 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantitative Video World Model Evaluation for Geometric-Consistency
May 14, 2026Generative video models are increasingly studied as implicit world models, yet evaluating whether they produce physically plausible 3D structure and motion remains challenging. Most existing video evaluation pipelines rely heavily on human judgment or learned graders, which can be subjective and weakly diagnostic for geometric failures. We introduce PDI-Bench (Perspective Distortion Index), a quantitative framework for auditing geometric coherence in generated videos. Given a generated clip, we obtain object-centric observations via segmentation and point tracking (e.g., SAM 2, MegaSaM, and CoTracker3), lift them to 3D world-space coordinates via monocular reconstruction, and compute a set of projective-geometry residuals capturing three failure dimensions: scale-depth alignment, 3D motion consistency, and 3D structural rigidity. To support systematic evaluation, we build PDI-Dataset, covering diverse scenarios designed to stress these geometric constraints. Across state-of-the-art video generators, PDI reveals consistent geometry-specific failure modes that are not captured by common perceptual metrics, and provides a diagnostic signal for progress toward physically grounded video generation and physical world model. Our code and dataset can be found at https://pdi-bench.github.io/.
Adaptive Confidence-Wise Loss for Improved Lens Structure Segmentation in AS-OCT
Aug 12, 2025Precise lens structure segmentation is essential for the design of intraocular lenses (IOLs) in cataract surgery. Existing deep segmentation networks typically weight all pixels equally under cross-entropy (CE) loss, overlooking the fact that sub-regions of lens structures are inhomogeneous (e.g., some regions perform better than others) and that boundary regions often suffer from poor segmentation calibration at the pixel level. Clinically, experts annotate different sub-regions of lens structures with varying confidence levels, considering factors such as sub-region proportions, ambiguous boundaries, and lens structure shapes. Motivated by this observation, we propose an Adaptive Confidence-Wise (ACW) loss to group each lens structure sub-region into different confidence sub-regions via a confidence threshold from the unique region aspect, aiming to exploit the potential of expert annotation confidence prior. Specifically, ACW clusters each target region into low-confidence and high-confidence groups and then applies a region-weighted loss to reweigh each confidence group. Moreover, we design an adaptive confidence threshold optimization algorithm to adjust the confidence threshold of ACW dynamically. Additionally, to better quantify the miscalibration errors in boundary region segmentation, we propose a new metric, termed Boundary Expected Calibration Error (BECE). Extensive experiments on a clinical lens structure AS-OCT dataset and other multi-structure datasets demonstrate that our ACW significantly outperforms competitive segmentation loss methods across different deep segmentation networks (e.g., MedSAM). Notably, our method surpasses CE with 6.13% IoU gain, 4.33% DSC increase, and 4.79% BECE reduction in lens structure segmentation under U-Net. The code of this paper is available at https://github.com/XiaoLing12138/Adaptive-Confidence-Wise-Loss.
CGKN: A Deep Learning Framework for Modeling Complex Dynamical Systems and Efficient Data Assimilation
Oct 26, 2024Deep learning is widely used to predict complex dynamical systems in many scientific and engineering areas. However, the black-box nature of these deep learning models presents significant challenges for carrying out simultaneous data assimilation (DA), which is a crucial technique for state estimation, model identification, and reconstructing missing data. Integrating ensemble-based DA methods with nonlinear deep learning models is computationally expensive and may suffer from large sampling errors. To address these challenges, we introduce a deep learning framework designed to simultaneously provide accurate forecasts and efficient DA. It is named Conditional Gaussian Koopman Network (CGKN), which transforms general nonlinear systems into nonlinear neural differential equations with conditional Gaussian structures. CGKN aims to retain essential nonlinear components while applying systematic and minimal simplifications to facilitate the development of analytic formulae for nonlinear DA. This allows for seamless integration of DA performance into the deep learning training process, eliminating the need for empirical tuning as required in ensemble methods. CGKN compensates for structural simplifications by lifting the dimension of the system, which is motivated by Koopman theory. Nevertheless, CGKN exploits special nonlinear dynamics within the lifted space. This enables the model to capture extreme events and strong non-Gaussian features in joint and marginal distributions with appropriate uncertainty quantification. We demonstrate the effectiveness of CGKN for both prediction and DA on three strongly nonlinear and non-Gaussian turbulent systems: the projected stochastic Burgers--Sivashinsky equation, the Lorenz 96 system, and the El Ni\~no-Southern Oscillation. The results justify the robustness and computational efficiency of CGKN.
A Causality-Based Learning Approach for Discovering the Underlying Dynamics of Complex Systems from Partial Observations with Stochastic Parameterization
Aug 19, 2022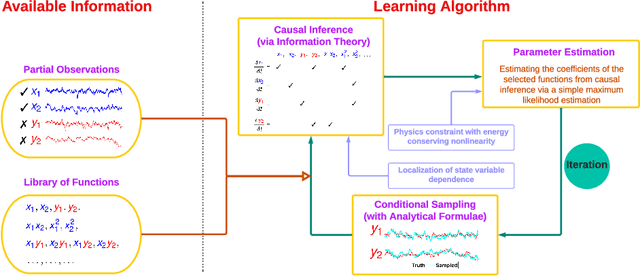
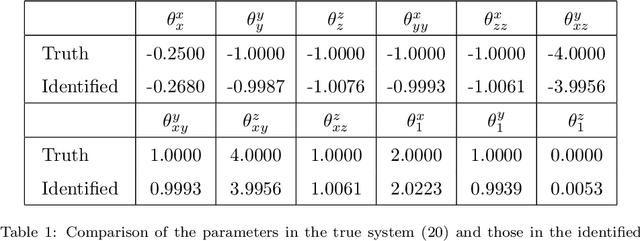
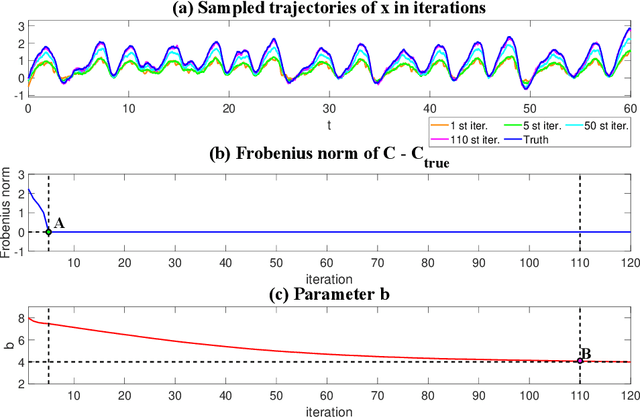
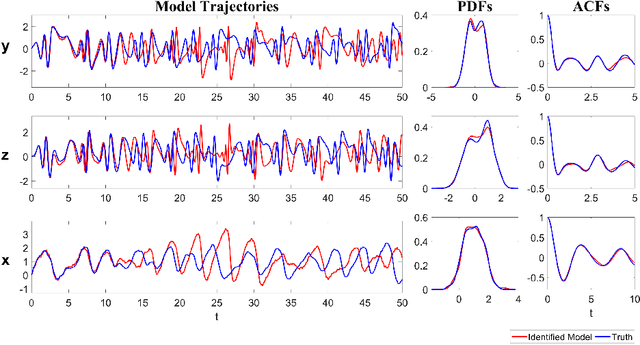
Discovering the underlying dynamics of complex systems from data is an important practical topic. Constrained optimization algorithms are widely utilized and lead to many successes. Yet, such purely data-driven methods may bring about incorrect physics in the presence of random noise and cannot easily handle the situation with incomplete data. In this paper, a new iterative learning algorithm for complex turbulent systems with partial observations is developed that alternates between identifying model structures, recovering unobserved variables, and estimating parameters. First, a causality-based learning approach is utilized for the sparse identification of model structures, which takes into account certain physics knowledge that is pre-learned from data. It has unique advantages in coping with indirect coupling between features and is robust to the stochastic noise. A practical algorithm is designed to facilitate the causal inference for high-dimensional systems. Next, a systematic nonlinear stochastic parameterization is built to characterize the time evolution of the unobserved variables. Closed analytic formula via an efficient nonlinear data assimilation is exploited to sample the trajectories of the unobserved variables, which are then treated as synthetic observations to advance a rapid parameter estimation. Furthermore, the localization of the state variable dependence and the physics constraints are incorporated into the learning procedure, which mitigate the curse of dimensionality and prevent the finite time blow-up issue. Numerical experiments show that the new algorithm succeeds in identifying the model structure and providing suitable stochastic parameterizations for many complex nonlinear systems with chaotic dynamics, spatiotemporal multiscale structures, intermittency, and extreme events.