 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA$^2$-LLM: An End-to-end Conversational Audio Avatar Large Language Model
Feb 04, 2026Developing expressive and responsive conversational digital humans is a cornerstone of next-generation human-computer interaction. While large language models (LLMs) have significantly enhanced dialogue capabilities, most current systems still rely on cascaded architectures that connect independent modules. These pipelines are often plagued by accumulated errors, high latency, and poor real-time performance. Lacking access to the underlying conversational context, these pipelines inherently prioritize rigid lip-sync over emotional depth. To address these challenges, we propose A$^2$-LLM, an end-to-end conversational audio avatar large language model that jointly reasons about language, audio prosody, and 3D facial motion within a unified framework. To facilitate training, we introduce FLAME-QA, a high-quality multimodal dataset designed to align semantic intent with expressive facial dynamics within a QA format. By leveraging deep semantic understanding, A$^2$-LLM generates emotionally rich facial movements beyond simple lip-synchronization. Experimental results demonstrate that our system achieves superior emotional expressiveness while maintaining real-time efficiency (500 ms latency, 0.7 RTF).
Beyond the Black Box: Theory and Mechanism of Large Language Models
Jan 06, 2026The rapid emergence of Large Language Models (LLMs) has precipitated a profound paradigm shift in Artificial Intelligence, delivering monumental engineering successes that increasingly impact modern society. However, a critical paradox persists within the current field: despite the empirical efficacy, our theoretical understanding of LLMs remains disproportionately nascent, forcing these systems to be treated largely as ``black boxes''. To address this theoretical fragmentation, this survey proposes a unified lifecycle-based taxonomy that organizes the research landscape into six distinct stages: Data Preparation, Model Preparation, Training, Alignment, Inference, and Evaluation. Within this framework, we provide a systematic review of the foundational theories and internal mechanisms driving LLM performance. Specifically, we analyze core theoretical issues such as the mathematical justification for data mixtures, the representational limits of various architectures, and the optimization dynamics of alignment algorithms. Moving beyond current best practices, we identify critical frontier challenges, including the theoretical limits of synthetic data self-improvement, the mathematical bounds of safety guarantees, and the mechanistic origins of emergent intelligence. By connecting empirical observations with rigorous scientific inquiry, this work provides a structured roadmap for transitioning LLM development from engineering heuristics toward a principled scientific discipline.
DeepInv: A Novel Self-supervised Learning Approach for Fast and Accurate Diffusion Inversion
Jan 04, 2026Diffusion inversion is a task of recovering the noise of an image in a diffusion model, which is vital for controllable diffusion image editing. At present, diffusion inversion still remains a challenging task due to the lack of viable supervision signals. Thus, most existing methods resort to approximation-based solutions, which however are often at the cost of performance or efficiency. To remedy these shortcomings, we propose a novel self-supervised diffusion inversion approach in this paper, termed Deep Inversion (DeepInv). Instead of requiring ground-truth noise annotations, we introduce a self-supervised objective as well as a data augmentation strategy to generate high-quality pseudo noises from real images without manual intervention. Based on these two innovative designs, DeepInv is also equipped with an iterative and multi-scale training regime to train a parameterized inversion solver, thereby achieving the fast and accurate image-to-noise mapping. To the best of our knowledge, this is the first attempt of presenting a trainable solver to predict inversion noise step by step. The extensive experiments show that our DeepInv can achieve much better performance and inference speed than the compared methods, e.g., +40.435% SSIM than EasyInv and +9887.5% speed than ReNoise on COCO dataset. Moreover, our careful designs of trainable solvers can also provide insights to the community. Codes and model parameters will be released in https://github.com/potato-kitty/DeepInv.
PartImageNet++ Dataset: Enhancing Visual Models with High-Quality Part Annotations
Jan 04, 2026To address the scarcity of high-quality part annotations in existing datasets, we introduce PartImageNet++ (PIN++), a dataset that provides detailed part annotations for all categories in ImageNet-1K. With 100 annotated images per category, totaling 100K images, PIN++ represents the most comprehensive dataset covering a diverse range of object categories. Leveraging PIN++, we propose a Multi-scale Part-supervised recognition Model (MPM) for robust classification on ImageNet-1K. We first trained a part segmentation network using PIN++ and used it to generate pseudo part labels for the remaining unannotated images. MPM then integrated a conventional recognition architecture with auxiliary bypass layers, jointly supervised by both pseudo part labels and the original part annotations. Furthermore, we conducted extensive experiments on PIN++, including part segmentation, object segmentation, and few-shot learning, exploring various ways to leverage part annotations in downstream tasks. Experimental results demonstrated that our approach not only enhanced part-based models for robust object recognition but also established strong baselines for multiple downstream tasks, highlighting the potential of part annotations in improving model performance. The dataset and the code are available at https://github.com/LixiaoTHU/PartImageNetPP.
FGNet: Leveraging Feature-Guided Attention to Refine SAM2 for 3D EM Neuron Segmentation
Nov 17, 2025Accurate segmentation of neural structures in Electron Microscopy (EM) images is paramount for neuroscience. However, this task is challenged by intricate morphologies, low signal-to-noise ratios, and scarce annotations, limiting the accuracy and generalization of existing methods. To address these challenges, we seek to leverage the priors learned by visual foundation models on a vast amount of natural images to better tackle this task. Specifically, we propose a novel framework that can effectively transfer knowledge from Segment Anything 2 (SAM2), which is pre-trained on natural images, to the EM domain. We first use SAM2 to extract powerful, general-purpose features. To bridge the domain gap, we introduce a Feature-Guided Attention module that leverages semantic cues from SAM2 to guide a lightweight encoder, the Fine-Grained Encoder (FGE), in focusing on these challenging regions. Finally, a dual-affinity decoder generates both coarse and refined affinity maps. Experimental results demonstrate that our method achieves performance comparable to state-of-the-art (SOTA) approaches with the SAM2 weights frozen. Upon further fine-tuning on EM data, our method significantly outperforms existing SOTA methods. This study validates that transferring representations pre-trained on natural images, when combined with targeted domain-adaptive guidance, can effectively address the specific challenges in neuron segmentation.
StepProof: Step-by-step verification of natural language mathematical proofs
Jun 12, 2025



Interactive theorem provers (ITPs) are powerful tools for the formal verification of mathematical proofs down to the axiom level. However, their lack of a natural language interface remains a significant limitation. Recent advancements in large language models (LLMs) have enhanced the understanding of natural language inputs, paving the way for autoformalization - the process of translating natural language proofs into formal proofs that can be verified. Despite these advancements, existing autoformalization approaches are limited to verifying complete proofs and lack the capability for finer, sentence-level verification. To address this gap, we propose StepProof, a novel autoformalization method designed for granular, step-by-step verification. StepProof breaks down complete proofs into multiple verifiable subproofs, enabling sentence-level verification. Experimental results demonstrate that StepProof significantly improves proof success rates and efficiency compared to traditional methods. Additionally, we found that minor manual adjustments to the natural language proofs, tailoring them for step-level verification, further enhanced StepProof's performance in autoformalization.
A Fast and Lightweight Model for Causal Audio-Visual Speech Separation
Jun 07, 2025Audio-visual speech separation (AVSS) aims to extract a target speech signal from a mixed signal by leveraging both auditory and visual (lip movement) cues. However, most existing AVSS methods exhibit complex architectures and rely on future context, operating offline, which renders them unsuitable for real-time applications. Inspired by the pipeline of RTFSNet, we propose a novel streaming AVSS model, named Swift-Net, which enhances the causal processing capabilities required for real-time applications. Swift-Net adopts a lightweight visual feature extraction module and an efficient fusion module for audio-visual integration. Additionally, Swift-Net employs Grouped SRUs to integrate historical information across different feature spaces, thereby improving the utilization efficiency of historical information. We further propose a causal transformation template to facilitate the conversion of non-causal AVSS models into causal counterparts. Experiments on three standard benchmark datasets (LRS2, LRS3, and VoxCeleb2) demonstrated that under causal conditions, our proposed Swift-Net exhibited outstanding performance, highlighting the potential of this method for processing speech in complex environments.
Surrogate Signals from Format and Length: Reinforcement Learning for Solving Mathematical Problems without Ground Truth Answers
May 26, 2025Large Language Models have achieved remarkable success in natural language processing tasks, with Reinforcement Learning playing a key role in adapting them to specific applications. However, obtaining ground truth answers for training LLMs in mathematical problem-solving is often challenging, costly, and sometimes unfeasible. This research delves into the utilization of format and length as surrogate signals to train LLMs for mathematical problem-solving, bypassing the need for traditional ground truth answers.Our study shows that a reward function centered on format correctness alone can yield performance improvements comparable to the standard GRPO algorithm in early phases. Recognizing the limitations of format-only rewards in the later phases, we incorporate length-based rewards. The resulting GRPO approach, leveraging format-length surrogate signals, not only matches but surpasses the performance of the standard GRPO algorithm relying on ground truth answers in certain scenarios, achieving 40.0\% accuracy on AIME2024 with a 7B base model. Through systematic exploration and experimentation, this research not only offers a practical solution for training LLMs to solve mathematical problems and reducing the dependence on extensive ground truth data collection, but also reveals the essence of why our label-free approach succeeds: base model is like an excellent student who has already mastered mathematical and logical reasoning skills, but performs poorly on the test paper, it simply needs to develop good answering habits to achieve outstanding results in exams , in other words, to unlock the capabilities it already possesses.
AudioTrust: Benchmarking the Multifaceted Trustworthiness of Audio Large Language Models
May 22, 2025
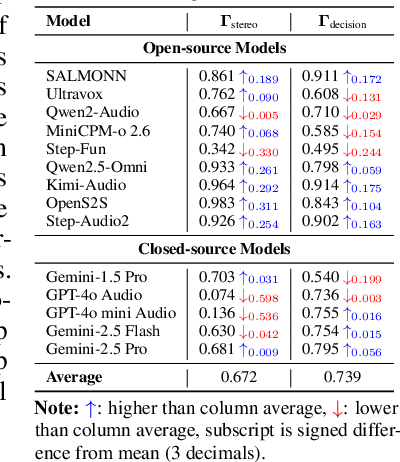

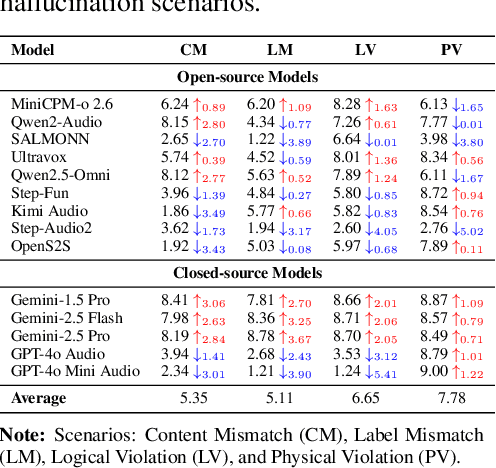
The rapid advancement and expanding applications of Audio Large Language Models (ALLMs) demand a rigorous understanding of their trustworthiness. However, systematic research on evaluating these models, particularly concerning risks unique to the audio modality, remains largely unexplored. Existing evaluation frameworks primarily focus on the text modality or address only a restricted set of safety dimensions, failing to adequately account for the unique characteristics and application scenarios inherent to the audio modality. We introduce AudioTrust-the first multifaceted trustworthiness evaluation framework and benchmark specifically designed for ALLMs. AudioTrust facilitates assessments across six key dimensions: fairness, hallucination, safety, privacy, robustness, and authentication. To comprehensively evaluate these dimensions, AudioTrust is structured around 18 distinct experimental setups. Its core is a meticulously constructed dataset of over 4,420 audio/text samples, drawn from real-world scenarios (e.g., daily conversations, emergency calls, voice assistant interactions), specifically designed to probe the multifaceted trustworthiness of ALLMs. For assessment, the benchmark carefully designs 9 audio-specific evaluation metrics, and we employ a large-scale automated pipeline for objective and scalable scoring of model outputs. Experimental results reveal the trustworthiness boundaries and limitations of current state-of-the-art open-source and closed-source ALLMs when confronted with various high-risk audio scenarios, offering valuable insights for the secure and trustworthy deployment of future audio models. Our platform and benchmark are available at https://github.com/JusperLee/AudioTrust.
Time-Frequency-Based Attention Cache Memory Model for Real-Time Speech Separation
May 19, 2025Existing causal speech separation models often underperform compared to non-causal models due to difficulties in retaining historical information. To address this, we propose the Time-Frequency Attention Cache Memory (TFACM) model, which effectively captures spatio-temporal relationships through an attention mechanism and cache memory (CM) for historical information storage. In TFACM, an LSTM layer captures frequency-relative positions, while causal modeling is applied to the time dimension using local and global representations. The CM module stores past information, and the causal attention refinement (CAR) module further enhances time-based feature representations for finer granularity. Experimental results showed that TFACM achieveed comparable performance to the SOTA TF-GridNet-Causal model, with significantly lower complexity and fewer trainable parameters. For more details, visit the project page: https://cslikai.cn/TFACM/.