 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPACE: SPike-Aware Consistency Enhancement for Test-Time Adaptation in Spiking Neural Networks
Apr 03, 2025



Spiking Neural Networks (SNNs), as a biologically plausible alternative to Artificial Neural Networks (ANNs), have demonstrated advantages in terms of energy efficiency, temporal processing, and biological plausibility. However, SNNs are highly sensitive to distribution shifts, which can significantly degrade their performance in real-world scenarios. Traditional test-time adaptation (TTA) methods designed for ANNs often fail to address the unique computational dynamics of SNNs, such as sparsity and temporal spiking behavior. To address these challenges, we propose $\textbf{SP}$ike-$\textbf{A}$ware $\textbf{C}$onsistency $\textbf{E}$nhancement (SPACE), the first source-free and single-instance TTA method specifically designed for SNNs. SPACE leverages the inherent spike dynamics of SNNs to maximize the consistency of spike-behavior-based local feature maps across augmented versions of a single test sample, enabling robust adaptation without requiring source data. We evaluate SPACE on multiple datasets, including CIFAR-10-C, CIFAR-100-C, Tiny-ImageNet-C and DVS Gesture-C. Furthermore, SPACE demonstrates strong generalization across different model architectures, achieving consistent performance improvements on both VGG9 and ResNet11. Experimental results show that SPACE outperforms state-of-the-art methods, highlighting its effectiveness and robustness in real-world settings.
Unraveling the Mechanics of Learning-Based Demonstration Selection for In-Context Learning
Jun 14, 2024



Large Language Models (LLMs) have demonstrated impressive in-context learning (ICL) capabilities from few-shot demonstration exemplars. While recent learning-based demonstration selection methods have proven beneficial to ICL by choosing more useful exemplars, their underlying mechanisms are opaque, hindering efforts to address limitations such as high training costs and poor generalization across tasks. These methods generally assume the selection process captures similarities between the exemplar and the target instance, however, it remains unknown what kinds of similarities are captured and vital to performing ICL. To dive into this question, we analyze the working mechanisms of the learning-based demonstration selection methods and empirically identify two important factors related to similarity measurement: 1) The ability to integrate different levels of task-agnostic text similarities between the input of exemplars and test cases enhances generalization power across different tasks. 2) Incorporating task-specific labels when measuring the similarities significantly improves the performance on each specific task. We validate these two findings through extensive quantitative and qualitative analyses across ten datasets and various LLMs. Based on our findings, we introduce two effective yet simplified exemplar selection methods catering to task-agnostic and task-specific demands, eliminating the costly LLM inference overhead.
Gradient-Congruity Guided Federated Sparse Training
May 02, 2024



Edge computing allows artificial intelligence and machine learning models to be deployed on edge devices, where they can learn from local data and collaborate to form a global model. Federated learning (FL) is a distributed machine learning technique that facilitates this process while preserving data privacy. However, FL also faces challenges such as high computational and communication costs regarding resource-constrained devices, and poor generalization performance due to the heterogeneity of data across edge clients and the presence of out-of-distribution data. In this paper, we propose the Gradient-Congruity Guided Federated Sparse Training (FedSGC), a novel method that integrates dynamic sparse training and gradient congruity inspection into federated learning framework to address these issues. Our method leverages the idea that the neurons, in which the associated gradients with conflicting directions with respect to the global model contain irrelevant or less generalized information for other clients, and could be pruned during the sparse training process. Conversely, the neurons where the associated gradients with consistent directions could be grown in a higher priority. In this way, FedSGC can greatly reduce the local computation and communication overheads while, at the same time, enhancing the generalization abilities of FL. We evaluate our method on challenging non-i.i.d settings and show that it achieves competitive accuracy with state-of-the-art FL methods across various scenarios while minimizing computation and communication costs.
Neuron Activation Coverage: Rethinking Out-of-distribution Detection and Generalization
Jun 05, 2023



The out-of-distribution (OOD) problem generally arises when neural networks encounter data that significantly deviates from the training data distribution, \ie, in-distribution (InD). In this paper, we study the OOD problem from a neuron activation view. We first formulate neuron activation states by considering both the neuron output and its influence on model decisions. Then, we propose the concept of \textit{neuron activation coverage} (NAC), which characterizes the neuron behaviors under InD and OOD data. Leveraging our NAC, we show that 1) InD and OOD inputs can be naturally separated based on the neuron behavior, which significantly eases the OOD detection problem and achieves a record-breaking performance of 0.03% FPR95 on ResNet-50, outperforming the previous best method by 20.67%; 2) a positive correlation between NAC and model generalization ability consistently holds across architectures and datasets, which enables a NAC-based criterion for evaluating model robustness. By comparison with the traditional validation criterion, we show that NAC-based criterion not only can select more robust models, but also has a stronger correlation with OOD test performance.
Generalization Beyond Feature Alignment: Concept Activation-Guided Contrastive Learning
Nov 13, 2022Learning invariant representations via contrastive learning has seen state-of-the-art performance in domain generalization (DG). Despite such success, in this paper, we find that its core learning strategy -- feature alignment -- could heavily hinder the model generalization. Inspired by the recent progress in neuron interpretability, we characterize this problem from a neuron activation view. Specifically, by treating feature elements as neuron activation states, we show that conventional alignment methods tend to deteriorate the diversity of learned invariant features, as they indiscriminately minimize all neuron activation differences. This instead ignores rich relations among neurons -- many of them often identify the same visual concepts though they emerge differently. With this finding, we present a simple yet effective approach, \textit{Concept Contrast} (CoCo), which relaxes element-wise feature alignments by contrasting high-level concepts encoded in neurons. This approach is highly flexible and can be integrated into any contrastive method in DG. Through extensive experiments, we further demonstrate that our CoCo promotes the diversity of feature representations, and consistently improves model generalization capability over the DomainBed benchmark.
Privacy-Preserving Constrained Domain Generalization for Medical Image Classification
May 14, 2021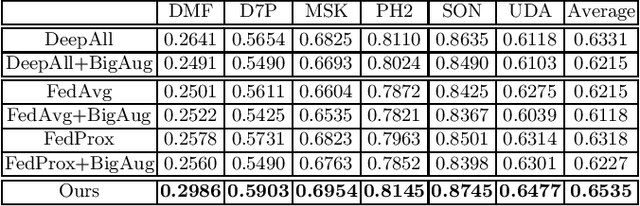
Deep neural networks (DNN) have demonstrated unprecedented success for medical imaging applications. However, due to the issue of limited dataset availability and the strict legal and ethical requirements for patient privacy protection, the broad applications of medical imaging classification driven by DNN with large-scale training data have been largely hindered. For example, when training the DNN from one domain (e.g., with data only from one hospital), the generalization capability to another domain (e.g., data from another hospital) could be largely lacking. In this paper, we aim to tackle this problem by developing the privacy-preserving constrained domain generalization method, aiming to improve the generalization capability under the privacy-preserving condition. In particular, We propose to improve the information aggregation process on the centralized server-side with a novel gradient alignment loss, expecting that the trained model can be better generalized to the "unseen" but related medical images. The rationale and effectiveness of our proposed method can be explained by connecting our proposed method with the Maximum Mean Discrepancy (MMD) which has been widely adopted as the distribution distance measurement. Experimental results on two challenging medical imaging classification tasks indicate that our method can achieve better cross-domain generalization capability compared to the state-of-the-art federated learning methods.
Neuron Coverage-Guided Domain Generalization
Feb 27, 2021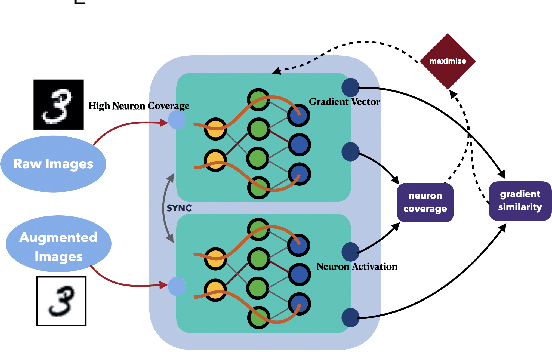
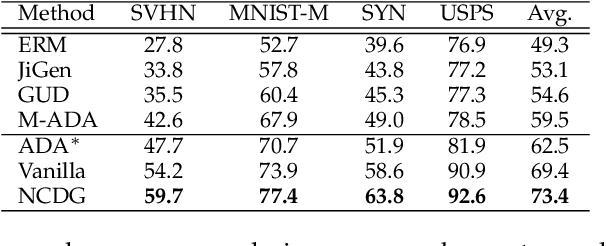
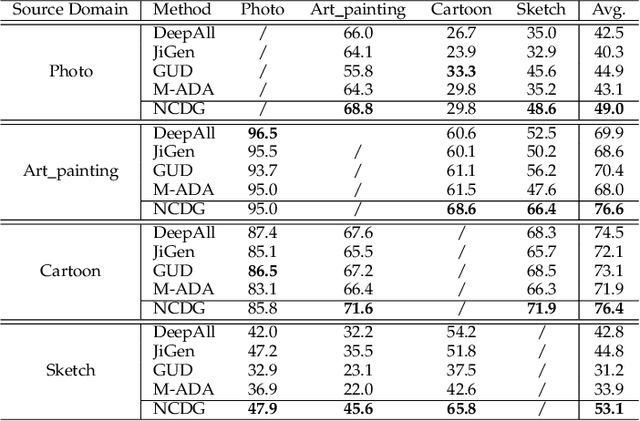
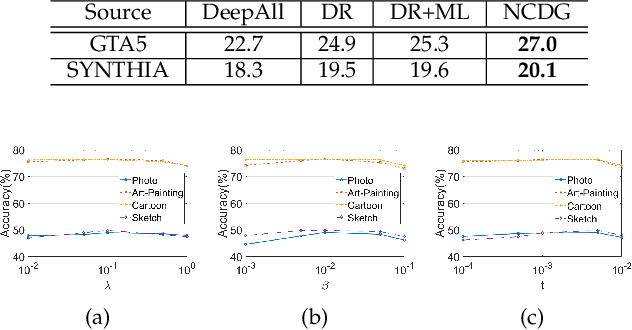
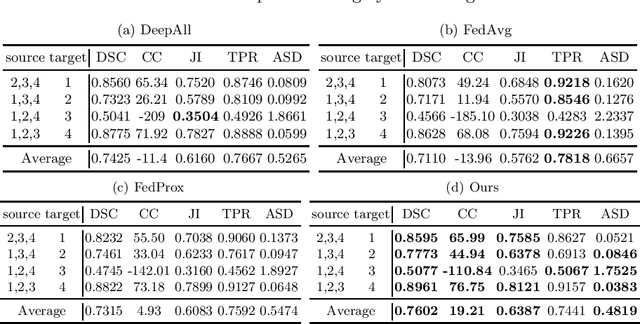
This paper focuses on the domain generalization task where domain knowledge is unavailable, and even worse, only samples from a single domain can be utilized during training. Our motivation originates from the recent progresses in deep neural network (DNN) testing, which has shown that maximizing neuron coverage of DNN can help to explore possible defects of DNN (i.e., misclassification). More specifically, by treating the DNN as a program and each neuron as a functional point of the code, during the network training we aim to improve the generalization capability by maximizing the neuron coverage of DNN with the gradient similarity regularization between the original and augmented samples. As such, the decision behavior of the DNN is optimized, avoiding the arbitrary neurons that are deleterious for the unseen samples, and leading to the trained DNN that can be better generalized to out-of-distribution samples. Extensive studies on various domain generalization tasks based on both single and multiple domain(s) setting demonstrate the effectiveness of our proposed approach compared with state-of-the-art baseline methods. We also analyze our method by conducting visualization based on network dissection. The results further provide useful evidence on the rationality and effectiveness of our approach.