 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAll-to-key Attention for Arbitrary Style Transfer
Dec 08, 2022Attention-based arbitrary style transfer studies have shown promising performance in synthesizing vivid local style details. They typically use the all-to-all attention mechanism: each position of content features is fully matched to all positions of style features. However, all-to-all attention tends to generate distorted style patterns and has quadratic complexity. It virtually limits both the effectiveness and efficiency of arbitrary style transfer. In this paper, we rethink what kind of attention mechanism is more appropriate for arbitrary style transfer. Our answer is a novel all-to-key attention mechanism: each position of content features is matched to key positions of style features. Specifically, it integrates two newly proposed attention forms: distributed and progressive attention. Distributed attention assigns attention to multiple key positions; Progressive attention pays attention from coarse to fine. All-to-key attention promotes the matching of diverse and reasonable style patterns and has linear complexity. The resultant module, dubbed StyA2K, has fine properties in rendering reasonable style textures and maintaining consistent local structure. Qualitative and quantitative experiments demonstrate that our method achieves superior results than state-of-the-art approaches.
Deep Active Learning for Computer Vision: Past and Future
Nov 27, 2022



As an important data selection schema, active learning emerges as the essential component when iterating an Artificial Intelligence (AI) model. It becomes even more critical given the dominance of deep neural network based models, which are composed of a large number of parameters and data hungry, in application. Despite its indispensable role for developing AI models, research on active learning is not as intensive as other research directions. In this paper, we present a review of active learning through deep active learning approaches from the following perspectives: 1) technical advancements in active learning, 2) applications of active learning in computer vision, 3) industrial systems leveraging or with potential to leverage active learning for data iteration, 4) current limitations and future research directions. We expect this paper to clarify the significance of active learning in a modern AI model manufacturing process and to bring additional research attention to active learning. By addressing data automation challenges and coping with automated machine learning systems, active learning will facilitate democratization of AI technologies by boosting model production at scale.
A Critical Review of Traffic Signal Control and A Novel Unified View of Reinforcement Learning and Model Predictive Control Approaches for Adaptive Traffic Signal Control
Nov 26, 2022Recent years have witnessed substantial growth in adaptive traffic signal control (ATSC) methodologies that improve transportation network efficiency, especially in branches leveraging artificial intelligence based optimization and control algorithms such as reinforcement learning as well as conventional model predictive control. However, lack of cross-domain analysis and comparison of the effectiveness of applied methods in ATSC research limits our understanding of existing challenges and research directions. This chapter proposes a novel unified view of modern ATSCs to identify common ground as well as differences and shortcomings of existing methodologies with the ultimate goal to facilitate cross-fertilization and advance the state-of-the-art. The unified view applies the mathematical language of the Markov decision process, describes the process of controller design from both the world (problem) and solution modeling perspectives. The unified view also analyses systematic issues commonly ignored in existing studies and suggests future potential directions to resolve these issues.
DYNAFED: Tackling Client Data Heterogeneity with Global Dynamics
Nov 20, 2022The Federated Learning (FL) paradigm is known to face challenges under heterogeneous client data. Local training on non-iid distributed data results in deflected local optimum, which causes the client models drift further away from each other and degrades the aggregated global model's performance. A natural solution is to gather all client data onto the server, such that the server has a global view of the entire data distribution. Unfortunately, this reduces to regular training, which compromises clients' privacy and conflicts with the purpose of FL. In this paper, we put forth an idea to collect and leverage global knowledge on the server without hindering data privacy. We unearth such knowledge from the dynamics of the global model's trajectory. Specifically, we first reserve a short trajectory of global model snapshots on the server. Then, we synthesize a small pseudo dataset such that the model trained on it mimics the dynamics of the reserved global model trajectory. Afterward, the synthesized data is used to help aggregate the deflected clients into the global model. We name our method Dynafed, which enjoys the following advantages: 1) we do not rely on any external on-server dataset, which requires no additional cost for data collection; 2) the pseudo data can be synthesized in early communication rounds, which enables Dynafed to take effect early for boosting the convergence and stabilizing training; 3) the pseudo data only needs to be synthesized once and can be directly utilized on the server to help aggregation in subsequent rounds. Experiments across extensive benchmarks are conducted to showcase the effectiveness of Dynafed. We also provide insights and understanding of the underlying mechanism of our method.
NAR-Former: Neural Architecture Representation Learning towards Holistic Attributes Prediction
Nov 15, 2022



With the wide and deep adoption of deep learning models in real applications, there is an increasing need to model and learn the representations of the neural networks themselves. These models can be used to estimate attributes of different neural network architectures such as the accuracy and latency, without running the actual training or inference tasks. In this paper, we propose a neural architecture representation model that can be used to estimate these attributes holistically. Specifically, we first propose a simple and effective tokenizer to encode both the operation and topology information of a neural network into a single sequence. Then, we design a multi-stage fusion transformer to build a compact vector representation from the converted sequence. For efficient model training, we further propose an information flow consistency augmentation and correspondingly design an architecture consistency loss, which brings more benefits with less augmentation samples compared with previous random augmentation strategies. Experiment results on NAS-Bench-101, NAS-Bench-201, DARTS search space and NNLQP show that our proposed framework can be used to predict the aforementioned latency and accuracy attributes of both cell architectures and whole deep neural networks, and achieves promising performance.
ParCNetV2: Oversized Kernel with Enhanced Attention
Nov 14, 2022



Transformers have achieved tremendous success in various computer vision tasks. By borrowing design concepts from transformers, many studies revolutionized CNNs and showed remarkable results. This paper falls in this line of studies. More specifically, we introduce a convolutional neural network architecture named ParCNetV2, which extends position-aware circular convolution (ParCNet) with oversized convolutions and strengthens attention through bifurcate gate units. The oversized convolution utilizes a kernel with $2\times$ the input size to model long-range dependencies through a global receptive field. Simultaneously, it achieves implicit positional encoding by removing the shift-invariant property from convolutional kernels, i.e., the effective kernels at different spatial locations are different when the kernel size is twice as large as the input size. The bifurcate gate unit implements an attention mechanism similar to self-attention in transformers. It splits the input into two branches, one serves as feature transformation while the other serves as attention weights. The attention is applied through element-wise multiplication of the two branches. Besides, we introduce a unified local-global convolution block to unify the design of the early and late stage convolutional blocks. Extensive experiments demonstrate that our method outperforms other pure convolutional neural networks as well as neural networks hybridizing CNNs and transformers.
CabViT: Cross Attention among Blocks for Vision Transformer
Nov 14, 2022



Since the vision transformer (ViT) has achieved impressive performance in image classification, an increasing number of researchers pay their attentions to designing more efficient vision transformer models. A general research line is reducing computational cost of self attention modules by adopting sparse attention or using local attention windows. In contrast, we propose to design high performance transformer based architectures by densifying the attention pattern. Specifically, we propose cross attention among blocks of ViT (CabViT), which uses tokens from previous blocks in the same stage as extra input to the multi-head attention of transformers. The proposed CabViT enhances the interactions of tokens across blocks with potentially different semantics, and encourages more information flows to the lower levels, which together improves model performance and model convergence with limited extra cost. Based on the proposed CabViT, we design a series of CabViT models which achieve the best trade-off between model size, computational cost and accuracy. For instance without the need of knowledge distillation to strength the training, CabViT achieves 83.0% top-1 accuracy on Imagenet with only 16.3 million parameters and about 3.9G FLOPs, saving almost half parameters and 13% computational cost while gaining 0.9% higher accuracy compared with ConvNext, use 52% of parameters but gaining 0.6% accuracy compared with distilled EfficientFormer
A Multi-modal Deformable Land-air Robot for Complex Environments
Nov 01, 2022



Single locomotion robots often struggle to adapt in highly variable or uncertain environments, especially in emergencies. In this paper, a multi-modal deformable robot is introduced that can both fly and drive. Compatibility issues with multi-modal locomotive fusion for this hybrid land-air robot are solved using proposed design conceptions, including power settings, energy selection, and designs of deformable structure. The robot can also automatically transform between land and air modes during 3D planning and tracking. Meanwhile, we proposed a algorithms for evaluation the performance of land-air robots. A series of comparisons and experiments were conducted to demonstrate the robustness and reliability of the proposed structure in complex field environments.
Fast-ParC: Position Aware Global Kernel for ConvNets and ViTs
Oct 08, 2022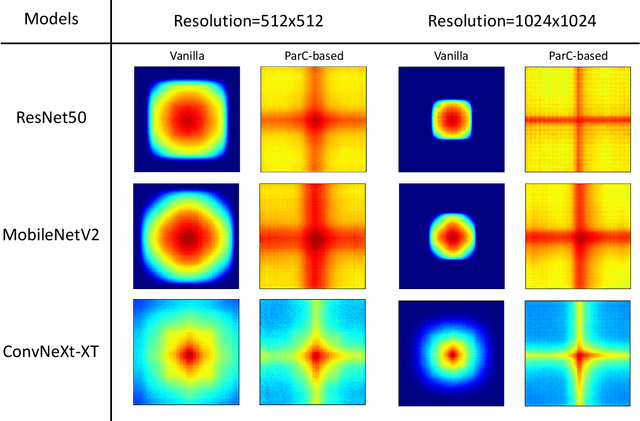

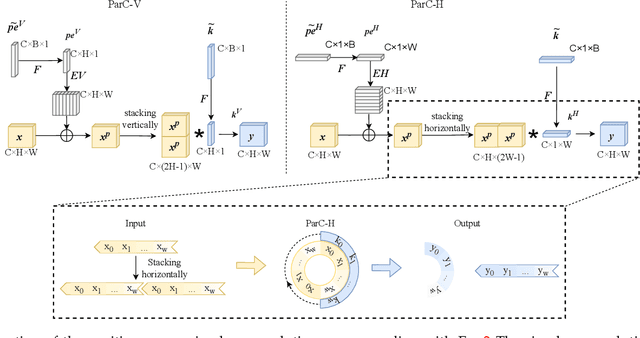
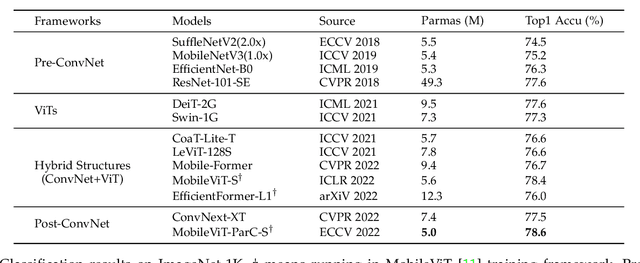
Transformer models have made tremendous progress in various fields in recent years. In the field of computer vision, vision transformers (ViTs) also become strong alternatives to convolutional neural networks (ConvNets), yet they have not been able to replace ConvNets since both have their own merits. For instance, ViTs are good at extracting global features with attention mechanisms while ConvNets are more efficient in modeling local relationships due to their strong inductive bias. A natural idea that arises is to combine the strengths of both ConvNets and ViTs to design new structures. In this paper, we propose a new basic neural network operator named position-aware circular convolution (ParC) and its accelerated version Fast-ParC. The ParC operator can capture global features by using a global kernel and circular convolution while keeping location sensitiveness by employing position embeddings. Our Fast-ParC further reduces the O(n2) time complexity of ParC to O(n log n) using Fast Fourier Transform. This acceleration makes it possible to use global convolution in the early stages of models with large feature maps, yet still maintains the overall computational cost comparable with using 3x3 or 7x7 kernels. The proposed operation can be used in a plug-and-play manner to 1) convert ViTs to pure-ConvNet architecture to enjoy wider hardware support and achieve higher inference speed; 2) replacing traditional convolutions in the deep stage of ConvNets to improve accuracy by enlarging the effective receptive field. Experiment results show that our ParC op can effectively enlarge the receptive field of traditional ConvNets, and adopting the proposed op benefits both ViTs and ConvNet models on all three popular vision tasks, image classification, object
Conservative Bayesian Model-Based Value Expansion for Offline Policy Optimization
Oct 07, 2022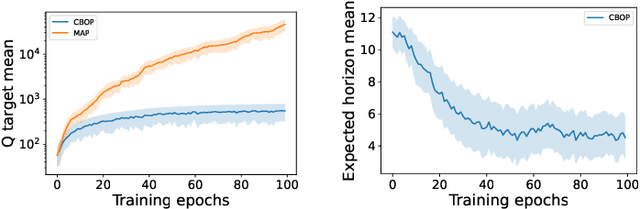
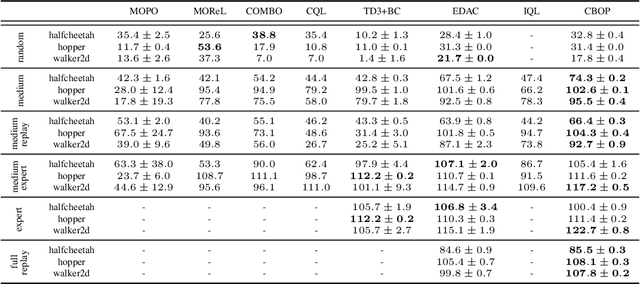
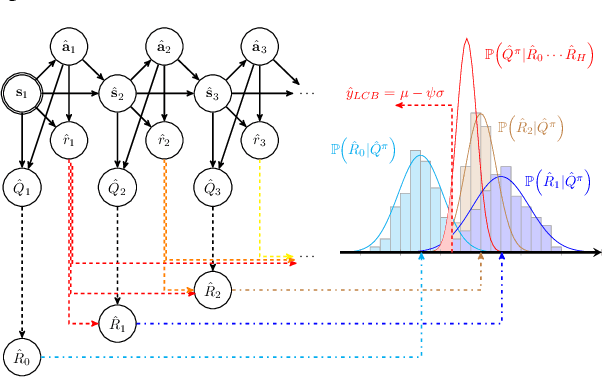
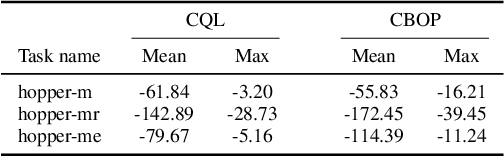
Offline reinforcement learning (RL) addresses the problem of learning a performant policy from a fixed batch of data collected by following some behavior policy. Model-based approaches are particularly appealing in the offline setting since they can extract more learning signals from the logged dataset by learning a model of the environment. However, the performance of existing model-based approaches falls short of model-free counterparts, due to the compounding of estimation errors in the learned model. Driven by this observation, we argue that it is critical for a model-based method to understand when to trust the model and when to rely on model-free estimates, and how to act conservatively w.r.t. both. To this end, we derive an elegant and simple methodology called conservative Bayesian model-based value expansion for offline policy optimization (CBOP), that trades off model-free and model-based estimates during the policy evaluation step according to their epistemic uncertainties, and facilitates conservatism by taking a lower bound on the Bayesian posterior value estimate. On the standard D4RL continuous control tasks, we find that our method significantly outperforms previous model-based approaches: e.g., MOPO by $116.4$%, MOReL by $23.2$% and COMBO by $23.7$%. Further, CBOP achieves state-of-the-art performance on $11$ out of $18$ benchmark datasets while doing on par on the remaining datasets.