 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgedeFOREST: Fusing Optical and Radar satellite data for Enhanced Sensing of Tree-loss
Oct 15, 2025In this paper we develop a deforestation detection pipeline that incorporates optical and Synthetic Aperture Radar (SAR) data. A crucial component of the pipeline is the construction of anomaly maps of the optical data, which is done using the residual space of a discrete Karhunen-Lo\`{e}ve (KL) expansion. Anomalies are quantified using a concentration bound on the distribution of the residual components for the nominal state of the forest. This bound does not require prior knowledge on the distribution of the data. This is in contrast to statistical parametric methods that assume knowledge of the data distribution, an impractical assumption that is especially infeasible for high dimensional data such as ours. Once the optical anomaly maps are computed they are combined with SAR data, and the state of the forest is classified by using a Hidden Markov Model (HMM). We test our approach with Sentinel-1 (SAR) and Sentinel-2 (Optical) data on a $92.19\,km \times 91.80\,km$ region in the Amazon forest. The results show that both the hybrid optical-radar and optical only methods achieve high accuracy that is superior to the recent state-of-the-art hybrid method. Moreover, the hybrid method is significantly more robust in the case of sparse optical data that are common in highly cloudy regions.
Multilevel Stochastic Optimization for Imputation in Massive Medical Data Records
Oct 19, 2021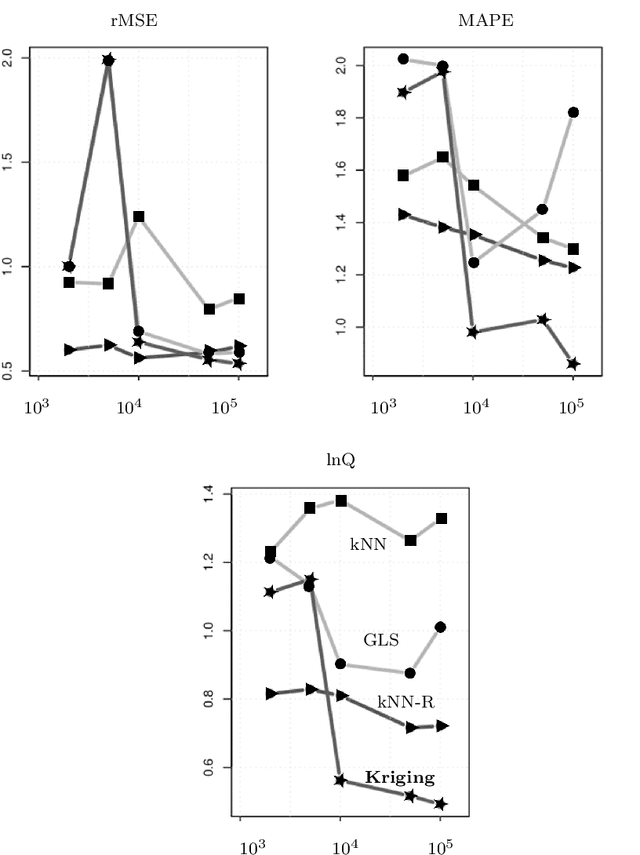
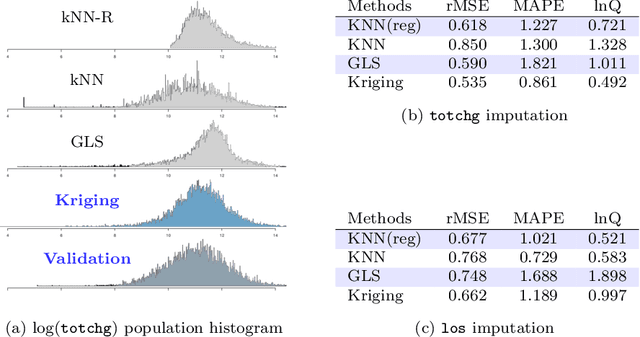
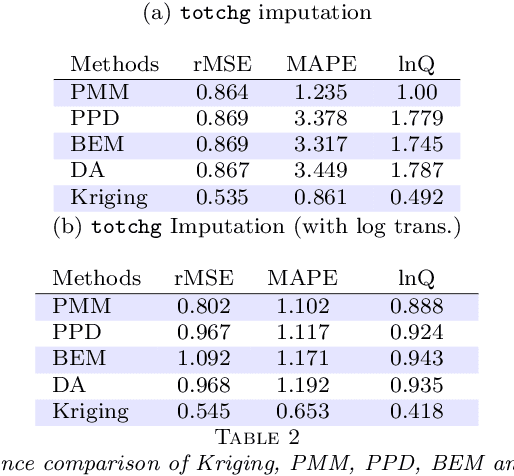
Exploration and analysis of massive datasets has recently generated increasing interest in the research and development communities. It has long been a recognized problem that many datasets contain significant levels of missing numerical data. We introduce a mathematically principled stochastic optimization imputation method based on the theory of Kriging. This is shown to be a powerful method for imputation. However, its computational effort and potential numerical instabilities produce costly and/or unreliable predictions, potentially limiting its use on large scale datasets. In this paper, we apply a recently developed multi-level stochastic optimization approach to the problem of imputation in massive medical records. The approach is based on computational applied mathematics techniques and is highly accurate. In particular, for the Best Linear Unbiased Predictor (BLUP) this multi-level formulation is exact, and is also significantly faster and more numerically stable. This permits practical application of Kriging methods to data imputation problems for massive datasets. We test this approach on data from the National Inpatient Sample (NIS) data records, Healthcare Cost and Utilization Project (HCUP), Agency for Healthcare Research and Quality. Numerical results show the multi-level method significantly outperforms current approaches and is numerically robust. In particular, it has superior accuracy as compared with methods recommended in the recent report from HCUP on the important problem of missing data, which could lead to sub-optimal and poorly based funding policy decisions. In comparative benchmark tests it is shown that the multilevel stochastic method is significantly superior to recommended methods in the report, including Predictive Mean Matching (PMM) and Predicted Posterior Distribution (PPD), with up to 75% reductions in error.
Stochastic functional analysis with applications to robust machine learning
Oct 04, 2021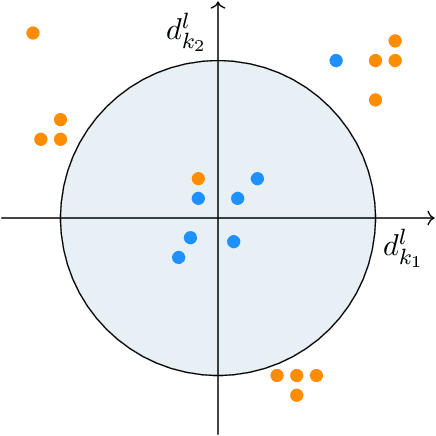
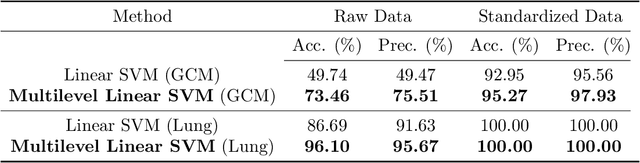
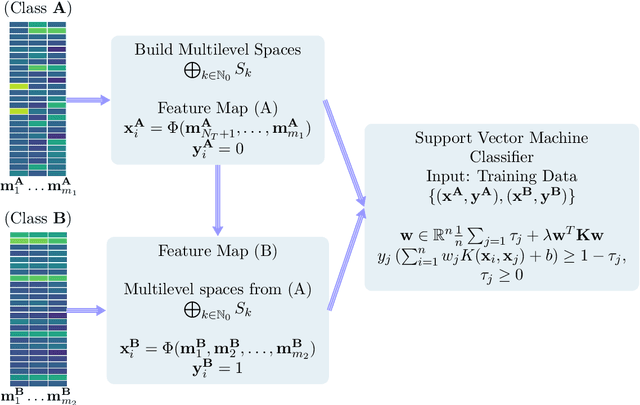
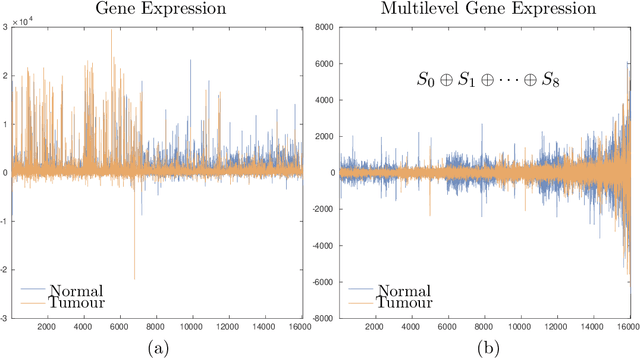
It is well-known that machine learning protocols typically under-utilize information on the probability distributions of feature vectors and related data, and instead directly compute regression or classification functions of feature vectors. In this paper we introduce a set of novel features for identifying underlying stochastic behavior of input data using the Karhunen-Lo\'{e}ve (KL) expansion, where classification is treated as detection of anomalies from a (nominal) signal class. These features are constructed from the recent Functional Data Analysis (FDA) theory for anomaly detection. The related signal decomposition is an exact hierarchical tensor product expansion with known optimality properties for approximating stochastic processes (random fields) with finite dimensional function spaces. In principle these primary low dimensional spaces can capture most of the stochastic behavior of `underlying signals' in a given nominal class, and can reject signals in alternative classes as stochastic anomalies. Using a hierarchical finite dimensional KL expansion of the nominal class, a series of orthogonal nested subspaces is constructed for detecting anomalous signal components. Projection coefficients of input data in these subspaces are then used to train an ML classifier. However, due to the split of the signal into nominal and anomalous projection components, clearer separation surfaces of the classes arise. In fact we show that with a sufficiently accurate estimation of the covariance structure of the nominal class, a sharp classification can be obtained. We carefully formulate this concept and demonstrate it on a number of high-dimensional datasets in cancer diagnostics. This method leads to a significant increase in precision and accuracy over the current top benchmarks for the Global Cancer Map (GCM) gene expression network dataset.