 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSA-OOSC: A Multimodal LLM-Distilled Semantic Communication Framework for Enhanced Coding Efficiency with Scenario Understanding
Sep 09, 2025



This paper introduces SA-OOSC, a multimodal large language models (MLLM)-distilled semantic communication framework that achieves efficient semantic coding with scenario-aware importance allocations. This approach addresses a critical limitation of existing object-oriented semantic communication (OOSC) systems - assigning static importance values to specific classes of objects regardless of their contextual relevance. Our framework utilizes MLLMs to identify the scenario-augmented (SA) semantic importance for objects within the image. Through knowledge distillation with the MLLM-annotated data, our vectorization/de-vectorization networks and JSCC encoder/decoder learn to dynamically allocate coding resources based on contextual significance, i.e., distinguishing between high-importance objects and low-importance according to the SA scenario information of the task. The framework features three core innovations: a MLLM-guided knowledge distillation pipeline, an importance-weighted variable-length JSCC framework, and novel loss function designs that facilitate the knowledge distillation within the JSCC framework. Experimental validation demonstrates our framework's superior coding efficiency over conventional semantic communication systems, with open-sourced MLLM-annotated and human-verified datasets established as new benchmarks for future research in semantic communications.
UMRE: A Unified Monotonic Transformation for Ranking Ensemble in Recommender Systems
Aug 11, 2025Industrial recommender systems commonly rely on ensemble sorting (ES) to combine predictions from multiple behavioral objectives. Traditionally, this process depends on manually designed nonlinear transformations (e.g., polynomial or exponential functions) and hand-tuned fusion weights to balance competing goals -- an approach that is labor-intensive and frequently suboptimal in achieving Pareto efficiency. In this paper, we propose a novel Unified Monotonic Ranking Ensemble (UMRE) framework to address the limitations of traditional methods in ensemble sorting. UMRE replaces handcrafted transformations with Unconstrained Monotonic Neural Networks (UMNN), which learn expressive, strictly monotonic functions through the integration of positive neural integrals. Subsequently, a lightweight ranking model is employed to fuse the prediction scores, assigning personalized weights to each prediction objective. To balance competing goals, we further introduce a Pareto optimality strategy that adaptively coordinates task weights during training. UMRE eliminates manual tuning, maintains ranking consistency, and achieves fine-grained personalization. Experimental results on two public recommendation datasets (Kuairand and Tenrec) and online A/B tests demonstrate impressive performance and generalization capabilities.
Dream4D: Lifting Camera-Controlled I2V towards Spatiotemporally Consistent 4D Generation
Aug 11, 2025The synthesis of spatiotemporally coherent 4D content presents fundamental challenges in computer vision, requiring simultaneous modeling of high-fidelity spatial representations and physically plausible temporal dynamics. Current approaches often struggle to maintain view consistency while handling complex scene dynamics, particularly in large-scale environments with multiple interacting elements. This work introduces Dream4D, a novel framework that bridges this gap through a synergy of controllable video generation and neural 4D reconstruction. Our approach seamlessly combines a two-stage architecture: it first predicts optimal camera trajectories from a single image using few-shot learning, then generates geometrically consistent multi-view sequences via a specialized pose-conditioned diffusion process, which are finally converted into a persistent 4D representation. This framework is the first to leverage both rich temporal priors from video diffusion models and geometric awareness of the reconstruction models, which significantly facilitates 4D generation and shows higher quality (e.g., mPSNR, mSSIM) over existing methods.
An Underwater, Fault-Tolerant, Laser-Aided Robotic Multi-Modal Dense SLAM System for Continuous Underwater In-Situ Observation
Apr 30, 2025Existing underwater SLAM systems are difficult to work effectively in texture-sparse and geometrically degraded underwater environments, resulting in intermittent tracking and sparse mapping. Therefore, we present Water-DSLAM, a novel laser-aided multi-sensor fusion system that can achieve uninterrupted, fault-tolerant dense SLAM capable of continuous in-situ observation in diverse complex underwater scenarios through three key innovations: Firstly, we develop Water-Scanner, a multi-sensor fusion robotic platform featuring a self-designed Underwater Binocular Structured Light (UBSL) module that enables high-precision 3D perception. Secondly, we propose a fault-tolerant triple-subsystem architecture combining: 1) DP-INS (DVL- and Pressure-aided Inertial Navigation System): fusing inertial measurement unit, doppler velocity log, and pressure sensor based Error-State Kalman Filter (ESKF) to provide high-frequency absolute odometry 2) Water-UBSL: a novel Iterated ESKF (IESKF)-based tight coupling between UBSL and DP-INS to mitigate UBSL's degeneration issues 3) Water-Stereo: a fusion of DP-INS and stereo camera for accurate initialization and tracking. Thirdly, we introduce a multi-modal factor graph back-end that dynamically fuses heterogeneous sensor data. The proposed multi-sensor factor graph maintenance strategy efficiently addresses issues caused by asynchronous sensor frequencies and partial data loss. Experimental results demonstrate Water-DSLAM achieves superior robustness (0.039 m trajectory RMSE and 100\% continuity ratio during partial sensor dropout) and dense mapping (6922.4 points/m^3 in 750 m^3 water volume, approximately 10 times denser than existing methods) in various challenging environments, including pools, dark underwater scenes, 16-meter-deep sinkholes, and field rivers. Our project is available at https://water-scanner.github.io/.
Out-of-Distribution Detection in Heterogeneous Graphs via Energy Propagation
Apr 29, 2025



Graph neural networks (GNNs) are proven effective in extracting complex node and structural information from graph data. While current GNNs perform well in node classification tasks within in-distribution (ID) settings, real-world scenarios often present distribution shifts, leading to the presence of out-of-distribution (OOD) nodes. OOD detection in graphs is a crucial and challenging task. Most existing research focuses on homogeneous graphs, but real-world graphs are often heterogeneous, consisting of diverse node and edge types. This heterogeneity adds complexity and enriches the informational content. To the best of our knowledge, OOD detection in heterogeneous graphs remains an underexplored area. In this context, we propose a novel methodology for OOD detection in heterogeneous graphs (OODHG) that aims to achieve two main objectives: 1) detecting OOD nodes and 2) classifying all ID nodes based on the first task's results. Specifically, we learn representations for each node in the heterogeneous graph, calculate energy values to determine whether nodes are OOD, and then classify ID nodes. To leverage the structural information of heterogeneous graphs, we introduce a meta-path-based energy propagation mechanism and an energy constraint to enhance the distinction between ID and OOD nodes. Extensive experimental findings substantiate the simplicity and effectiveness of OODHG, demonstrating its superiority over baseline models in OOD detection tasks and its accuracy in ID node classification.
Research on an Autonomous UAV Search and Rescue System Based on the Improved
Jun 01, 2024The demand is to solve the issue of UAV (unmanned aerial vehicle) operating autonomously and implementing practical functions such as search and rescue in complex unknown environments. This paper proposes an autonomous search and rescue UAV system based on an EGO-Planner algorithm, which is improved by innovative UAV body application and takes the methods of inverse motor backstepping to enhance the overall flight efficiency of the UAV and miniaturization of the whole machine. At the same time, the system introduced the EGO-Planner planning tool, which is optimized by a bidirectional A* algorithm along with an object detection algorithm. It solves the issue of intelligent obstacle avoidance and search and rescue. Through the simulation and field verification work, and compared with traditional algorithms, this method shows more efficiency and reliability in the task. In addition, due to the existing algorithm's improved robustness, this application shows good prospection.
Soft Masked Transformer for Point Cloud Processing with Skip Attention-Based Upsampling
Mar 21, 2024



Point cloud processing methods leverage local and global point features %at the feature level to cater to downstream tasks, yet they often overlook the task-level context inherent in point clouds during the encoding stage. We argue that integrating task-level information into the encoding stage significantly enhances performance. To that end, we propose SMTransformer which incorporates task-level information into a vector-based transformer by utilizing a soft mask generated from task-level queries and keys to learn the attention weights. Additionally, to facilitate effective communication between features from the encoding and decoding layers in high-level tasks such as segmentation, we introduce a skip-attention-based up-sampling block. This block dynamically fuses features from various resolution points across the encoding and decoding layers. To mitigate the increase in network parameters and training time resulting from the complexity of the aforementioned blocks, we propose a novel shared position encoding strategy. This strategy allows various transformer blocks to share the same position information over the same resolution points, thereby reducing network parameters and training time without compromising accuracy.Experimental comparisons with existing methods on multiple datasets demonstrate the efficacy of SMTransformer and skip-attention-based up-sampling for point cloud processing tasks, including semantic segmentation and classification. In particular, we achieve state-of-the-art semantic segmentation results of 73.4% mIoU on S3DIS Area 5 and 62.4% mIoU on SWAN dataset
Sentence Bag Graph Formulation for Biomedical Distant Supervision Relation Extraction
Oct 29, 2023



We introduce a novel graph-based framework for alleviating key challenges in distantly-supervised relation extraction and demonstrate its effectiveness in the challenging and important domain of biomedical data. Specifically, we propose a graph view of sentence bags referring to an entity pair, which enables message-passing based aggregation of information related to the entity pair over the sentence bag. The proposed framework alleviates the common problem of noisy labeling in distantly supervised relation extraction and also effectively incorporates inter-dependencies between sentences within a bag. Extensive experiments on two large-scale biomedical relation datasets and the widely utilized NYT dataset demonstrate that our proposed framework significantly outperforms the state-of-the-art methods for biomedical distant supervision relation extraction while also providing excellent performance for relation extraction in the general text mining domain.
Full Point Encoding for Local Feature Aggregation in 3D Point Clouds
Mar 08, 2023



Point cloud processing methods exploit local point features and global context through aggregation which does not explicity model the internal correlations between local and global features. To address this problem, we propose full point encoding which is applicable to convolution and transformer architectures. Specifically, we propose Full Point Convolution (FPConv) and Full Point Transformer (FPTransformer) architectures. The key idea is to adaptively learn the weights from local and global geometric connections, where the connections are established through local and global correlation functions respectively. FPConv and FPTransformer simultaneously model the local and global geometric relationships as well as their internal correlations, demonstrating strong generalization ability and high performance. FPConv is incorporated in classical hierarchical network architectures to achieve local and global shape-aware learning. In FPTransformer, we introduce full point position encoding in self-attention, that hierarchically encodes each point position in the global and local receptive field. We also propose a shape aware downsampling block which takes into account the local shape and the global context. Experimental comparison to existing methods on benchmark datasets show the efficacy of FPConv and FPTransformer for semantic segmentation, object detection, classification, and normal estimation tasks. In particular, we achieve state-of-the-art semantic segmentation results of 76% mIoU on S3DIS 6-fold and 72.2% on S3DIS Area5.
Enhanced Decentralized Federated Learning based on Consensus in Connected Vehicles
Sep 22, 2022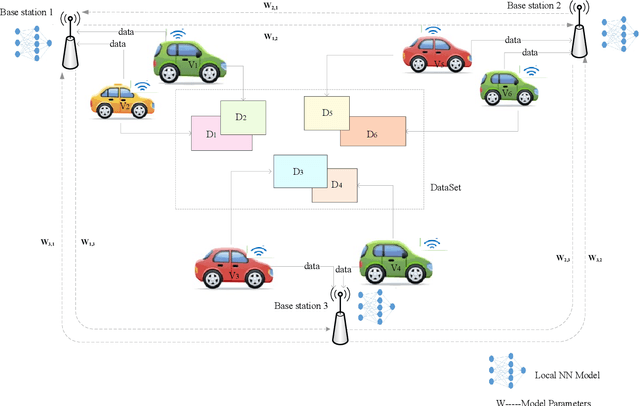

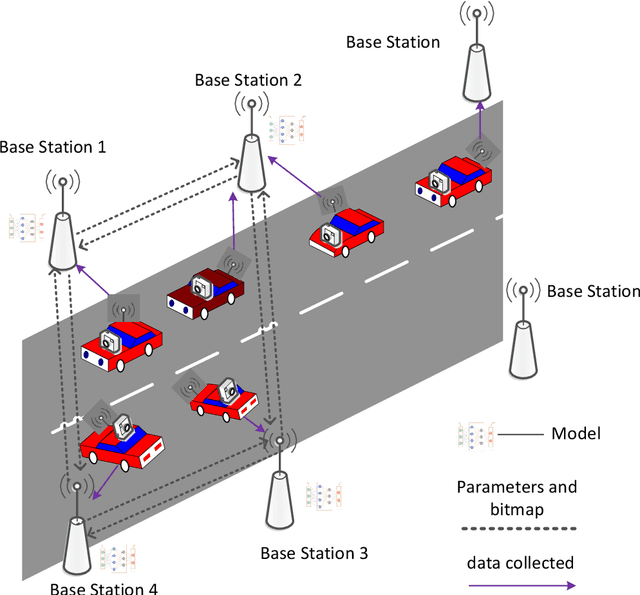
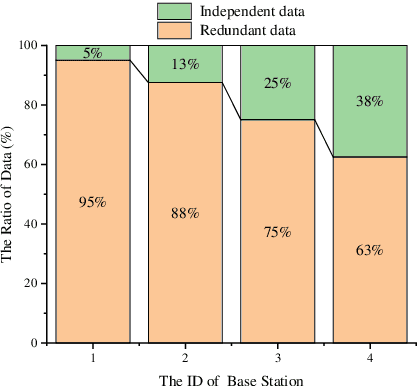
Advanced researches on connected vehicles have recently targeted to the integration of vehicle-to-everything (V2X) networks with Machine Learning (ML) tools and distributed decision making. Federated learning (FL) is emerging as a new paradigm to train machine learning (ML) models in distributed systems, including vehicles in V2X networks. Rather than sharing and uploading the training data to the server, the updating of model parameters (e.g., neural networks' weights and biases) is applied by large populations of interconnected vehicles, acting as local learners. Despite these benefits, the limitation of existing approaches is the centralized optimization which relies on a server for aggregation and fusion of local parameters, leading to the drawback of a single point of failure and scaling issues for increasing V2X network size. Meanwhile, in intelligent transport scenarios, data collected from onboard sensors are redundant, which degrades the performance of aggregation. To tackle these problems, we explore a novel idea of decentralized data processing and introduce a federated learning framework for in-network vehicles, C-DFL(Consensus based Decentralized Federated Learning), to tackle federated learning on connected vehicles and improve learning quality. Extensive simulations have been implemented to evaluate the performance of C-DFL, that demonstrates C-DFL outperforms the performance of conventional methods in all cases.