 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedVLMBench: Benchmarking Federated Fine-Tuning of Vision-Language Models
Jun 11, 2025Vision-Language Models (VLMs) have demonstrated remarkable capabilities in cross-modal understanding and generation by integrating visual and textual information. While instruction tuning and parameter-efficient fine-tuning methods have substantially improved the generalization of VLMs, most existing approaches rely on centralized training, posing challenges for deployment in domains with strict privacy requirements like healthcare. Recent efforts have introduced Federated Learning (FL) into VLM fine-tuning to address these privacy concerns, yet comprehensive benchmarks for evaluating federated fine-tuning strategies, model architectures, and task generalization remain lacking. In this work, we present \textbf{FedVLMBench}, the first systematic benchmark for federated fine-tuning of VLMs. FedVLMBench integrates two mainstream VLM architectures (encoder-based and encoder-free), four fine-tuning strategies, five FL algorithms, six multimodal datasets spanning four cross-domain single-task scenarios and two cross-domain multitask settings, covering four distinct downstream task categories. Through extensive experiments, we uncover key insights into the interplay between VLM architectures, fine-tuning strategies, data heterogeneity, and multi-task federated optimization. Notably, we find that a 2-layer multilayer perceptron (MLP) connector with concurrent connector and LLM tuning emerges as the optimal configuration for encoder-based VLMs in FL. Furthermore, current FL methods exhibit significantly higher sensitivity to data heterogeneity in vision-centric tasks than text-centric ones, across both encoder-free and encoder-based VLM architectures. Our benchmark provides essential tools, datasets, and empirical guidance for the research community, offering a standardized platform to advance privacy-preserving, federated training of multimodal foundation models.
Exploring the Vulnerabilities of Federated Learning: A Deep Dive into Gradient Inversion Attacks
Mar 13, 2025



Federated Learning (FL) has emerged as a promising privacy-preserving collaborative model training paradigm without sharing raw data. However, recent studies have revealed that private information can still be leaked through shared gradient information and attacked by Gradient Inversion Attacks (GIA). While many GIA methods have been proposed, a detailed analysis, evaluation, and summary of these methods are still lacking. Although various survey papers summarize existing privacy attacks in FL, few studies have conducted extensive experiments to unveil the effectiveness of GIA and their associated limiting factors in this context. To fill this gap, we first undertake a systematic review of GIA and categorize existing methods into three types, i.e., \textit{optimization-based} GIA (OP-GIA), \textit{generation-based} GIA (GEN-GIA), and \textit{analytics-based} GIA (ANA-GIA). Then, we comprehensively analyze and evaluate the three types of GIA in FL, providing insights into the factors that influence their performance, practicality, and potential threats. Our findings indicate that OP-GIA is the most practical attack setting despite its unsatisfactory performance, while GEN-GIA has many dependencies and ANA-GIA is easily detectable, making them both impractical. Finally, we offer a three-stage defense pipeline to users when designing FL frameworks and protocols for better privacy protection and share some future research directions from the perspectives of attackers and defenders that we believe should be pursued. We hope that our study can help researchers design more robust FL frameworks to defend against these attacks.
A New Federated Learning Framework Against Gradient Inversion Attacks
Dec 10, 2024



Federated Learning (FL) aims to protect data privacy by enabling clients to collectively train machine learning models without sharing their raw data. However, recent studies demonstrate that information exchanged during FL is subject to Gradient Inversion Attacks (GIA) and, consequently, a variety of privacy-preserving methods have been integrated into FL to thwart such attacks, such as Secure Multi-party Computing (SMC), Homomorphic Encryption (HE), and Differential Privacy (DP). Despite their ability to protect data privacy, these approaches inherently involve substantial privacy-utility trade-offs. By revisiting the key to privacy exposure in FL under GIA, which lies in the frequent sharing of model gradients that contain private data, we take a new perspective by designing a novel privacy preserve FL framework that effectively ``breaks the direct connection'' between the shared parameters and the local private data to defend against GIA. Specifically, we propose a Hypernetwork Federated Learning (HyperFL) framework that utilizes hypernetworks to generate the parameters of the local model and only the hypernetwork parameters are uploaded to the server for aggregation. Theoretical analyses demonstrate the convergence rate of the proposed HyperFL, while extensive experimental results show the privacy-preserving capability and comparable performance of HyperFL. Code is available at https://github.com/Pengxin-Guo/HyperFL.
Selective Aggregation for Low-Rank Adaptation in Federated Learning
Oct 02, 2024



We investigate LoRA in federated learning through the lens of the asymmetry analysis of the learned $A$ and $B$ matrices. In doing so, we uncover that $A$ matrices are responsible for learning general knowledge, while $B$ matrices focus on capturing client-specific knowledge. Based on this finding, we introduce Federated Share-A Low-Rank Adaptation (FedSA-LoRA), which employs two low-rank trainable matrices $A$ and $B$ to model the weight update, but only $A$ matrices are shared with the server for aggregation. Moreover, we delve into the relationship between the learned $A$ and $B$ matrices in other LoRA variants, such as rsLoRA and VeRA, revealing a consistent pattern. Consequently, we extend our FedSA-LoRA method to these LoRA variants, resulting in FedSA-rsLoRA and FedSA-VeRA. In this way, we establish a general paradigm for integrating LoRA with FL, offering guidance for future work on subsequent LoRA variants combined with FL. Extensive experimental results on natural language understanding and generation tasks demonstrate the effectiveness of the proposed method.
Dual-View Pyramid Pooling in Deep Neural Networks for Improved Medical Image Classification and Confidence Calibration
Aug 06, 2024



Spatial pooling (SP) and cross-channel pooling (CCP) operators have been applied to aggregate spatial features and pixel-wise features from feature maps in deep neural networks (DNNs), respectively. Their main goal is to reduce computation and memory overhead without visibly weakening the performance of DNNs. However, SP often faces the problem of losing the subtle feature representations, while CCP has a high possibility of ignoring salient feature representations, which may lead to both miscalibration of confidence issues and suboptimal medical classification results. To address these problems, we propose a novel dual-view framework, the first to systematically investigate the relative roles of SP and CCP by analyzing the difference between spatial features and pixel-wise features. Based on this framework, we propose a new pooling method, termed dual-view pyramid pooling (DVPP), to aggregate multi-scale dual-view features. DVPP aims to boost both medical image classification and confidence calibration performance by fully leveraging the merits of SP and CCP operators from a dual-axis perspective. Additionally, we discuss how to fulfill DVPP with five parameter-free implementations. Extensive experiments on six 2D/3D medical image classification tasks show that our DVPP surpasses state-of-the-art pooling methods in terms of medical image classification results and confidence calibration across different DNNs.
Online Test-Time Adaptation of Spatial-Temporal Traffic Flow Forecasting
Jan 08, 2024Accurate spatial-temporal traffic flow forecasting is crucial in aiding traffic managers in implementing control measures and assisting drivers in selecting optimal travel routes. Traditional deep-learning based methods for traffic flow forecasting typically rely on historical data to train their models, which are then used to make predictions on future data. However, the performance of the trained model usually degrades due to the temporal drift between the historical and future data. To make the model trained on historical data better adapt to future data in a fully online manner, this paper conducts the first study of the online test-time adaptation techniques for spatial-temporal traffic flow forecasting problems. To this end, we propose an Adaptive Double Correction by Series Decomposition (ADCSD) method, which first decomposes the output of the trained model into seasonal and trend-cyclical parts and then corrects them by two separate modules during the testing phase using the latest observed data entry by entry. In the proposed ADCSD method, instead of fine-tuning the whole trained model during the testing phase, a lite network is attached after the trained model, and only the lite network is fine-tuned in the testing process each time a data entry is observed. Moreover, to satisfy that different time series variables may have different levels of temporal drift, two adaptive vectors are adopted to provide different weights for different time series variables. Extensive experiments on four real-world traffic flow forecasting datasets demonstrate the effectiveness of the proposed ADCSD method. The code is available at https://github.com/Pengxin-Guo/ADCSD.
A Unified Framework for Unsupervised Domain Adaptation based on Instance Weighting
Dec 08, 2023



Despite the progress made in domain adaptation, solving Unsupervised Domain Adaptation (UDA) problems with a general method under complex conditions caused by label shifts between domains remains a formidable task. In this work, we comprehensively investigate four distinct UDA settings including closed set domain adaptation, partial domain adaptation, open set domain adaptation, and universal domain adaptation, where shared common classes between source and target domains coexist alongside domain-specific private classes. The prominent challenges inherent in diverse UDA settings center around the discrimination of common/private classes and the precise measurement of domain discrepancy. To surmount these challenges effectively, we propose a novel yet effective method called Learning Instance Weighting for Unsupervised Domain Adaptation (LIWUDA), which caters to various UDA settings. Specifically, the proposed LIWUDA method constructs a weight network to assign weights to each instance based on its probability of belonging to common classes, and designs Weighted Optimal Transport (WOT) for domain alignment by leveraging instance weights. Additionally, the proposed LIWUDA method devises a Separate and Align (SA) loss to separate instances with low similarities and align instances with high similarities. To guide the learning of the weight network, Intra-domain Optimal Transport (IOT) is proposed to enforce the weights of instances in common classes to follow a uniform distribution. Through the integration of those three components, the proposed LIWUDA method demonstrates its capability to address all four UDA settings in a unified manner. Experimental evaluations conducted on three benchmark datasets substantiate the effectiveness of the proposed LIWUDA method.
Domain Adaptation via Bidirectional Cross-Attention Transformer
Jan 15, 2022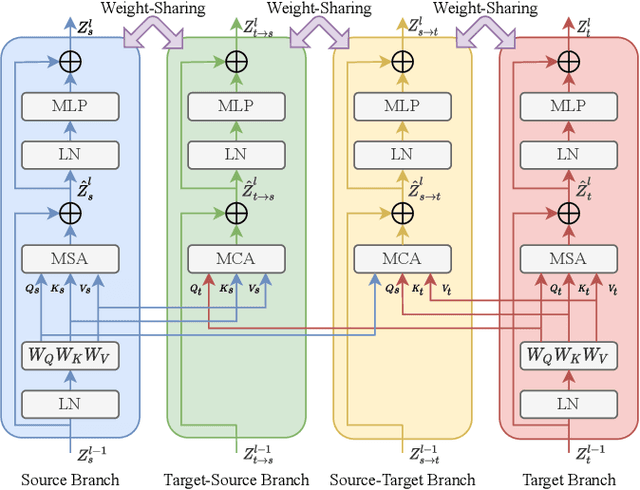
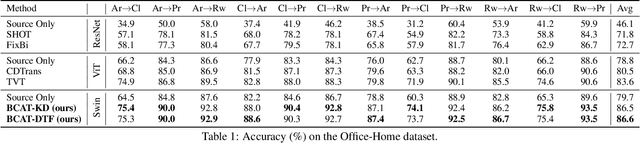
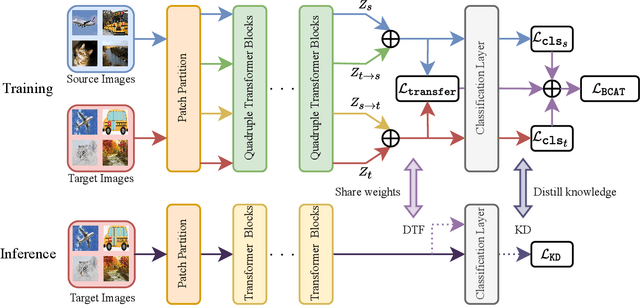
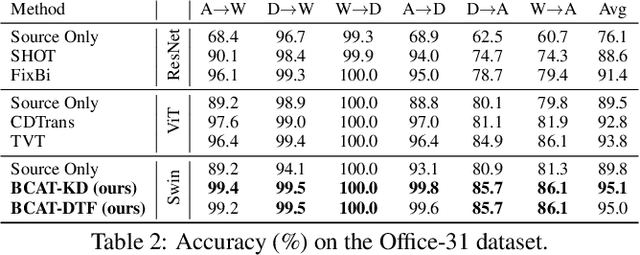
Domain Adaptation (DA) aims to leverage the knowledge learned from a source domain with ample labeled data to a target domain with unlabeled data only. Most existing studies on DA contribute to learning domain-invariant feature representations for both domains by minimizing the domain gap based on convolution-based neural networks. Recently, vision transformers significantly improved performance in multiple vision tasks. Built on vision transformers, in this paper we propose a Bidirectional Cross-Attention Transformer (BCAT) for DA with the aim to improve the performance. In the proposed BCAT, the attention mechanism can extract implicit source and target mix-up feature representations to narrow the domain discrepancy. Specifically, in BCAT, we design a weight-sharing quadruple-branch transformer with a bidirectional cross-attention mechanism to learn domain-invariant feature representations. Extensive experiments demonstrate that the proposed BCAT model achieves superior performance on four benchmark datasets over existing state-of-the-art DA methods that are based on convolutions or transformers.
Safe Multi-Task Learning
Nov 20, 2021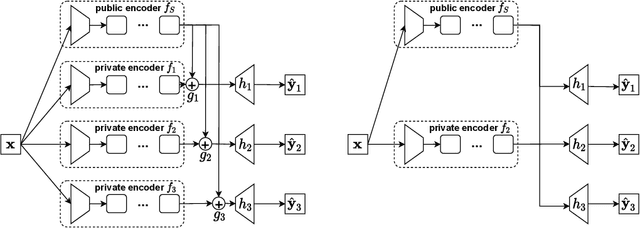
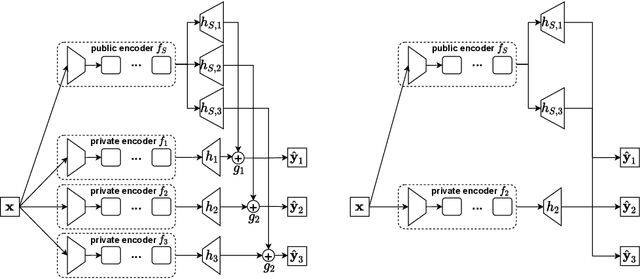
In recent years, Multi-Task Learning (MTL) attracts much attention due to its good performance in many applications. However, many existing MTL models cannot guarantee that its performance is no worse than its single-task counterpart on each task. Though this phenomenon has been empirically observed by some works, little work aims to handle the resulting problem, which is formally defined as negative sharing in this paper. To achieve safe multi-task learning where no \textit{negative sharing} occurs, we propose a Safe Multi-Task Learning (SMTL) model, which consists of a public encoder shared by all the tasks, private encoders, gates, and private decoders. Specifically, each task has a private encoder, a gate, and a private decoder, where the gate is to learn how to combine the private encoder and public encoder for the downstream private decoder. To reduce the storage cost during the inference stage, a lite version of SMTL is proposed to allow the gate to choose either the public encoder or the corresponding private encoder. Moreover, we propose a variant of SMTL to place all the gates after decoders of all the tasks. Experiments on several benchmark datasets demonstrate the effectiveness of the proposed methods.
Domain Adaptation by Maximizing Population Correlation with Neural Architecture Search
Sep 12, 2021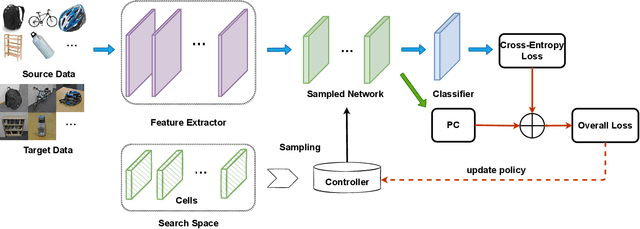
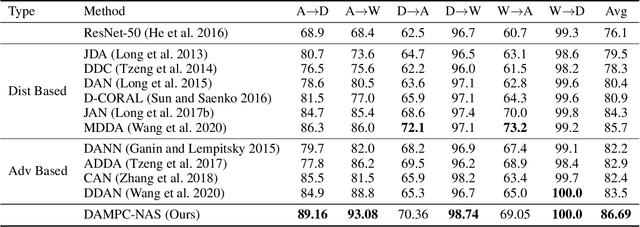
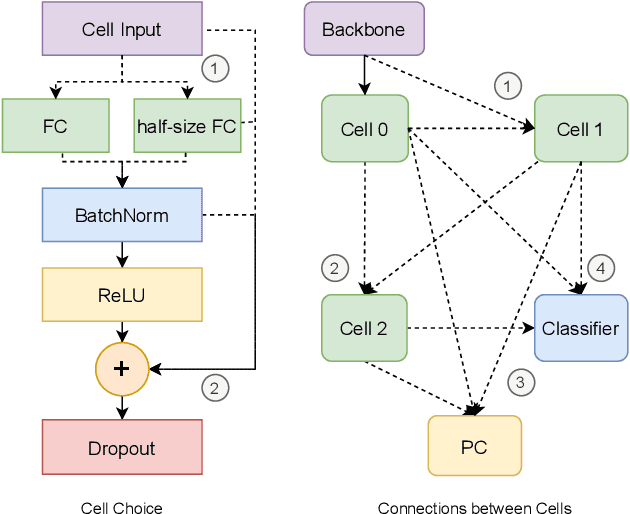
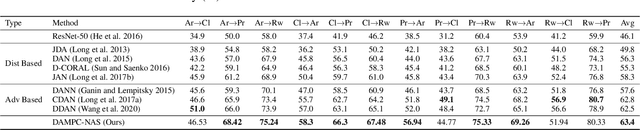
In Domain Adaptation (DA), where the feature distributions of the source and target domains are different, various distance-based methods have been proposed to minimize the discrepancy between the source and target domains to handle the domain shift. In this paper, we propose a new similarity function, which is called Population Correlation (PC), to measure the domain discrepancy for DA. Base on the PC function, we propose a new method called Domain Adaptation by Maximizing Population Correlation (DAMPC) to learn a domain-invariant feature representation for DA. Moreover, most existing DA methods use hand-crafted bottleneck networks, which may limit the capacity and flexibility of the corresponding model. Therefore, we further propose a method called DAMPC with Neural Architecture Search (DAMPC-NAS) to search the optimal network architecture for DAMPC. Experiments on several benchmark datasets, including Office-31, Office-Home, and VisDA-2017, show that the proposed DAMPC-NAS method achieves better results than state-of-the-art DA methods.