 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndependent Reinforcement Learning for Weakly Cooperative Multiagent Traffic Control Problem
Apr 22, 2021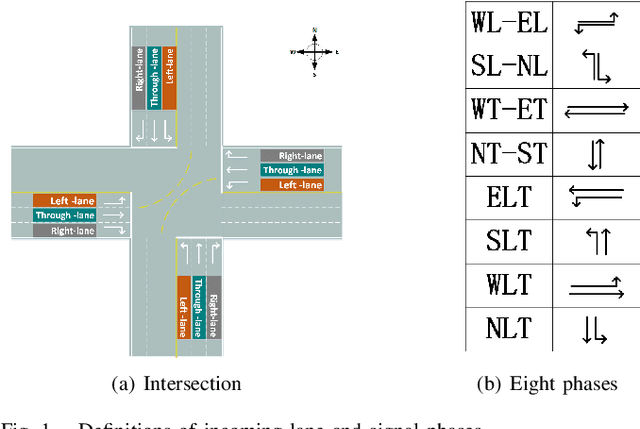

The adaptive traffic signal control (ATSC) problem can be modeled as a multiagent cooperative game among urban intersections, where intersections cooperate to optimize their common goal. Recently, reinforcement learning (RL) has achieved marked successes in managing sequential decision making problems, which motivates us to apply RL in the ASTC problem. Here we use independent reinforcement learning (IRL) to solve a complex traffic cooperative control problem in this study. One of the largest challenges of this problem is that the observation information of intersection is typically partially observable, which limits the learning performance of IRL algorithms. To this, we model the traffic control problem as a partially observable weak cooperative traffic model (PO-WCTM) to optimize the overall traffic situation of a group of intersections. Different from a traditional IRL task that averages the returns of all agents in fully cooperative games, the learning goal of each intersection in PO-WCTM is to reduce the cooperative difficulty of learning, which is also consistent with the traffic environment hypothesis. We also propose an IRL algorithm called Cooperative Important Lenient Double DQN (CIL-DDQN), which extends Double DQN (DDQN) algorithm using two mechanisms: the forgetful experience mechanism and the lenient weight training mechanism. The former mechanism decreases the importance of experiences stored in the experience reply buffer, which deals with the problem of experience failure caused by the strategy change of other agents. The latter mechanism increases the weight experiences with high estimation and `leniently' trains the DDQN neural network, which improves the probability of the selection of cooperative joint strategies. Experimental results show that CIL-DDQN outperforms other methods in almost all performance indicators of the traffic control problem.
Neuron Coverage-Guided Domain Generalization
Feb 27, 2021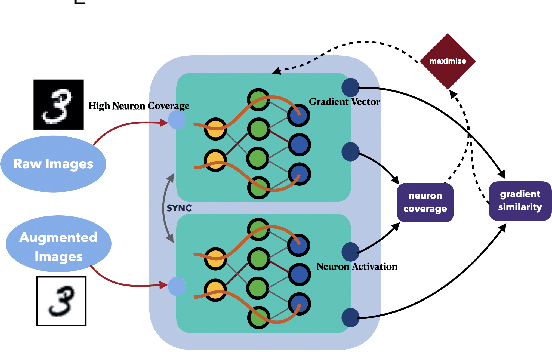
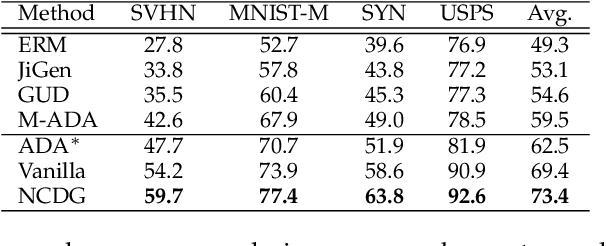
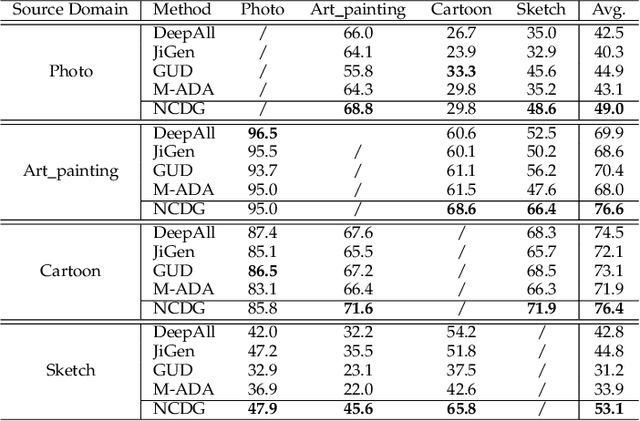
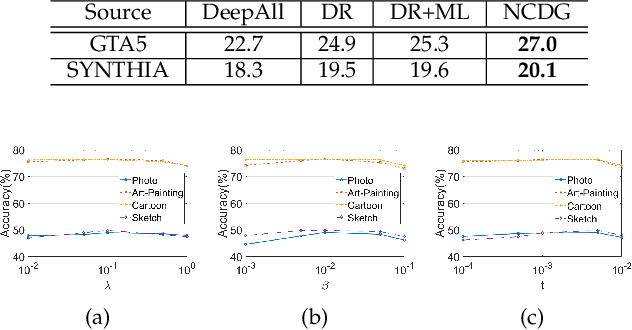
This paper focuses on the domain generalization task where domain knowledge is unavailable, and even worse, only samples from a single domain can be utilized during training. Our motivation originates from the recent progresses in deep neural network (DNN) testing, which has shown that maximizing neuron coverage of DNN can help to explore possible defects of DNN (i.e., misclassification). More specifically, by treating the DNN as a program and each neuron as a functional point of the code, during the network training we aim to improve the generalization capability by maximizing the neuron coverage of DNN with the gradient similarity regularization between the original and augmented samples. As such, the decision behavior of the DNN is optimized, avoiding the arbitrary neurons that are deleterious for the unseen samples, and leading to the trained DNN that can be better generalized to out-of-distribution samples. Extensive studies on various domain generalization tasks based on both single and multiple domain(s) setting demonstrate the effectiveness of our proposed approach compared with state-of-the-art baseline methods. We also analyze our method by conducting visualization based on network dissection. The results further provide useful evidence on the rationality and effectiveness of our approach.
DeepRepair: Style-Guided Repairing for DNNs in the Real-world Operational Environment
Nov 19, 2020
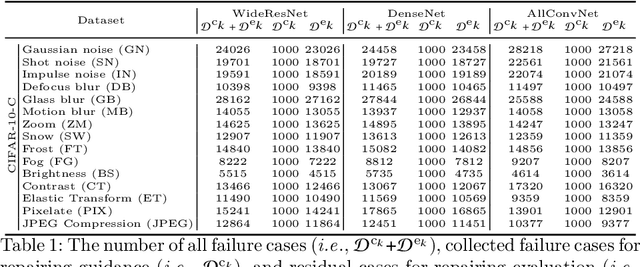
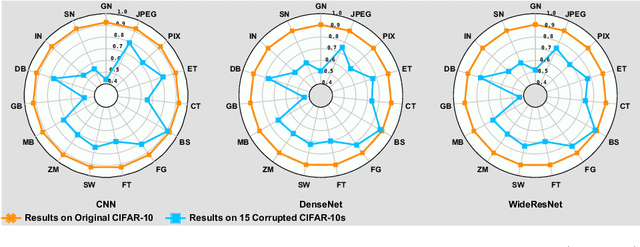
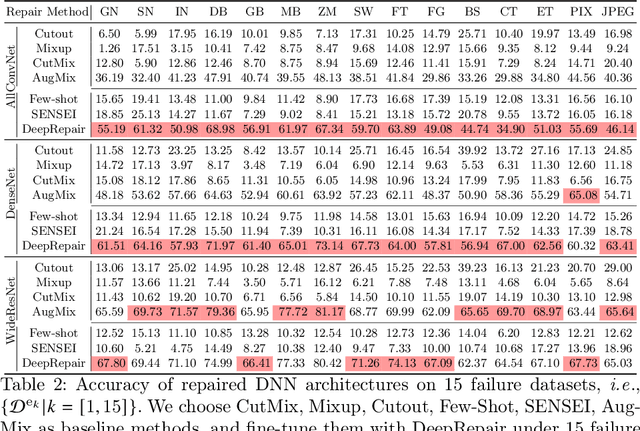
Deep neural networks (DNNs) are being widely applied for various real-world applications across domains due to their high performance (e.g., high accuracy on image classification). Nevertheless, a well-trained DNN after deployment could oftentimes raise errors during practical use in the operational environment due to the mismatching between distributions of the training dataset and the potential unknown noise factors in the operational environment, e.g., weather, blur, noise etc. Hence, it poses a rather important problem for the DNNs' real-world applications: how to repair the deployed DNNs for correcting the failure samples (i.e., incorrect prediction) under the deployed operational environment while not harming their capability of handling normal or clean data. The number of failure samples we can collect in practice, caused by the noise factors in the operational environment, is often limited. Therefore, It is rather challenging how to repair more similar failures based on the limited failure samples we can collect. In this paper, we propose a style-guided data augmentation for repairing DNN in the operational environment. We propose a style transfer method to learn and introduce the unknown failure patterns within the failure data into the training data via data augmentation. Moreover, we further propose the clustering-based failure data generation for much more effective style-guided data augmentation. We conduct a large-scale evaluation with fifteen degradation factors that may happen in the real world and compare with four state-of-the-art data augmentation methods and two DNN repairing methods, demonstrating that our method can significantly enhance the deployed DNNs on the corrupted data in the operational environment, and with even better accuracy on clean datasets.
Bias Field Poses a Threat to DNN-based X-Ray Recognition
Sep 19, 2020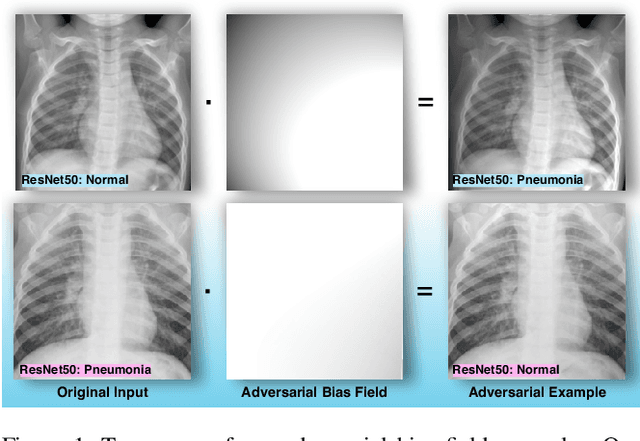



The chest X-ray plays a key role in screening and diagnosis of many lung diseases including the COVID-19. More recently, many works construct deep neural networks (DNNs) for chest X-ray images to realize automated and efficient diagnosis of lung diseases. However, bias field caused by the improper medical image acquisition process widely exists in the chest X-ray images while the robustness of DNNs to the bias field is rarely explored, which definitely poses a threat to the X-ray-based automated diagnosis system. In this paper, we study this problem based on the recent adversarial attack and propose a brand new attack, i.e., the adversarial bias field attack where the bias field instead of the additive noise works as the adversarial perturbations for fooling the DNNs. This novel attack posts a key problem: how to locally tune the bias field to realize high attack success rate while maintaining its spatial smoothness to guarantee high realisticity. These two goals contradict each other and thus has made the attack significantly challenging. To overcome this challenge, we propose the adversarial-smooth bias field attack that can locally tune the bias field with joint smooth & adversarial constraints. As a result, the adversarial X-ray images can not only fool the DNNs effectively but also retain very high level of realisticity. We validate our method on real chest X-ray datasets with powerful DNNs, e.g., ResNet50, DenseNet121, and MobileNet, and show different properties to the state-of-the-art attacks in both image realisticity and attack transferability. Our method reveals the potential threat to the DNN-based X-ray automated diagnosis and can definitely benefit the development of bias-field-robust automated diagnosis system.
EfficientDeRain: Learning Pixel-wise Dilation Filtering for High-Efficiency Single-Image Deraining
Sep 19, 2020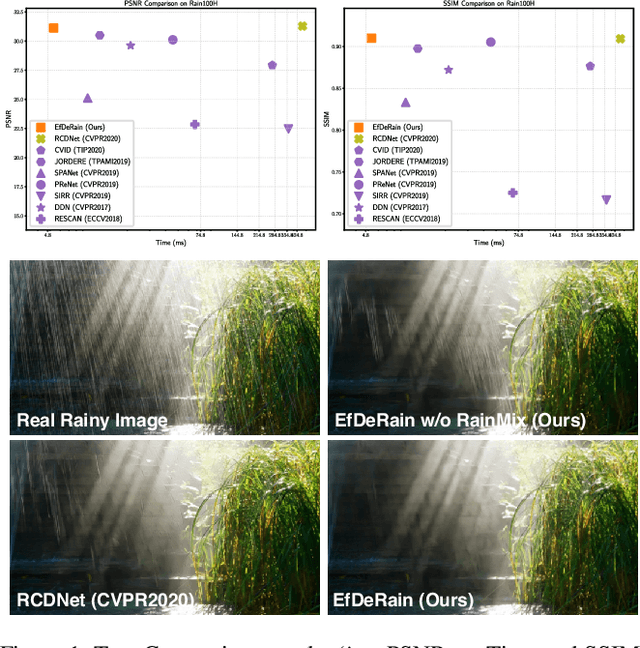

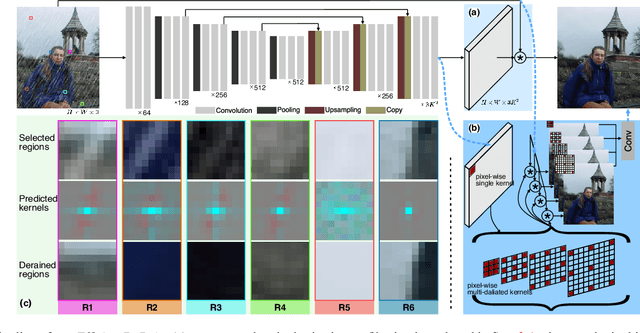

Single-image deraining is rather challenging due to the unknown rain model. Existing methods often make specific assumptions of the rain model, which can hardly cover many diverse circumstances in the real world, making them have to employ complex optimization or progressive refinement. This, however, significantly affects these methods' efficiency and effectiveness for many efficiency-critical applications. To fill this gap, in this paper, we regard the single-image deraining as a general image-enhancing problem and originally propose a model-free deraining method, i.e., EfficientDeRain, which is able to process a rainy image within 10~ms (i.e., around 6~ms on average), over 80 times faster than the state-of-the-art method (i.e., RCDNet), while achieving similar de-rain effects. We first propose the novel pixel-wise dilation filtering. In particular, a rainy image is filtered with the pixel-wise kernels estimated from a kernel prediction network, by which suitable multi-scale kernels for each pixel can be efficiently predicted. Then, to eliminate the gap between synthetic and real data, we further propose an effective data augmentation method (i.e., RainMix) that helps to train network for real rainy image handling.We perform comprehensive evaluation on both synthetic and real-world rainy datasets to demonstrate the effectiveness and efficiency of our method. We release the model and code in https://github.com/tsingqguo/efficientderain.git.
Adversarial Exposure Attack on Diabetic Retinopathy Imagery
Sep 19, 2020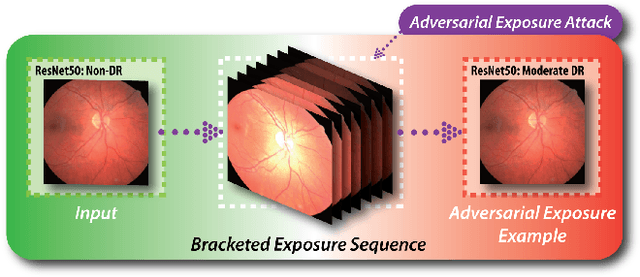
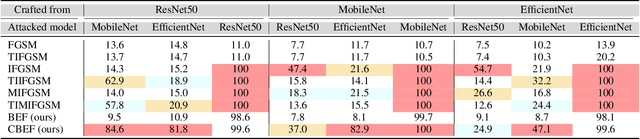
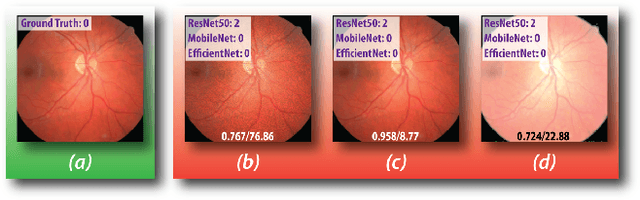

Diabetic retinopathy (DR) is a leading cause of vision loss in the world and numerous cutting-edge works have built powerful deep neural networks (DNNs) to automatically classify the DR cases via the retinal fundus images (RFIs). However, RFIs are usually affected by the widely existing camera exposure while the robustness of DNNs to the exposure is rarely explored. In this paper, we study this problem from the viewpoint of adversarial attack and identify a totally new task, i.e., adversarial exposure attack generating adversarial images by tuning image exposure to mislead the DNNs with significantly high transferability. To this end, we first implement a straightforward method, i.e., multiplicative-perturbation-based exposure attack, and reveal the big challenges of this new task. Then, to make the adversarial image naturalness, we propose the adversarial bracketed exposure fusion that regards the exposure attack as an element-wise bracketed exposure fusion problem in the Laplacian-pyramid space. Moreover, to realize high transferability, we further propose the convolutional bracketed exposure fusion where the element-wise multiplicative operation is extended to the convolution. We validate our method on the real public DR dataset with the advanced DNNs, e.g., ResNet50, MobileNet, and EfficientNet, showing our method can achieve high image quality and success rate of the transfer attack. Our method reveals the potential threats to the DNN-based DR automated diagnosis and can definitely benefit the development of exposure-robust automated DR diagnosis method in the future.
FakeRetouch: Evading DeepFakes Detection via the Guidance of Deliberate Noise
Sep 19, 2020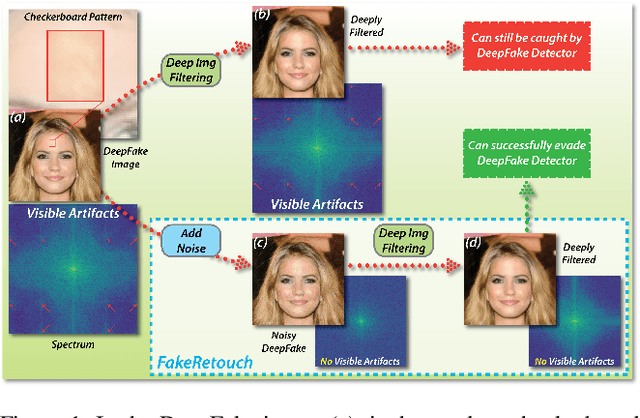
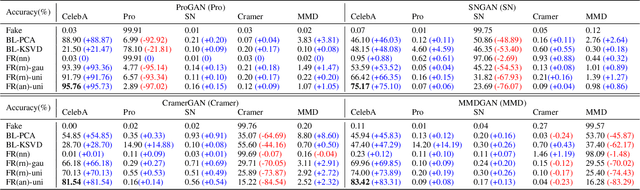

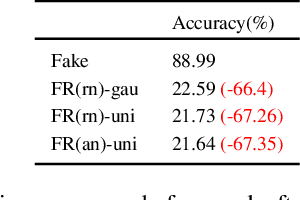
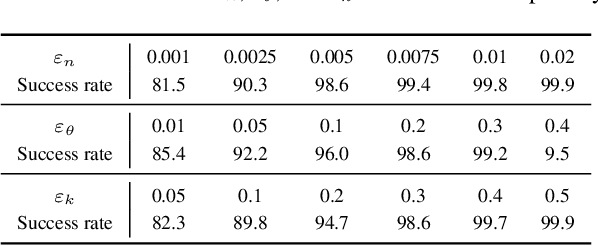
The novelty and creativity of DeepFake generation techniques have attracted worldwide media attention. Many researchers focus on detecting fake images produced by these GAN-based image generation methods with fruitful results, indicating that the GAN-based image generation methods are not yet perfect. Many studies show that the upsampling procedure used in the decoder of GAN-based image generation methods inevitably introduce artifact patterns into fake images. In order to further improve the fidelity of DeepFake images, in this work, we propose a simple yet powerful framework to reduce the artifact patterns of fake images without hurting image quality. The method is based on an important observation that adding noise to a fake image can successfully reduce the artifact patterns in both spatial and frequency domains. Thus we use a combination of additive noise and deep image filtering to reconstruct the fake images, and we name our method FakeRetouch. The deep image filtering provides a specialized filter for each pixel in the noisy image, taking full advantages of deep learning. The deeply filtered images retain very high fidelity to their DeepFake counterparts. Moreover, we use the semantic information of the image to generate an adversarial guidance map to add noise intelligently. Our method aims at improving the fidelity of DeepFake images and exposing the problems of existing DeepFake detection methods, and we hope that the found vulnerabilities can help improve the future generation DeepFake detection methods.
It's Raining Cats or Dogs? Adversarial Rain Attack on DNN Perception
Sep 19, 2020
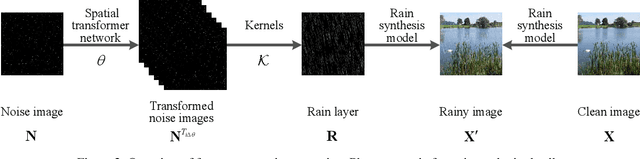
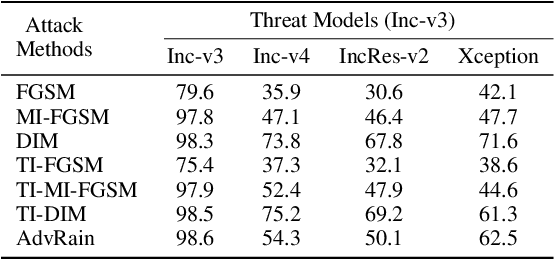
Rain is a common phenomenon in nature and an essential factor for many deep neural network (DNN) based perception systems. Rain can often post inevitable threats that must be carefully addressed especially in the context of safety and security-sensitive scenarios (e.g., autonomous driving). Therefore, a comprehensive investigation of the potential risks of the rain to a DNN is of great importance. Unfortunately, in practice, it is often rather difficult to collect or synthesize rainy images that can represent all raining situations that possibly occur in the real world. To this end, in this paper, we start from a new perspective and propose to combine two totally different studies, i.e., rainy image synthesis and adversarial attack. We present an adversarial rain attack, with which we could simulate various rainy situations with the guidance of deployed DNNs and reveal the potential threat factors that can be brought by rain, helping to develop more rain-robust DNNs. In particular, we propose a factor-aware rain generation that simulates rain steaks according to the camera exposure process and models the learnable rain factors for adversarial attack. With this generator, we further propose the adversarial rain attack against the image classification and object detection, where the rain factors are guided by the various DNNs. As a result, it enables to comprehensively study the impacts of the rain factors to DNNs. Our largescale evaluation on three datasets, i.e., NeurIPS'17 DEV, MS COCO and KITTI, demonstrates that our synthesized rainy images can not only present visually realistic appearances, but also exhibit strong adversarial capability, which builds the foundation for further rain-robust perception studies.
Light Can Hack Your Face! Black-box Backdoor Attack on Face Recognition Systems
Sep 15, 2020
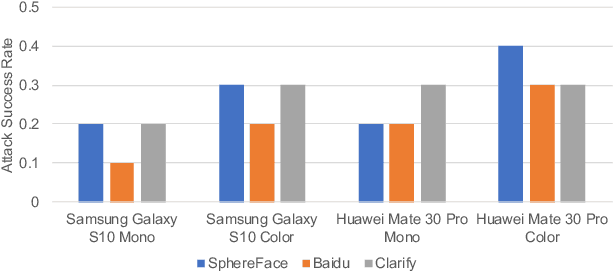


Deep neural networks (DNN) have shown great success in many computer vision applications. However, they are also known to be susceptible to backdoor attacks. When conducting backdoor attacks, most of the existing approaches assume that the targeted DNN is always available, and an attacker can always inject a specific pattern to the training data to further fine-tune the DNN model. However, in practice, such attack may not be feasible as the DNN model is encrypted and only available to the secure enclave. In this paper, we propose a novel black-box backdoor attack technique on face recognition systems, which can be conducted without the knowledge of the targeted DNN model. To be specific, we propose a backdoor attack with a novel color stripe pattern trigger, which can be generated by modulating LED in a specialized waveform. We also use an evolutionary computing strategy to optimize the waveform for backdoor attack. Our backdoor attack can be conducted in a very mild condition: 1) the adversary cannot manipulate the input in an unnatural way (e.g., injecting adversarial noise); 2) the adversary cannot access the training database; 3) the adversary has no knowledge of the training model as well as the training set used by the victim party. We show that the backdoor trigger can be quite effective, where the attack success rate can be up to $88\%$ based on our simulation study and up to $40\%$ based on our physical-domain study by considering the task of face recognition and verification based on at most three-time attempts during authentication. Finally, we evaluate several state-of-the-art potential defenses towards backdoor attacks, and find that our attack can still be effective. We highlight that our study revealed a new physical backdoor attack, which calls for the attention of the security issue of the existing face recognition/verification techniques.
Pasadena: Perceptually Aware and Stealthy Adversarial Denoise Attack
Jul 14, 2020
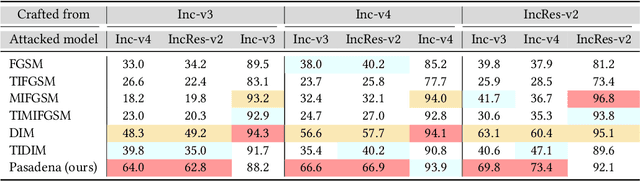
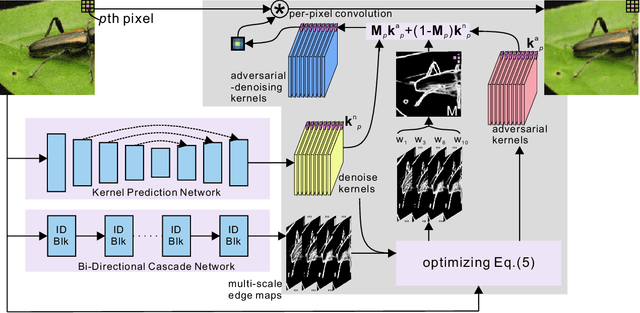

Image denoising techniques have been widely employed in multimedia devices as an image post-processing operation that can remove sensor noise and produce visually clean images for further AI tasks, e.g., image classification. In this paper, we investigate a new task, adversarial denoise attack, that stealthily embeds attacks inside the image denoising module. Thus it can simultaneously denoise input images while fooling the state-of-the-art deep models. We formulate this new task as a kernel prediction problem and propose the adversarial-denoising kernel prediction that can produce adversarial-noiseless kernels for effective denoising and adversarial attacking simultaneously. Furthermore, we implement an adaptive perceptual region localization to identify semantic-related vulnerability regions with which the attack can be more effective while not doing too much harm to the denoising. Thus, our proposed method is termed as Pasadena (Perceptually Aware and Stealthy Adversarial DENoise Attack). We validate our method on the NeurIPS'17 adversarial competition dataset and demonstrate that our method not only realizes denoising but has advantages of high success rate and transferability over the state-of-the-art attacks.