 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeESRGAN: Enhanced Super-Resolution Generative Adversarial Networks
Sep 17, 2018
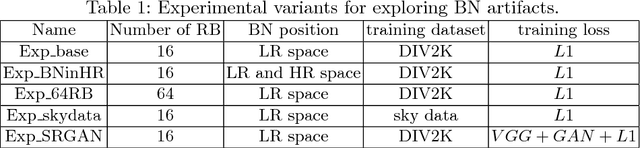

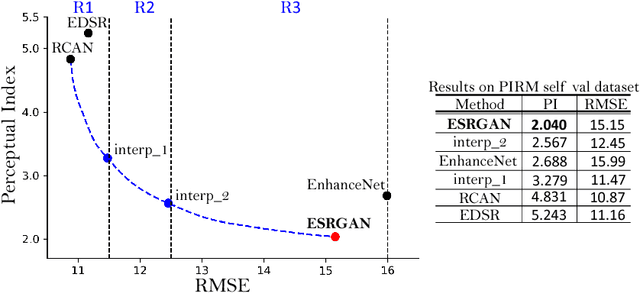
The Super-Resolution Generative Adversarial Network (SRGAN) is a seminal work that is capable of generating realistic textures during single image super-resolution. However, the hallucinated details are often accompanied with unpleasant artifacts. To further enhance the visual quality, we thoroughly study three key components of SRGAN - network architecture, adversarial loss and perceptual loss, and improve each of them to derive an Enhanced SRGAN (ESRGAN). In particular, we introduce the Residual-in-Residual Dense Block (RRDB) without batch normalization as the basic network building unit. Moreover, we borrow the idea from relativistic GAN to let the discriminator predict relative realness instead of the absolute value. Finally, we improve the perceptual loss by using the features before activation, which could provide stronger supervision for brightness consistency and texture recovery. Benefiting from these improvements, the proposed ESRGAN achieves consistently better visual quality with more realistic and natural textures than SRGAN and won the first place in the PIRM2018-SR Challenge. The code is available at https://github.com/xinntao/ESRGAN .
Improving On-policy Learning with Statistical Reward Accumulation
Sep 07, 2018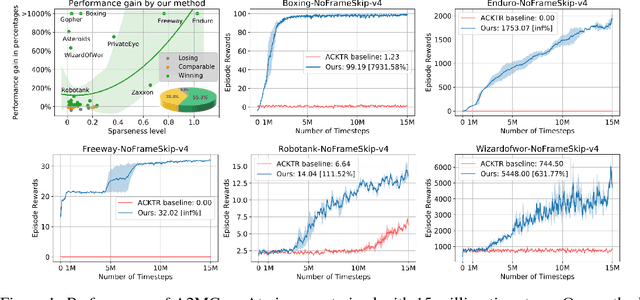
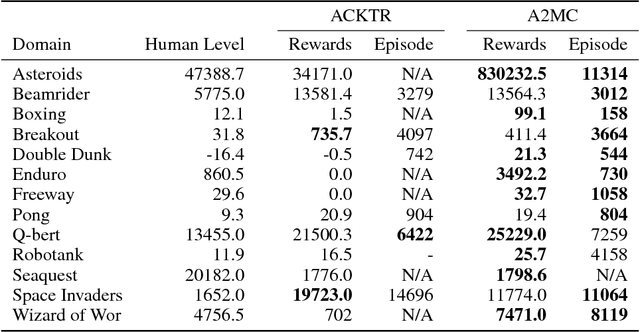
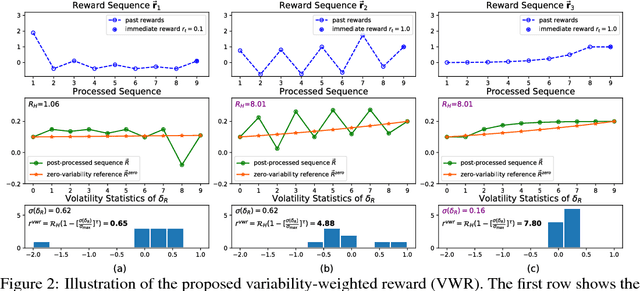
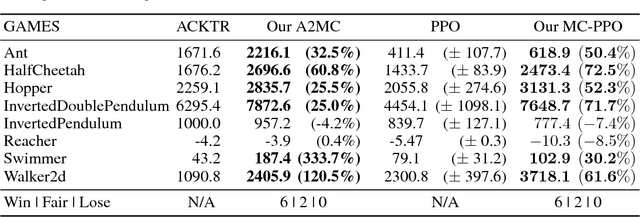
Deep reinforcement learning has obtained significant breakthroughs in recent years. Most methods in deep-RL achieve good results via the maximization of the reward signal provided by the environment, typically in the form of discounted cumulative returns. Such reward signals represent the immediate feedback of a particular action performed by an agent. However, tasks with sparse reward signals are still challenging to on-policy methods. In this paper, we introduce an effective characterization of past reward statistics (which can be seen as long-term feedback signals) to supplement this immediate reward feedback. In particular, value functions are learned with multi-critics supervision, enabling complex value functions to be more easily approximated in on-policy learning, even when the reward signals are sparse. We also introduce a novel exploration mechanism called "hot-wiring" that can give a boost to seemingly trapped agents. We demonstrate the effectiveness of our advantage actor multi-critic (A2MC) method across the discrete domains in Atari games as well as continuous domains in the MuJoCo environments. A video demo is provided at https://youtu.be/zBmpf3Yz8tc.
Two at Once: Enhancing Learning and Generalization Capacities via IBN-Net
Jul 27, 2018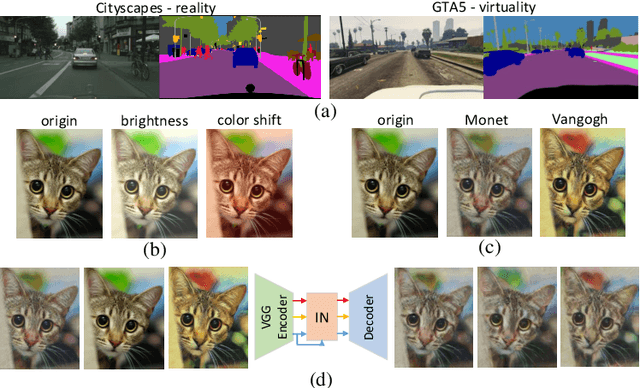
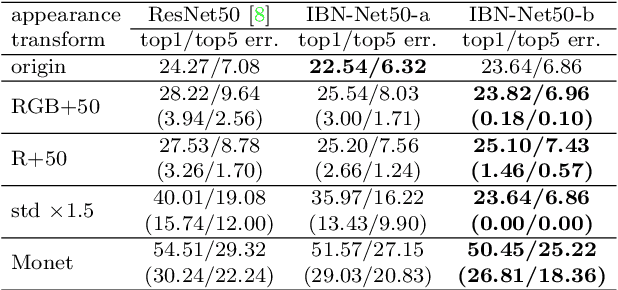
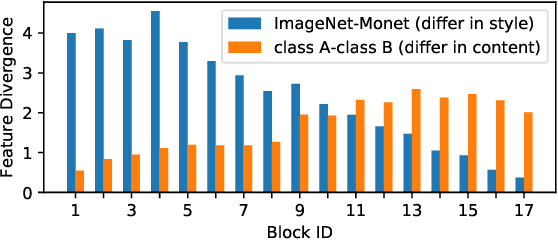

Convolutional neural networks (CNNs) have achieved great successes in many computer vision problems. Unlike existing works that designed CNN architectures to improve performance on a single task of a single domain and not generalizable, we present IBN-Net, a novel convolutional architecture, which remarkably enhances a CNN's modeling ability on one domain (e.g. Cityscapes) as well as its generalization capacity on another domain (e.g. GTA5) without finetuning. IBN-Net carefully integrates Instance Normalization (IN) and Batch Normalization (BN) as building blocks, and can be wrapped into many advanced deep networks to improve their performances. This work has three key contributions. (1) By delving into IN and BN, we disclose that IN learns features that are invariant to appearance changes, such as colors, styles, and virtuality/reality, while BN is essential for preserving content related information. (2) IBN-Net can be applied to many advanced deep architectures, such as DenseNet, ResNet, ResNeXt, and SENet, and consistently improve their performance without increasing computational cost. (3) When applying the trained networks to new domains, e.g. from GTA5 to Cityscapes, IBN-Net achieves comparable improvements as domain adaptation methods, even without using data from the target domain. With IBN-Net, we won the 1st place on the WAD 2018 Challenge Drivable Area track, with an mIoU of 86.18%.
Aesthetic-Driven Image Enhancement by Adversarial Learning
Jul 02, 2018
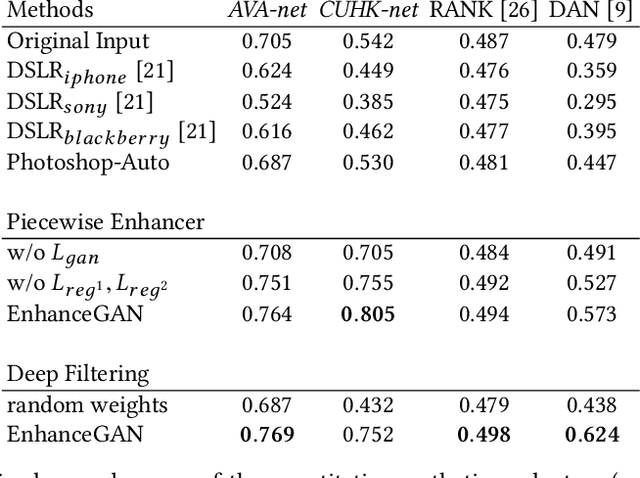
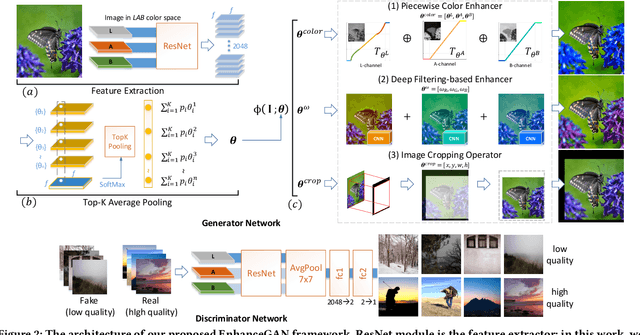
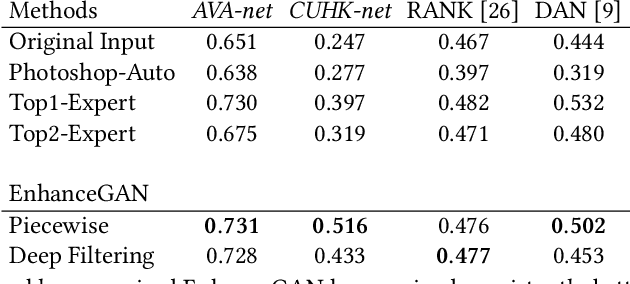
We introduce EnhanceGAN, an adversarial learning based model that performs automatic image enhancement. Traditional image enhancement frameworks typically involve training models in a fully-supervised manner, which require expensive annotations in the form of aligned image pairs. In contrast to these approaches, our proposed EnhanceGAN only requires weak supervision (binary labels on image aesthetic quality) and is able to learn enhancement operators for the task of aesthetic-based image enhancement. In particular, we show the effectiveness of a piecewise color enhancement module trained with weak supervision, and extend the proposed EnhanceGAN framework to learning a deep filtering-based aesthetic enhancer. The full differentiability of our image enhancement operators enables the training of EnhanceGAN in an end-to-end manner. We further demonstrate the capability of EnhanceGAN in learning aesthetic-based image cropping without any groundtruth cropping pairs. Our weakly-supervised EnhanceGAN reports competitive quantitative results on aesthetic-based color enhancement as well as automatic image cropping, and a user study confirms that our image enhancement results are on par with or even preferred over professional enhancement.
Deep Imbalanced Learning for Face Recognition and Attribute Prediction
Jun 01, 2018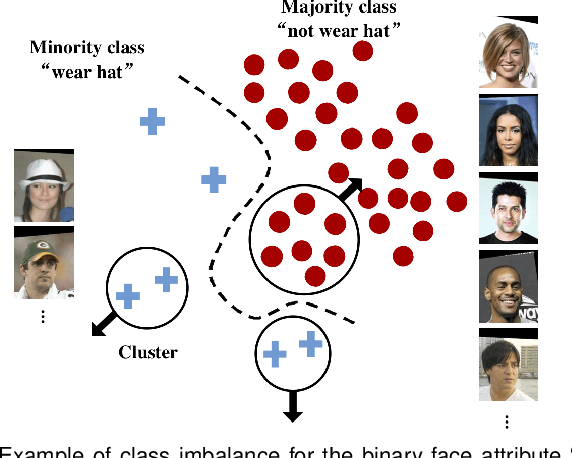

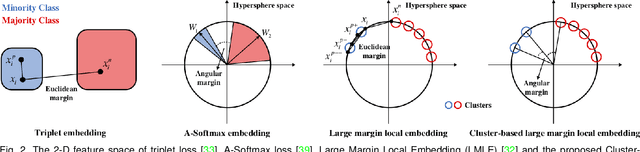
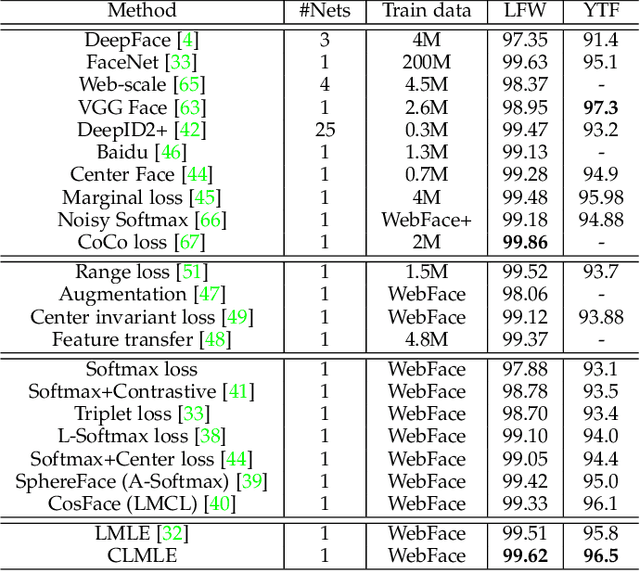
Data for face analysis often exhibit highly-skewed class distribution, i.e., most data belong to a few majority classes, while the minority classes only contain a scarce amount of instances. To mitigate this issue, contemporary deep learning methods typically follow classic strategies such as class re-sampling or cost-sensitive training. In this paper, we conduct extensive and systematic experiments to validate the effectiveness of these classic schemes for representation learning on class-imbalanced data. We further demonstrate that more discriminative deep representation can be learned by enforcing a deep network to maintain inter-cluster margins both within and between classes. This tight constraint effectively reduces the class imbalance inherent in the local data neighborhood, thus carving much more balanced class boundaries locally. We show that it is easy to deploy angular margins between the cluster distributions on a hypersphere manifold. Such learned Cluster-based Large Margin Local Embedding (CLMLE), when combined with a simple k-nearest cluster algorithm, shows significant improvements in accuracy over existing methods on both face recognition and face attribute prediction tasks that exhibit imbalanced class distribution.
LiteFlowNet: A Lightweight Convolutional Neural Network for Optical Flow Estimation
May 18, 2018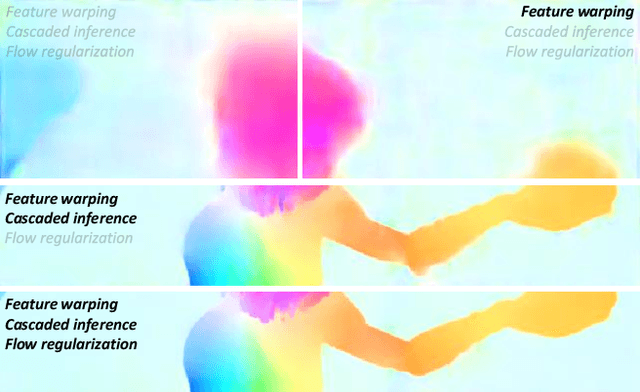
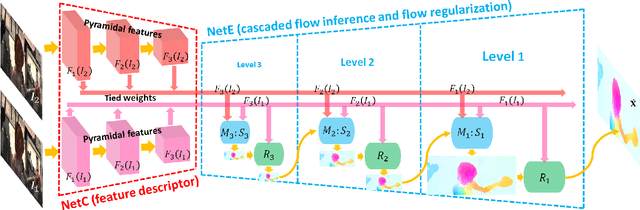
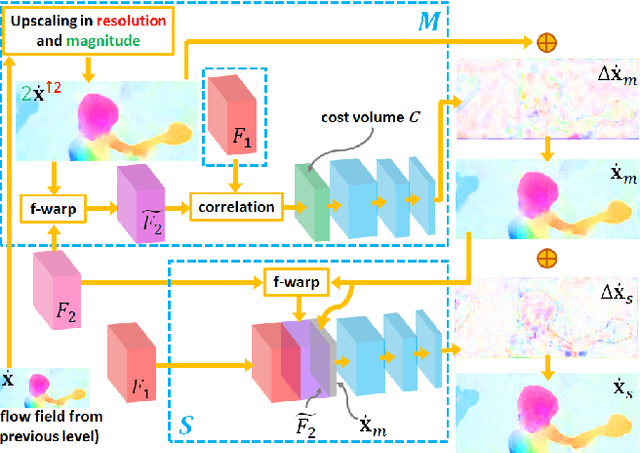
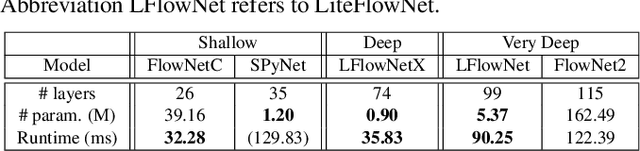
FlowNet2, the state-of-the-art convolutional neural network (CNN) for optical flow estimation, requires over 160M parameters to achieve accurate flow estimation. In this paper we present an alternative network that outperforms FlowNet2 on the challenging Sintel final pass and KITTI benchmarks, while being 30 times smaller in the model size and 1.36 times faster in the running speed. This is made possible by drilling down to architectural details that might have been missed in the current frameworks: (1) We present a more effective flow inference approach at each pyramid level through a lightweight cascaded network. It not only improves flow estimation accuracy through early correction, but also permits seamless incorporation of descriptor matching in our network. (2) We present a novel flow regularization layer to ameliorate the issue of outliers and vague flow boundaries by using a feature-driven local convolution. (3) Our network owns an effective structure for pyramidal feature extraction and embraces feature warping rather than image warping as practiced in FlowNet2. Our code and trained models are available at https://github.com/twhui/LiteFlowNet .
Pose-Robust Face Recognition via Deep Residual Equivariant Mapping
Mar 02, 2018

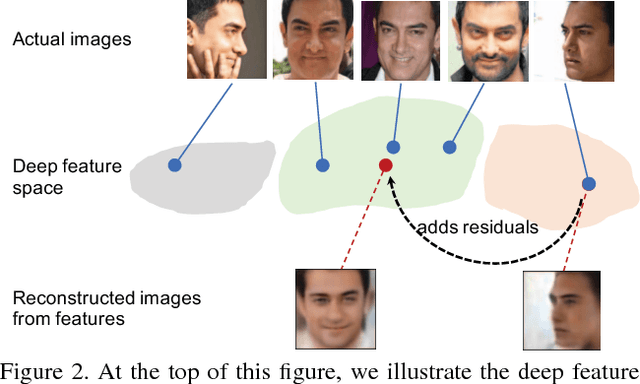

Face recognition achieves exceptional success thanks to the emergence of deep learning. However, many contemporary face recognition models still perform relatively poor in processing profile faces compared to frontal faces. A key reason is that the number of frontal and profile training faces are highly imbalanced - there are extensively more frontal training samples compared to profile ones. In addition, it is intrinsically hard to learn a deep representation that is geometrically invariant to large pose variations. In this study, we hypothesize that there is an inherent mapping between frontal and profile faces, and consequently, their discrepancy in the deep representation space can be bridged by an equivariant mapping. To exploit this mapping, we formulate a novel Deep Residual EquivAriant Mapping (DREAM) block, which is capable of adaptively adding residuals to the input deep representation to transform a profile face representation to a canonical pose that simplifies recognition. The DREAM block consistently enhances the performance of profile face recognition for many strong deep networks, including ResNet models, without deliberately augmenting training data of profile faces. The block is easy to use, light-weight, and can be implemented with a negligible computational overhead.
Recurrent Scale Approximation for Object Detection in CNN
Feb 08, 2018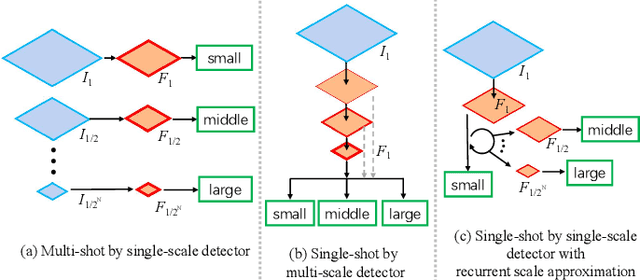

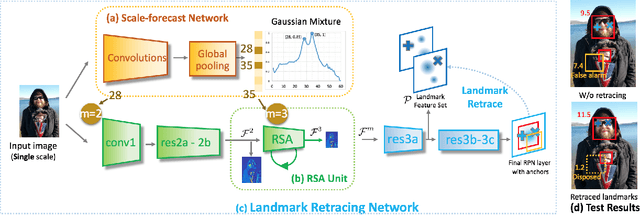
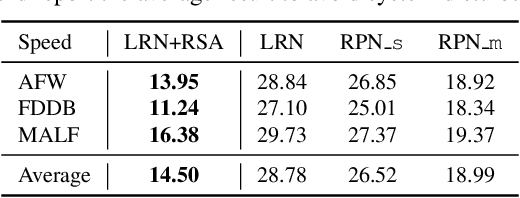
Since convolutional neural network (CNN) lacks an inherent mechanism to handle large scale variations, we always need to compute feature maps multiple times for multi-scale object detection, which has the bottleneck of computational cost in practice. To address this, we devise a recurrent scale approximation (RSA) to compute feature map once only, and only through this map can we approximate the rest maps on other levels. At the core of RSA is the recursive rolling out mechanism: given an initial map at a particular scale, it generates the prediction at a smaller scale that is half the size of input. To further increase efficiency and accuracy, we (a): design a scale-forecast network to globally predict potential scales in the image since there is no need to compute maps on all levels of the pyramid. (b): propose a landmark retracing network (LRN) to trace back locations of the regressed landmarks and generate a confidence score for each landmark; LRN can effectively alleviate false positives caused by the accumulated error in RSA. The whole system can be trained end-to-end in a unified CNN framework. Experiments demonstrate that our proposed algorithm is superior against state-of-the-art methods on face detection benchmarks and achieves comparable results for generic proposal generation. The source code of RSA is available at github.com/sciencefans/RSA-for-object-detection.
Mix-and-Match Tuning for Self-Supervised Semantic Segmentation
Jan 30, 2018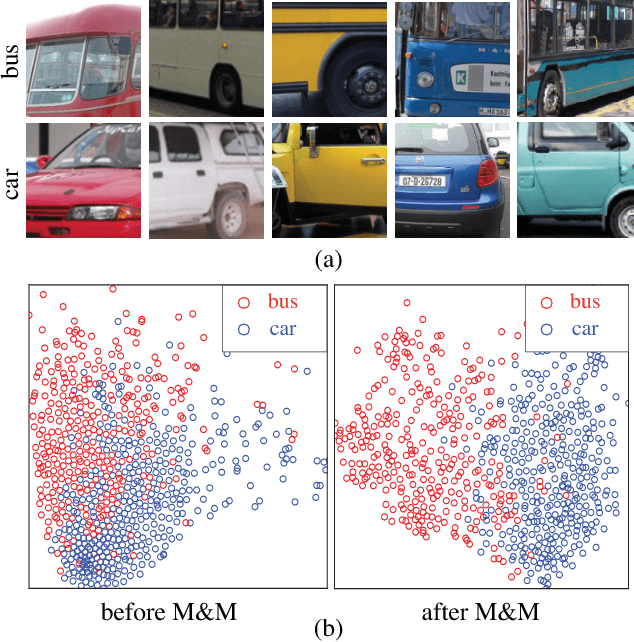
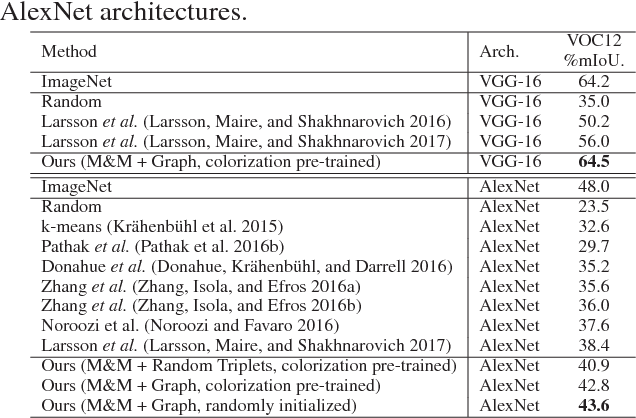
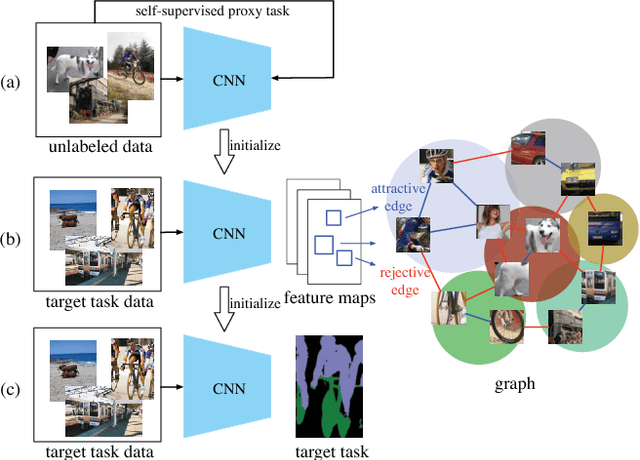
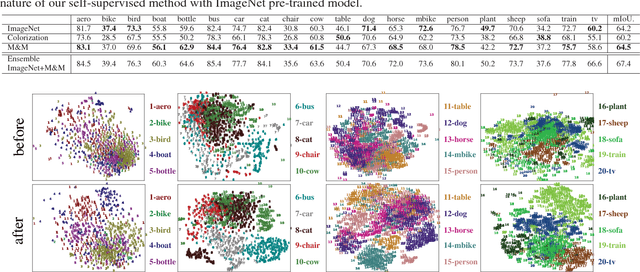
Deep convolutional networks for semantic image segmentation typically require large-scale labeled data, e.g. ImageNet and MS COCO, for network pre-training. To reduce annotation efforts, self-supervised semantic segmentation is recently proposed to pre-train a network without any human-provided labels. The key of this new form of learning is to design a proxy task (e.g. image colorization), from which a discriminative loss can be formulated on unlabeled data. Many proxy tasks, however, lack the critical supervision signals that could induce discriminative representation for the target image segmentation task. Thus self-supervision's performance is still far from that of supervised pre-training. In this study, we overcome this limitation by incorporating a "mix-and-match" (M&M) tuning stage in the self-supervision pipeline. The proposed approach is readily pluggable to many self-supervision methods and does not use more annotated samples than the original process. Yet, it is capable of boosting the performance of target image segmentation task to surpass fully-supervised pre-trained counterpart. The improvement is made possible by better harnessing the limited pixel-wise annotations in the target dataset. Specifically, we first introduce the "mix" stage, which sparsely samples and mixes patches from the target set to reflect rich and diverse local patch statistics of target images. A "match" stage then forms a class-wise connected graph, which can be used to derive a strong triplet-based discriminative loss for fine-tuning the network. Our paradigm follows the standard practice in existing self-supervised studies and no extra data or label is required. With the proposed M&M approach, for the first time, a self-supervision method can achieve comparable or even better performance compared to its ImageNet pre-trained counterpart on both PASCAL VOC2012 dataset and CityScapes dataset.
Spatial As Deep: Spatial CNN for Traffic Scene Understanding
Dec 17, 2017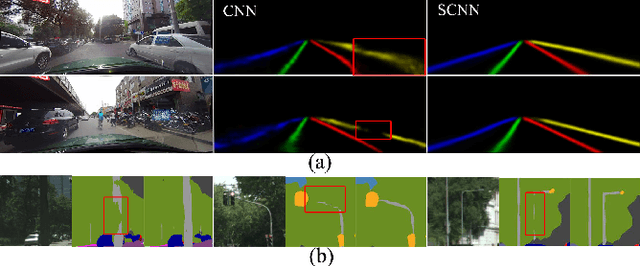


Convolutional neural networks (CNNs) are usually built by stacking convolutional operations layer-by-layer. Although CNN has shown strong capability to extract semantics from raw pixels, its capacity to capture spatial relationships of pixels across rows and columns of an image is not fully explored. These relationships are important to learn semantic objects with strong shape priors but weak appearance coherences, such as traffic lanes, which are often occluded or not even painted on the road surface as shown in Fig. 1 (a). In this paper, we propose Spatial CNN (SCNN), which generalizes traditional deep layer-by-layer convolutions to slice-byslice convolutions within feature maps, thus enabling message passings between pixels across rows and columns in a layer. Such SCNN is particular suitable for long continuous shape structure or large objects, with strong spatial relationship but less appearance clues, such as traffic lanes, poles, and wall. We apply SCNN on a newly released very challenging traffic lane detection dataset and Cityscapse dataset. The results show that SCNN could learn the spatial relationship for structure output and significantly improves the performance. We show that SCNN outperforms the recurrent neural network (RNN) based ReNet and MRF+CNN (MRFNet) in the lane detection dataset by 8.7% and 4.6% respectively. Moreover, our SCNN won the 1st place on the TuSimple Benchmark Lane Detection Challenge, with an accuracy of 96.53%.