 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptiveFL: Adaptive Heterogeneous Federated Learning for Resource-Constrained AIoT Systems
Nov 22, 2023



Although Federated Learning (FL) is promising to enable collaborative learning among Artificial Intelligence of Things (AIoT) devices, it suffers from the problem of low classification performance due to various heterogeneity factors (e.g., computing capacity, memory size) of devices and uncertain operating environments. To address these issues, this paper introduces an effective FL approach named AdaptiveFL based on a novel fine-grained width-wise model pruning strategy, which can generate various heterogeneous local models for heterogeneous AIoT devices. By using our proposed reinforcement learning-based device selection mechanism, AdaptiveFL can adaptively dispatch suitable heterogeneous models to corresponding AIoT devices on the fly based on their available resources for local training. Experimental results show that, compared to state-of-the-art methods, AdaptiveFL can achieve up to 16.83% inference improvements for both IID and non-IID scenarios.
When GPT Meets Program Analysis: Towards Intelligent Detection of Smart Contract Logic Vulnerabilities in GPTScan
Aug 07, 2023



Smart contracts are prone to various vulnerabilities, leading to substantial financial losses over time. Current analysis tools mainly target vulnerabilities with fixed control or dataflow patterns, such as re-entrancy and integer overflow. However, a recent study on Web3 security bugs revealed that about 80% of these bugs cannot be audited by existing tools due to the lack of domain-specific property description and checking. Given recent advances in Generative Pretraining Transformer (GPT), it is worth exploring how GPT could aid in detecting logic vulnerabilities in smart contracts. In this paper, we propose GPTScan, the first tool combining GPT with static analysis for smart contract logic vulnerability detection. Instead of relying solely on GPT to identify vulnerabilities, which can lead to high false positives and is limited by GPT's pre-trained knowledge, we utilize GPT as a versatile code understanding tool. By breaking down each logic vulnerability type into scenarios and properties, GPTScan matches candidate vulnerabilities with GPT. To enhance accuracy, GPTScan further instructs GPT to intelligently recognize key variables and statements, which are then validated by static confirmation. Evaluation on diverse datasets with around 400 contract projects and 3K Solidity files shows that GPTScan achieves high precision (over 90%) for token contracts and acceptable precision (57.14%) for large projects like Web3Bugs. It effectively detects groundtruth logic vulnerabilities with a recall of over 80%, including 9 new vulnerabilities missed by human auditors. GPTScan is fast and cost-effective, taking an average of 14.39 seconds and 0.01 USD to scan per thousand lines of Solidity code. Moreover, static confirmation helps GPTScan reduce two-thirds of false positives.
Evaluating the Robustness of Test Selection Methods for Deep Neural Networks
Jul 29, 2023Testing deep learning-based systems is crucial but challenging due to the required time and labor for labeling collected raw data. To alleviate the labeling effort, multiple test selection methods have been proposed where only a subset of test data needs to be labeled while satisfying testing requirements. However, we observe that such methods with reported promising results are only evaluated under simple scenarios, e.g., testing on original test data. This brings a question to us: are they always reliable? In this paper, we explore when and to what extent test selection methods fail for testing. Specifically, first, we identify potential pitfalls of 11 selection methods from top-tier venues based on their construction. Second, we conduct a study on five datasets with two model architectures per dataset to empirically confirm the existence of these pitfalls. Furthermore, we demonstrate how pitfalls can break the reliability of these methods. Concretely, methods for fault detection suffer from test data that are: 1) correctly classified but uncertain, or 2) misclassified but confident. Remarkably, the test relative coverage achieved by such methods drops by up to 86.85%. On the other hand, methods for performance estimation are sensitive to the choice of intermediate-layer output. The effectiveness of such methods can be even worse than random selection when using an inappropriate layer.
Multi-target Backdoor Attacks for Code Pre-trained Models
Jun 14, 2023



Backdoor attacks for neural code models have gained considerable attention due to the advancement of code intelligence. However, most existing works insert triggers into task-specific data for code-related downstream tasks, thereby limiting the scope of attacks. Moreover, the majority of attacks for pre-trained models are designed for understanding tasks. In this paper, we propose task-agnostic backdoor attacks for code pre-trained models. Our backdoored model is pre-trained with two learning strategies (i.e., Poisoned Seq2Seq learning and token representation learning) to support the multi-target attack of downstream code understanding and generation tasks. During the deployment phase, the implanted backdoors in the victim models can be activated by the designed triggers to achieve the targeted attack. We evaluate our approach on two code understanding tasks and three code generation tasks over seven datasets. Extensive experiments demonstrate that our approach can effectively and stealthily attack code-related downstream tasks.
RNNS: Representation Nearest Neighbor Search Black-Box Attack on Code Models
May 20, 2023Pre-trained code models are mainly evaluated using the in-distribution test data. The robustness of models, i.e., the ability to handle hard unseen data, still lacks evaluation. In this paper, we propose a novel search-based black-box adversarial attack guided by model behaviours for pre-trained programming language models, named Representation Nearest Neighbor Search(RNNS), to evaluate the robustness of Pre-trained PL models. Unlike other black-box adversarial attacks, RNNS uses the model-change signal to guide the search in the space of the variable names collected from real-world projects. Specifically, RNNS contains two main steps, 1) indicate which variable (attack position location) we should attack based on model uncertainty, and 2) search which adversarial tokens we should use for variable renaming according to the model behaviour observations. We evaluate RNNS on 6 code tasks (e.g., clone detection), 3 programming languages (Java, Python, and C), and 3 pre-trained code models: CodeBERT, GraphCodeBERT, and CodeT5. The results demonstrate that RNNS outperforms the state-of-the-art black-box attacking methods (MHM and ALERT) in terms of attack success rate (ASR) and query times (QT). The perturbation of generated adversarial examples from RNNS is smaller than the baselines with respect to the number of replaced variables and the variable length change. Our experiments also show that RNNS is efficient in attacking the defended models and is useful for adversarial training.
Evading DeepFake Detectors via Adversarial Statistical Consistency
Apr 23, 2023



In recent years, as various realistic face forgery techniques known as DeepFake improves by leaps and bounds,more and more DeepFake detection techniques have been proposed. These methods typically rely on detecting statistical differences between natural (i.e., real) and DeepFakegenerated images in both spatial and frequency domains. In this work, we propose to explicitly minimize the statistical differences to evade state-of-the-art DeepFake detectors. To this end, we propose a statistical consistency attack (StatAttack) against DeepFake detectors, which contains two main parts. First, we select several statistical-sensitive natural degradations (i.e., exposure, blur, and noise) and add them to the fake images in an adversarial way. Second, we find that the statistical differences between natural and DeepFake images are positively associated with the distribution shifting between the two kinds of images, and we propose to use a distribution-aware loss to guide the optimization of different degradations. As a result, the feature distributions of generated adversarial examples is close to the natural images.Furthermore, we extend the StatAttack to a more powerful version, MStatAttack, where we extend the single-layer degradation to multi-layer degradations sequentially and use the loss to tune the combination weights jointly. Comprehensive experimental results on four spatial-based detectors and two frequency-based detectors with four datasets demonstrate the effectiveness of our proposed attack method in both white-box and black-box settings.
Neural Episodic Control with State Abstraction
Jan 27, 2023Existing Deep Reinforcement Learning (DRL) algorithms suffer from sample inefficiency. Generally, episodic control-based approaches are solutions that leverage highly-rewarded past experiences to improve sample efficiency of DRL algorithms. However, previous episodic control-based approaches fail to utilize the latent information from the historical behaviors (e.g., state transitions, topological similarities, etc.) and lack scalability during DRL training. This work introduces Neural Episodic Control with State Abstraction (NECSA), a simple but effective state abstraction-based episodic control containing a more comprehensive episodic memory, a novel state evaluation, and a multi-step state analysis. We evaluate our approach to the MuJoCo and Atari tasks in OpenAI gym domains. The experimental results indicate that NECSA achieves higher sample efficiency than the state-of-the-art episodic control-based approaches. Our data and code are available at the project website\footnote{\url{https://sites.google.com/view/drl-necsa}}.
Is Self-Attention Powerful to Learn Code Syntax and Semantics?
Dec 20, 2022Pre-trained language models for programming languages have shown a powerful ability on processing many Software Engineering (SE) tasks, e.g., program synthesis, code completion, and code search. However, it remains to be seen what is behind their success. Recent studies have examined how pre-trained models can effectively learn syntax information based on Abstract Syntax Trees. In this paper, we figure out what role the self-attention mechanism plays in understanding code syntax and semantics based on AST and static analysis. We focus on a well-known representative code model, CodeBERT, and study how it can learn code syntax and semantics by the self-attention mechanism and Masked Language Modelling (MLM) at the token level. We propose a group of probing tasks to analyze CodeBERT. Based on AST and static analysis, we establish the relationships among the code tokens. First, Our results show that CodeBERT can acquire syntax and semantics knowledge through self-attention and MLM. Second, we demonstrate that the self-attention mechanism pays more attention to dependence-relationship tokens than to other tokens. Different attention heads play different roles in learning code semantics; we show that some of them are weak at encoding code semantics. Different layers have different competencies to represent different code properties. Deep CodeBERT layers can encode the semantic information that requires some complex inference in the code context. More importantly, we show that our analysis is helpful and leverage our conclusions to improve CodeBERT. We show an alternative approach for pre-training models, which makes fully use of the current pre-training strategy, i.e, MLM, to learn code syntax and semantics, instead of combining features from different code data formats, e.g., data-flow, running-time states, and program outputs.
Decompiling x86 Deep Neural Network Executables
Oct 04, 2022
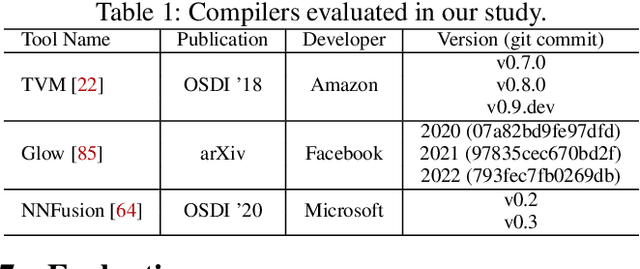
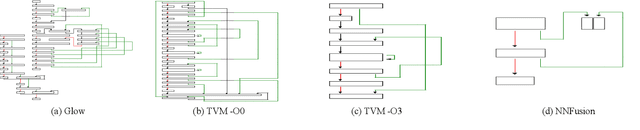
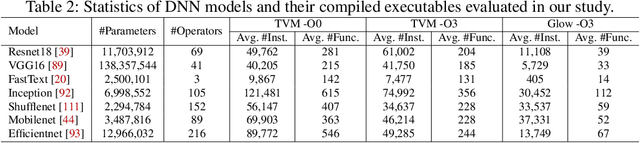
Due to their widespread use on heterogeneous hardware devices, deep learning (DL) models are compiled into executables by DL compilers to fully leverage low-level hardware primitives. This approach allows DL computations to be undertaken at low cost across a variety of computing platforms, including CPUs, GPUs, and various hardware accelerators. We present BTD (Bin to DNN), a decompiler for deep neural network (DNN) executables. BTD takes DNN executables and outputs full model specifications, including types of DNN operators, network topology, dimensions, and parameters that are (nearly) identical to those of the input models. BTD delivers a practical framework to process DNN executables compiled by different DL compilers and with full optimizations enabled on x86 platforms. It employs learning-based techniques to infer DNN operators, dynamic analysis to reveal network architectures, and symbolic execution to facilitate inferring dimensions and parameters of DNN operators. Our evaluation reveals that BTD enables accurate recovery of full specifications of complex DNNs with millions of parameters (e.g., ResNet). The recovered DNN specifications can be re-compiled into a new DNN executable exhibiting identical behavior to the input executable. We show that BTD can boost two representative attacks, adversarial example generation and knowledge stealing, against DNN executables. We also demonstrate cross-architecture legacy code reuse using BTD, and envision BTD being used for other critical downstream tasks like DNN security hardening and patching.
Efficient Testing of Deep Neural Networks via Decision Boundary Analysis
Jul 22, 2022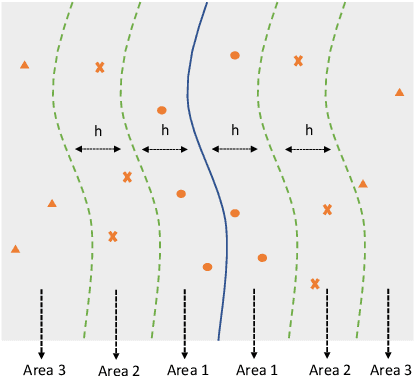

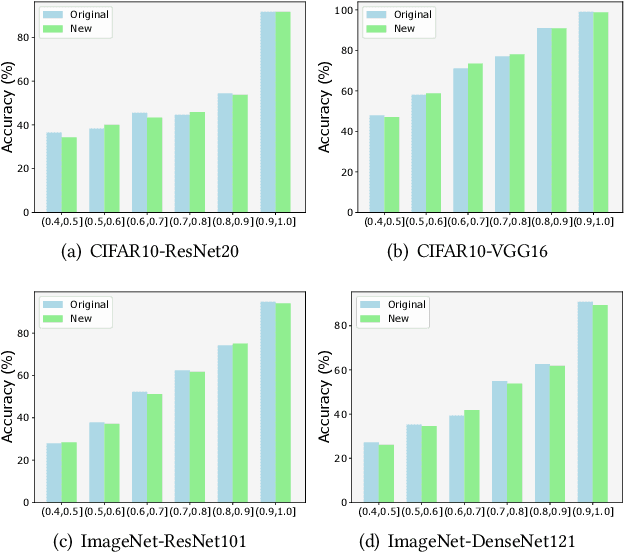

Deep learning plays a more and more important role in our daily life due to its competitive performance in multiple industrial application domains. As the core of DL-enabled systems, deep neural networks automatically learn knowledge from carefully collected and organized training data to gain the ability to predict the label of unseen data. Similar to the traditional software systems that need to be comprehensively tested, DNNs also need to be carefully evaluated to make sure the quality of the trained model meets the demand. In practice, the de facto standard to assess the quality of DNNs in industry is to check their performance (accuracy) on a collected set of labeled test data. However, preparing such labeled data is often not easy partly because of the huge labeling effort, i.e., data labeling is labor-intensive, especially with the massive new incoming unlabeled data every day. Recent studies show that test selection for DNN is a promising direction that tackles this issue by selecting minimal representative data to label and using these data to assess the model. However, it still requires human effort and cannot be automatic. In this paper, we propose a novel technique, named Aries, that can estimate the performance of DNNs on new unlabeled data using only the information obtained from the original test data. The key insight behind our technique is that the model should have similar prediction accuracy on the data which have similar distances to the decision boundary. We performed a large-scale evaluation of our technique on 13 types of data transformation methods. The results demonstrate the usefulness of our technique that the estimated accuracy by Aries is only 0.03% -- 2.60% (on average 0.61%) off the true accuracy. Besides, Aries also outperforms the state-of-the-art selection-labeling-based methods in most (96 out of 128) cases.