 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTracing the Roots: A Multi-Agent Framework for Uncovering Data Lineage in Post-Training LLMs
Apr 12, 2026Post-training data plays a pivotal role in shaping the capabilities of Large Language Models (LLMs), yet datasets are often treated as isolated artifacts, overlooking the systemic connections that underlie their evolution. To disentangle these complex relationships, we introduce the concept of \textbf{data lineage} to the LLM ecosystem and propose an automated multi-agent framework to reconstruct the evolutionary graph of dataset development. Through large-scale lineage analysis, we characterize domain-specific structural patterns, such as vertical refinement in math-oriented datasets and horizontal aggregation in general-domain corpora. Moreover, we uncover pervasive systemic issues, including \textit{structural redundancy} induced by implicit dataset intersections and the \textit{propagation of benchmark contamination} along lineage paths. To demonstrate the practical value of lineage analysis for data construction, we leverage the reconstructed lineage graph to create a \textit{lineage-aware diversity-oriented dataset}. By anchoring instruction sampling at upstream root sources, this approach mitigates downstream homogenization and hidden redundancy, yielding a more diverse post-training corpus. We further highlight lineage-centric analysis as an efficient and robust topological alternative to sample-level dataset comparison for large-scale data ecosystems. By grounding data construction in explicit lineage structures, our work advances post-training data curation toward a more systematic and controllable paradigm.
Bidirectional Curriculum Generation: A Multi-Agent Framework for Data-Efficient Mathematical Reasoning
Mar 05, 2026Enhancing mathematical reasoning in Large Language Models typically demands massive datasets, yet data efficiency remains a critical bottleneck. While Curriculum Learning attempts to structure this process, standard unidirectional approaches (simple-to-complex) suffer from inefficient sample utilization: they blindly escalate complexity even when foundational gaps persist, leading to wasted computation on unsolvable problems. To maximize the instructional value of every training sample, we introduce a novel Bidirectional Curriculum Generation framework. Unlike rigid trajectories, our multi-agent ecosystem mimics adaptive pedagogy to establish a closed feedback loop. It dynamically generates data by either complicating problems to challenge the model or, crucially, simplying them to repair specific reasoning failures. This mechanism ensures that the model consumes only the most effective data at any given stage. Grounded in the Optimal Pacing Theorem, our approach optimizes the learning trajectory, significantly outperforming baselines while achieving superior reasoning performance with substantially fewer instruction samples.
GeoNorm: Unify Pre-Norm and Post-Norm with Geodesic Optimization
Jan 29, 2026The placement of normalization layers, specifically Pre-Norm and Post-Norm, remains an open question in Transformer architecture design. In this work, we rethink these approaches through the lens of manifold optimization, interpreting the outputs of the Feed-Forward Network (FFN) and attention layers as update directions in optimization. Building on this perspective, we introduce GeoNorm, a novel method that replaces standard normalization with geodesic updates on the manifold. Furthermore, analogous to learning rate schedules, we propose a layer-wise update decay for the FFN and attention components. Comprehensive experiments demonstrate that GeoNorm consistently outperforms existing normalization methods in Transformer models. Crucially, GeoNorm can be seamlessly integrated into standard Transformer architectures, achieving performance improvements with negligible additional computational cost.
MMFineReason: Closing the Multimodal Reasoning Gap via Open Data-Centric Methods
Jan 29, 2026Recent advances in Vision Language Models (VLMs) have driven significant progress in visual reasoning. However, open-source VLMs still lag behind proprietary systems, largely due to the lack of high-quality reasoning data. Existing datasets offer limited coverage of challenging domains such as STEM diagrams and visual puzzles, and lack consistent, long-form Chain-of-Thought (CoT) annotations essential for eliciting strong reasoning capabilities. To bridge this gap, we introduce MMFineReason, a large-scale multimodal reasoning dataset comprising 1.8M samples and 5.1B solution tokens, featuring high-quality reasoning annotations distilled from Qwen3-VL-235B-A22B-Thinking. The dataset is established via a systematic three-stage pipeline: (1) large-scale data collection and standardization, (2) CoT rationale generation, and (3) comprehensive selection based on reasoning quality and difficulty awareness. The resulting dataset spans STEM problems, visual puzzles, games, and complex diagrams, with each sample annotated with visually grounded reasoning traces. We fine-tune Qwen3-VL-Instruct on MMFineReason to develop MMFineReason-2B/4B/8B versions. Our models establish new state-of-the-art results for their size class. Notably, MMFineReason-4B succesfully surpasses Qwen3-VL-8B-Thinking, and MMFineReason-8B even outperforms Qwen3-VL-30B-A3B-Thinking while approaching Qwen3-VL-32B-Thinking, demonstrating remarkable parameter efficiency. Crucially, we uncover a "less is more" phenomenon via our difficulty-aware filtering strategy: a subset of just 7\% (123K samples) achieves performance comparable to the full dataset. Notably, we reveal a synergistic effect where reasoning-oriented data composition simultaneously boosts general capabilities.
ChartVerse: Scaling Chart Reasoning via Reliable Programmatic Synthesis from Scratch
Jan 20, 2026Chart reasoning is a critical capability for Vision Language Models (VLMs). However, the development of open-source models is severely hindered by the lack of high-quality training data. Existing datasets suffer from a dual challenge: synthetic charts are often simplistic and repetitive, while the associated QA pairs are prone to hallucinations and lack the reasoning depth required for complex tasks. To bridge this gap, we propose ChartVerse, a scalable framework designed to synthesize complex charts and reliable reasoning data from scratch. (1) To address the bottleneck of simple patterns, we first introduce Rollout Posterior Entropy (RPE), a novel metric that quantifies chart complexity. Guided by RPE, we develop complexity-aware chart coder to autonomously synthesize diverse, high-complexity charts via executable programs. (2) To guarantee reasoning rigor, we develop truth-anchored inverse QA synthesis. Diverging from standard generation, we adopt an answer-first paradigm: we extract deterministic answers directly from the source code, generate questions conditional on these anchors, and enforce strict consistency verification. To further elevate difficulty and reasoning depth, we filter samples based on model fail-rate and distill high-quality Chain-of-Thought (CoT) reasoning. We curate ChartVerse-SFT-600K and ChartVerse-RL-40K using Qwen3-VL-30B-A3B-Thinking as the teacher. Experimental results demonstrate that ChartVerse-8B achieves state-of-the-art performance, notably surpassing its teacher and rivaling the stronger Qwen3-VL-32B-Thinking.
OpenDataArena: A Fair and Open Arena for Benchmarking Post-Training Dataset Value
Dec 16, 2025



The rapid evolution of Large Language Models (LLMs) is predicated on the quality and diversity of post-training datasets. However, a critical dichotomy persists: while models are rigorously benchmarked, the data fueling them remains a black box--characterized by opaque composition, uncertain provenance, and a lack of systematic evaluation. This opacity hinders reproducibility and obscures the causal link between data characteristics and model behaviors. To bridge this gap, we introduce OpenDataArena (ODA), a holistic and open platform designed to benchmark the intrinsic value of post-training data. ODA establishes a comprehensive ecosystem comprising four key pillars: (i) a unified training-evaluation pipeline that ensures fair, open comparisons across diverse models (e.g., Llama, Qwen) and domains; (ii) a multi-dimensional scoring framework that profiles data quality along tens of distinct axes; (iii) an interactive data lineage explorer to visualize dataset genealogy and dissect component sources; and (iv) a fully open-source toolkit for training, evaluation, and scoring to foster data research. Extensive experiments on ODA--covering over 120 training datasets across multiple domains on 22 benchmarks, validated by more than 600 training runs and 40 million processed data points--reveal non-trivial insights. Our analysis uncovers the inherent trade-offs between data complexity and task performance, identifies redundancy in popular benchmarks through lineage tracing, and maps the genealogical relationships across datasets. We release all results, tools, and configurations to democratize access to high-quality data evaluation. Rather than merely expanding a leaderboard, ODA envisions a shift from trial-and-error data curation to a principled science of Data-Centric AI, paving the way for rigorous studies on data mixing laws and the strategic composition of foundation models.
SQL-o1: A Self-Reward Heuristic Dynamic Search Method for Text-to-SQL
Feb 17, 2025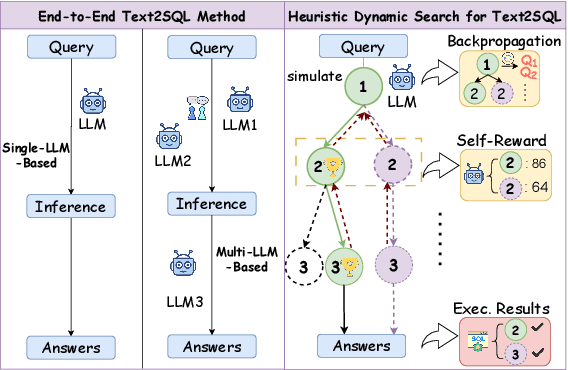
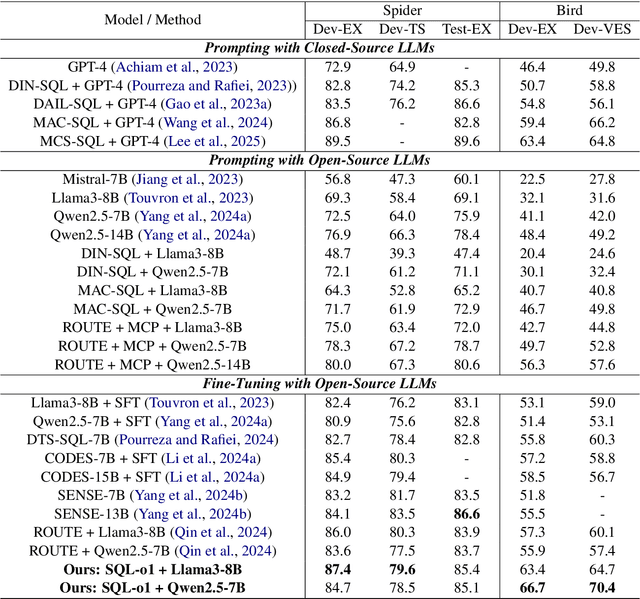
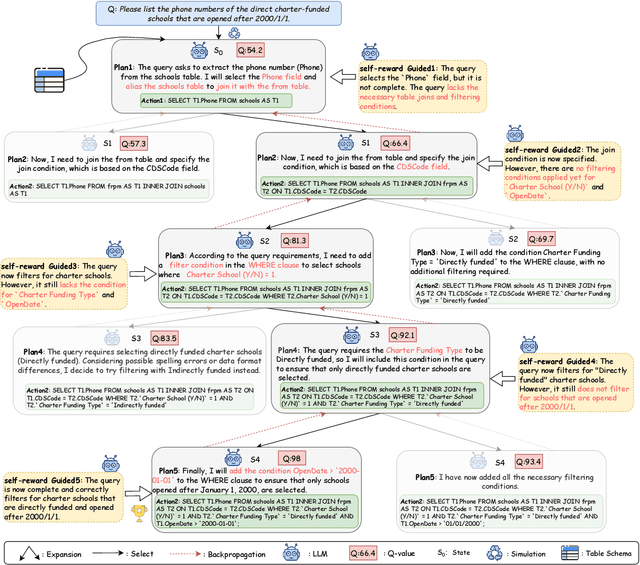
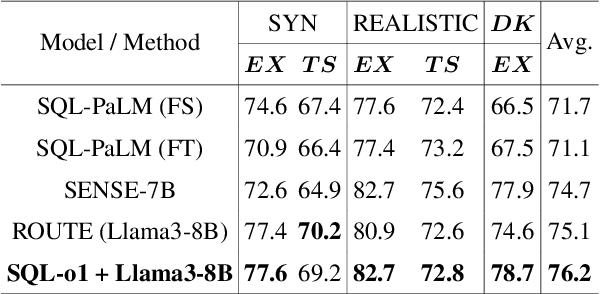
The Text-to-SQL(Text2SQL) task aims to convert natural language queries into executable SQL queries. Thanks to the application of large language models (LLMs), significant progress has been made in this field. However, challenges such as model scalability, limited generation space, and coherence issues in SQL generation still persist. To address these issues, we propose SQL-o1, a Self-Reward-based heuristic search method designed to enhance the reasoning ability of LLMs in SQL query generation. SQL-o1 combines Monte Carlo Tree Search (MCTS) for heuristic process-level search and constructs a Schema-Aware dataset to help the model better understand database schemas. Extensive experiments on the Bird and Spider datasets demonstrate that SQL-o1 improves execution accuracy by 10.8\% on the complex Bird dataset compared to the latest baseline methods, even outperforming GPT-4-based approaches. Additionally, SQL-o1 excels in few-shot learning scenarios and shows strong cross-model transferability. Our code is publicly available at:https://github.com/ShuaiLyu0110/SQL-o1.