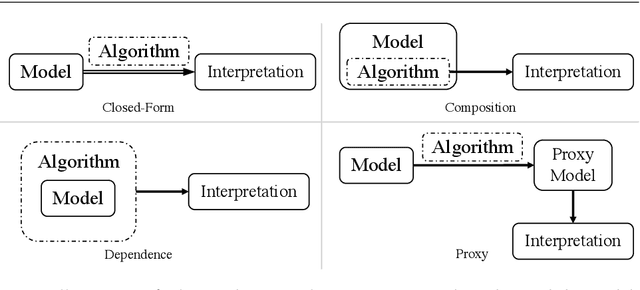
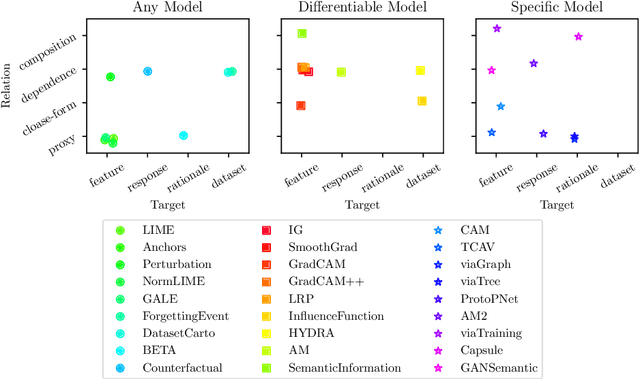

Deep neural networks have been well-known for their superb performance in handling various machine learning and artificial intelligence tasks. However, due to their over-parameterized black-box nature, it is often difficult to understand the prediction results of deep models. In recent years, many interpretation tools have been proposed to explain or reveal the ways that deep models make decisions. In this paper, we review this line of research and try to make a comprehensive survey. Specifically, we introduce and clarify two basic concepts-interpretations and interpretability-that people usually get confused. First of all, to address the research efforts in interpretations, we elaborate the design of several recent interpretation algorithms, from different perspectives, through proposing a new taxonomy. Then, to understand the results of interpretation, we also survey the performance metrics for evaluating interpretation algorithms. Further, we summarize the existing work in evaluating models' interpretability using "trustworthy" interpretation algorithms. Finally, we review and discuss the connections between deep models' interpretations and other factors, such as adversarial robustness and data augmentations, and we introduce several open-source libraries for interpretation algorithms and evaluation approaches.
Adaptive Consistency Regularization for Semi-Supervised Transfer Learning
Mar 03, 2021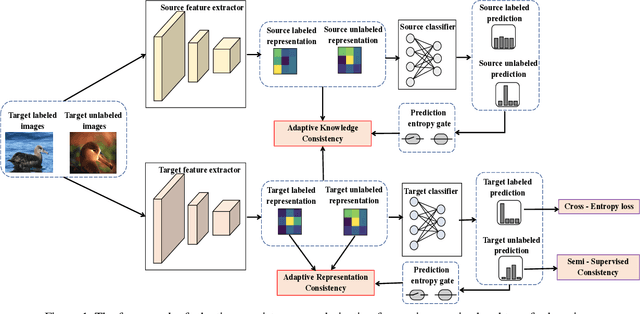
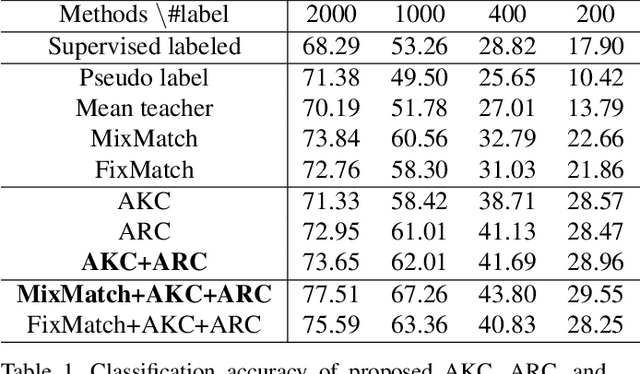
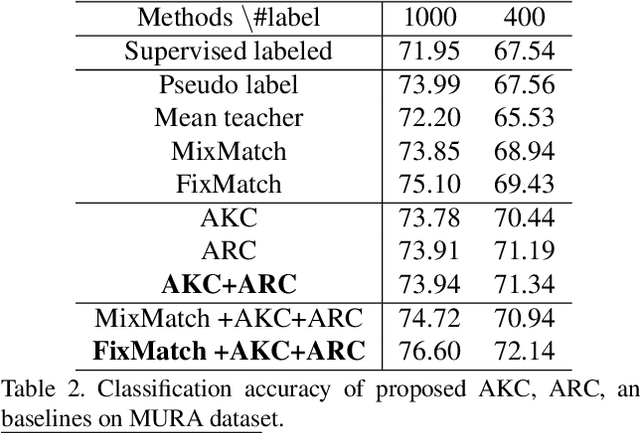
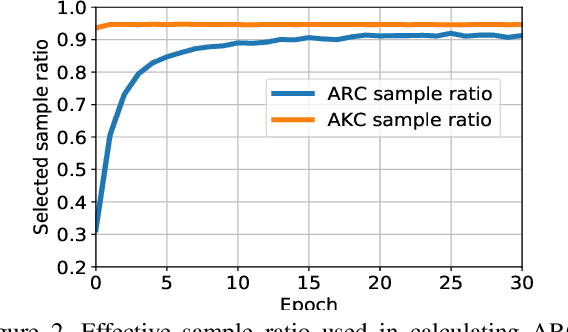
While recent studies on semi-supervised learning have shown remarkable progress in leveraging both labeled and unlabeled data, most of them presume a basic setting of the model is randomly initialized. In this work, we consider semi-supervised learning and transfer learning jointly, leading to a more practical and competitive paradigm that can utilize both powerful pre-trained models from source domain as well as labeled/unlabeled data in the target domain. To better exploit the value of both pre-trained weights and unlabeled target examples, we introduce adaptive consistency regularization that consists of two complementary components: Adaptive Knowledge Consistency (AKC) on the examples between the source and target model, and Adaptive Representation Consistency (ARC) on the target model between labeled and unlabeled examples. Examples involved in the consistency regularization are adaptively selected according to their potential contributions to the target task. We conduct extensive experiments on several popular benchmarks including CUB-200-2011, MIT Indoor-67, MURA, by fine-tuning the ImageNet pre-trained ResNet-50 model. Results show that our proposed adaptive consistency regularization outperforms state-of-the-art semi-supervised learning techniques such as Pseudo Label, Mean Teacher, and MixMatch. Moreover, our algorithm is orthogonal to existing methods and thus able to gain additional improvements on top of MixMatch and FixMatch. Our code is available at https://github.com/SHI-Labs/Semi-Supervised-Transfer-Learning.