 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRE-TRAC: REcursive TRAjectory Compression for Deep Search Agents
Feb 02, 2026LLM-based deep research agents are largely built on the ReAct framework. This linear design makes it difficult to revisit earlier states, branch into alternative search directions, or maintain global awareness under long contexts, often leading to local optima, redundant exploration, and inefficient search. We propose Re-TRAC, an agentic framework that performs cross-trajectory exploration by generating a structured state representation after each trajectory to summarize evidence, uncertainties, failures, and future plans, and conditioning subsequent trajectories on this state representation. This enables iterative reflection and globally informed planning, reframing research as a progressive process. Empirical results show that Re-TRAC consistently outperforms ReAct by 15-20% on BrowseComp with frontier LLMs. For smaller models, we introduce Re-TRAC-aware supervised fine-tuning, achieving state-of-the-art performance at comparable scales. Notably, Re-TRAC shows a monotonic reduction in tool calls and token usage across rounds, indicating progressively targeted exploration driven by cross-trajectory reflection rather than redundant search.
Positive-Unlabeled Reinforcement Learning Distillation for On-Premise Small Models
Jan 28, 2026Due to constraints on privacy, cost, and latency, on-premise deployment of small models is increasingly common. However, most practical pipelines stop at supervised fine-tuning (SFT) and fail to reach the reinforcement learning (RL) alignment stage. The main reason is that RL alignment typically requires either expensive human preference annotation or heavy reliance on high-quality reward models with large-scale API usage and ongoing engineering maintenance, both of which are ill-suited to on-premise settings. To bridge this gap, we propose a positive-unlabeled (PU) RL distillation method for on-premise small-model deployment. Without human-labeled preferences or a reward model, our method distills the teacher's preference-optimization capability from black-box generations into a locally trainable student. For each prompt, we query the teacher once to obtain an anchor response, locally sample multiple student candidates, and perform anchor-conditioned self-ranking to induce pairwise or listwise preferences, enabling a fully local training loop via direct preference optimization or group relative policy optimization. Theoretical analysis justifies that the induced preference signal by our method is order-consistent and concentrates on near-optimal candidates, supporting its stability for preference optimization. Experiments demonstrate that our method achieves consistently strong performance under a low-cost setting.
Self-Supervised Weight Templates for Scalable Vision Model Initialization
Jan 27, 2026The increasing scale and complexity of modern model parameters underscore the importance of pre-trained models. However, deployment often demands architectures of varying sizes, exposing limitations of conventional pre-training and fine-tuning. To address this, we propose SWEET, a self-supervised framework that performs constraint-based pre-training to enable scalable initialization in vision tasks. Instead of pre-training a fixed-size model, we learn a shared weight template and size-specific weight scalers under Tucker-based factorization, which promotes modularity and supports flexible adaptation to architectures with varying depths and widths. Target models are subsequently initialized by composing and reweighting the template through lightweight weight scalers, whose parameters can be efficiently learned from minimal training data. To further enhance flexibility in width expansion, we introduce width-wise stochastic scaling, which regularizes the template along width-related dimensions and encourages robust, width-invariant representations for improved cross-width generalization. Extensive experiments on \textsc{classification}, \textsc{detection}, \textsc{segmentation} and \textsc{generation} tasks demonstrate the state-of-the-art performance of SWEET for initializing variable-sized vision models.
Fast Inference of Visual Autoregressive Model with Adjacency-Adaptive Dynamical Draft Trees
Dec 26, 2025



Autoregressive (AR) image models achieve diffusion-level quality but suffer from sequential inference, requiring approximately 2,000 steps for a 576x576 image. Speculative decoding with draft trees accelerates LLMs yet underperforms on visual AR models due to spatially varying token prediction difficulty. We identify a key obstacle in applying speculative decoding to visual AR models: inconsistent acceptance rates across draft trees due to varying prediction difficulties in different image regions. We propose Adjacency-Adaptive Dynamical Draft Trees (ADT-Tree), an adjacency-adaptive dynamic draft tree that dynamically adjusts draft tree depth and width by leveraging adjacent token states and prior acceptance rates. ADT-Tree initializes via horizontal adjacency, then refines depth/width via bisectional adaptation, yielding deeper trees in simple regions and wider trees in complex ones. The empirical evaluations on MS-COCO 2017 and PartiPrompts demonstrate that ADT-Tree achieves speedups of 3.13xand 3.05x, respectively. Moreover, it integrates seamlessly with relaxed sampling methods such as LANTERN, enabling further acceleration. Code is available at https://github.com/Haodong-Lei-Ray/ADT-Tree.
Knowledge Diversion for Efficient Morphology Control and Policy Transfer
Dec 10, 2025Universal morphology control aims to learn a universal policy that generalizes across heterogeneous agent morphologies, with Transformer-based controllers emerging as a popular choice. However, such architectures incur substantial computational costs, resulting in high deployment overhead, and existing methods exhibit limited cross-task generalization, necessitating training from scratch for each new task. To this end, we propose \textbf{DivMorph}, a modular training paradigm that leverages knowledge diversion to learn decomposable controllers. DivMorph factorizes randomly initialized Transformer weights into factor units via SVD prior to training and employs dynamic soft gating to modulate these units based on task and morphology embeddings, separating them into shared \textit{learngenes} and morphology- and task-specific \textit{tailors}, thereby achieving knowledge disentanglement. By selectively activating relevant components, DivMorph enables scalable and efficient policy deployment while supporting effective policy transfer to novel tasks. Extensive experiments demonstrate that DivMorph achieves state-of-the-art performance, achieving a 3$\times$ improvement in sample efficiency over direct finetuning for cross-task transfer and a 17$\times$ reduction in model size for single-agent deployment.
Stratified Knowledge-Density Super-Network for Scalable Vision Transformers
Nov 12, 2025Training and deploying multiple vision transformer (ViT) models for different resource constraints is costly and inefficient. To address this, we propose transforming a pre-trained ViT into a stratified knowledge-density super-network, where knowledge is hierarchically organized across weights. This enables flexible extraction of sub-networks that retain maximal knowledge for varying model sizes. We introduce \textbf{W}eighted \textbf{P}CA for \textbf{A}ttention \textbf{C}ontraction (WPAC), which concentrates knowledge into a compact set of critical weights. WPAC applies token-wise weighted principal component analysis to intermediate features and injects the resulting transformation and inverse matrices into adjacent layers, preserving the original network function while enhancing knowledge compactness. To further promote stratified knowledge organization, we propose \textbf{P}rogressive \textbf{I}mportance-\textbf{A}ware \textbf{D}ropout (PIAD). PIAD progressively evaluates the importance of weight groups, updates an importance-aware dropout list, and trains the super-network under this dropout regime to promote knowledge stratification. Experiments demonstrate that WPAC outperforms existing pruning criteria in knowledge concentration, and the combination with PIAD offers a strong alternative to state-of-the-art model compression and model expansion methods.
* Accepted by AAAI 2026
One-Shot Knowledge Transfer for Scalable Person Re-Identification
Nov 08, 2025



Edge computing in person re-identification (ReID) is crucial for reducing the load on central cloud servers and ensuring user privacy. Conventional compression methods for obtaining compact models require computations for each individual student model. When multiple models of varying sizes are needed to accommodate different resource conditions, this leads to repetitive and cumbersome computations. To address this challenge, we propose a novel knowledge inheritance approach named OSKT (One-Shot Knowledge Transfer), which consolidates the knowledge of the teacher model into an intermediate carrier called a weight chain. When a downstream scenario demands a model that meets specific resource constraints, this weight chain can be expanded to the target model size without additional computation. OSKT significantly outperforms state-of-the-art compression methods, with the added advantage of one-time knowledge transfer that eliminates the need for frequent computations for each target model.
* Accepted by ICCV 2025
Enriching Knowledge Distillation with Intra-Class Contrastive Learning
Sep 26, 2025Since the advent of knowledge distillation, much research has focused on how the soft labels generated by the teacher model can be utilized effectively. Existing studies points out that the implicit knowledge within soft labels originates from the multi-view structure present in the data. Feature variations within samples of the same class allow the student model to generalize better by learning diverse representations. However, in existing distillation methods, teacher models predominantly adhere to ground-truth labels as targets, without considering the diverse representations within the same class. Therefore, we propose incorporating an intra-class contrastive loss during teacher training to enrich the intra-class information contained in soft labels. In practice, we find that intra-class loss causes instability in training and slows convergence. To mitigate these issues, margin loss is integrated into intra-class contrastive learning to improve the training stability and convergence speed. Simultaneously, we theoretically analyze the impact of this loss on the intra-class distances and inter-class distances. It has been proved that the intra-class contrastive loss can enrich the intra-class diversity. Experimental results demonstrate the effectiveness of the proposed method.
Towards Understanding Feature Learning in Parameter Transfer
Sep 26, 2025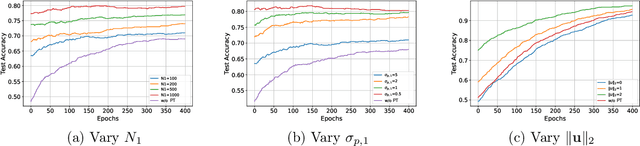
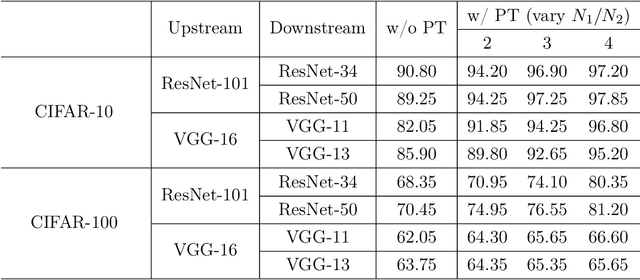
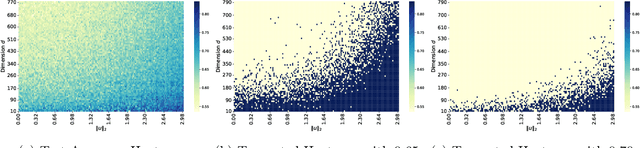
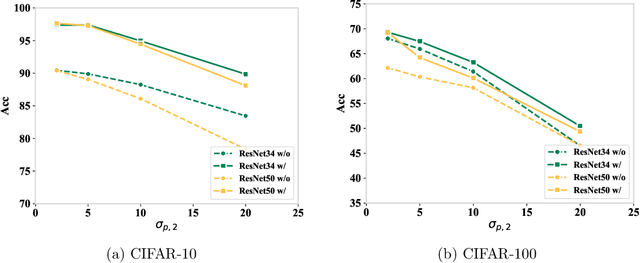
Parameter transfer is a central paradigm in transfer learning, enabling knowledge reuse across tasks and domains by sharing model parameters between upstream and downstream models. However, when only a subset of parameters from the upstream model is transferred to the downstream model, there remains a lack of theoretical understanding of the conditions under which such partial parameter reuse is beneficial and of the factors that govern its effectiveness. To address this gap, we analyze a setting in which both the upstream and downstream models are ReLU convolutional neural networks (CNNs). Within this theoretical framework, we characterize how the inherited parameters act as carriers of universal knowledge and identify key factors that amplify their beneficial impact on the target task. Furthermore, our analysis provides insight into why, in certain cases, transferring parameters can lead to lower test accuracy on the target task than training a new model from scratch. Numerical experiments and real-world data experiments are conducted to empirically validate our theoretical findings.
Foundation Model for Skeleton-Based Human Action Understanding
Aug 18, 2025Human action understanding serves as a foundational pillar in the field of intelligent motion perception. Skeletons serve as a modality- and device-agnostic representation for human modeling, and skeleton-based action understanding has potential applications in humanoid robot control and interaction. \RED{However, existing works often lack the scalability and generalization required to handle diverse action understanding tasks. There is no skeleton foundation model that can be adapted to a wide range of action understanding tasks}. This paper presents a Unified Skeleton-based Dense Representation Learning (USDRL) framework, which serves as a foundational model for skeleton-based human action understanding. USDRL consists of a Transformer-based Dense Spatio-Temporal Encoder (DSTE), Multi-Grained Feature Decorrelation (MG-FD), and Multi-Perspective Consistency Training (MPCT). The DSTE module adopts two parallel streams to learn temporal dynamic and spatial structure features. The MG-FD module collaboratively performs feature decorrelation across temporal, spatial, and instance domains to reduce dimensional redundancy and enhance information extraction. The MPCT module employs both multi-view and multi-modal self-supervised consistency training. The former enhances the learning of high-level semantics and mitigates the impact of low-level discrepancies, while the latter effectively facilitates the learning of informative multimodal features. We perform extensive experiments on 25 benchmarks across across 9 skeleton-based action understanding tasks, covering coarse prediction, dense prediction, and transferred prediction. Our approach significantly outperforms the current state-of-the-art methods. We hope that this work would broaden the scope of research in skeleton-based action understanding and encourage more attention to dense prediction tasks.