 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextAtari: 100K Frames Game Playing with Language Agents
Jun 04, 2025We present TextAtari, a benchmark for evaluating language agents on very long-horizon decision-making tasks spanning up to 100,000 steps. By translating the visual state representations of classic Atari games into rich textual descriptions, TextAtari creates a challenging test bed that bridges sequential decision-making with natural language processing. The benchmark includes nearly 100 distinct tasks with varying complexity, action spaces, and planning horizons, all rendered as text through an unsupervised representation learning framework (AtariARI). We evaluate three open-source large language models (Qwen2.5-7B, Gemma-7B, and Llama3.1-8B) across three agent frameworks (zero-shot, few-shot chain-of-thought, and reflection reasoning) to assess how different forms of prior knowledge affect performance on these long-horizon challenges. Four scenarios-Basic, Obscured, Manual Augmentation, and Reference-based-investigate the impact of semantic understanding, instruction comprehension, and expert demonstrations on agent decision-making. Our results reveal significant performance gaps between language agents and human players in extensive planning tasks, highlighting challenges in sequential reasoning, state tracking, and strategic planning across tens of thousands of steps. TextAtari provides standardized evaluation protocols, baseline implementations, and a framework for advancing research at the intersection of language models and planning.
Where Paths Collide: A Comprehensive Survey of Classic and Learning-Based Multi-Agent Pathfinding
May 25, 2025Multi-Agent Path Finding (MAPF) is a fundamental problem in artificial intelligence and robotics, requiring the computation of collision-free paths for multiple agents navigating from their start locations to designated goals. As autonomous systems become increasingly prevalent in warehouses, urban transportation, and other complex environments, MAPF has evolved from a theoretical challenge to a critical enabler of real-world multi-robot coordination. This comprehensive survey bridges the long-standing divide between classical algorithmic approaches and emerging learning-based methods in MAPF research. We present a unified framework that encompasses search-based methods (including Conflict-Based Search, Priority-Based Search, and Large Neighborhood Search), compilation-based approaches (SAT, SMT, CSP, ASP, and MIP formulations), and data-driven techniques (reinforcement learning, supervised learning, and hybrid strategies). Through systematic analysis of experimental practices across 200+ papers, we uncover significant disparities in evaluation methodologies, with classical methods typically tested on larger-scale instances (up to 200 by 200 grids with 1000+ agents) compared to learning-based approaches (predominantly 10-100 agents). We provide a comprehensive taxonomy of evaluation metrics, environment types, and baseline selections, highlighting the need for standardized benchmarking protocols. Finally, we outline promising future directions including mixed-motive MAPF with game-theoretic considerations, language-grounded planning with large language models, and neural solver architectures that combine the rigor of classical methods with the flexibility of deep learning. This survey serves as both a comprehensive reference for researchers and a practical guide for deploying MAPF solutions in increasingly complex real-world applications.
Optimization Problem Solving Can Transition to Evolutionary Agentic Workflows
May 07, 2025This position paper argues that optimization problem solving can transition from expert-dependent to evolutionary agentic workflows. Traditional optimization practices rely on human specialists for problem formulation, algorithm selection, and hyperparameter tuning, creating bottlenecks that impede industrial adoption of cutting-edge methods. We contend that an evolutionary agentic workflow, powered by foundation models and evolutionary search, can autonomously navigate the optimization space, comprising problem, formulation, algorithm, and hyperparameter spaces. Through case studies in cloud resource scheduling and ADMM parameter adaptation, we demonstrate how this approach can bridge the gap between academic innovation and industrial implementation. Our position challenges the status quo of human-centric optimization workflows and advocates for a more scalable, adaptive approach to solving real-world optimization problems.
The Fourth Monocular Depth Estimation Challenge
Apr 24, 2025
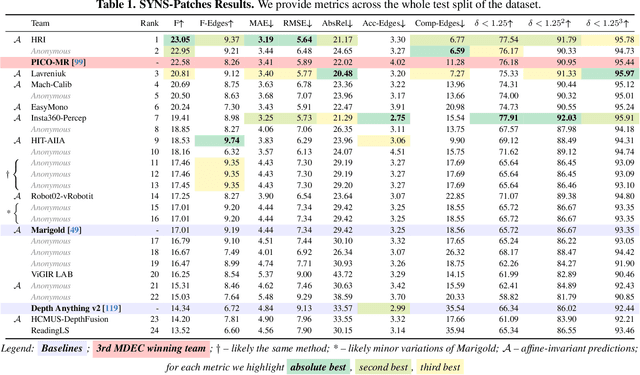
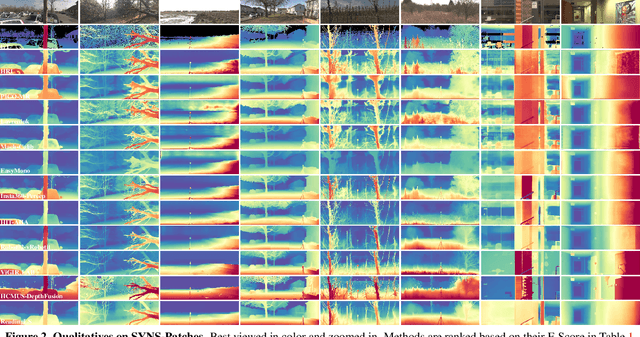
This paper presents the results of the fourth edition of the Monocular Depth Estimation Challenge (MDEC), which focuses on zero-shot generalization to the SYNS-Patches benchmark, a dataset featuring challenging environments in both natural and indoor settings. In this edition, we revised the evaluation protocol to use least-squares alignment with two degrees of freedom to support disparity and affine-invariant predictions. We also revised the baselines and included popular off-the-shelf methods: Depth Anything v2 and Marigold. The challenge received a total of 24 submissions that outperformed the baselines on the test set; 10 of these included a report describing their approach, with most leading methods relying on affine-invariant predictions. The challenge winners improved the 3D F-Score over the previous edition's best result, raising it from 22.58% to 23.05%.
Generative Multi-Agent Collaboration in Embodied AI: A Systematic Review
Feb 17, 2025Embodied multi-agent systems (EMAS) have attracted growing attention for their potential to address complex, real-world challenges in areas such as logistics and robotics. Recent advances in foundation models pave the way for generative agents capable of richer communication and adaptive problem-solving. This survey provides a systematic examination of how EMAS can benefit from these generative capabilities. We propose a taxonomy that categorizes EMAS by system architectures and embodiment modalities, emphasizing how collaboration spans both physical and virtual contexts. Central building blocks, perception, planning, communication, and feedback, are then analyzed to illustrate how generative techniques bolster system robustness and flexibility. Through concrete examples, we demonstrate the transformative effects of integrating foundation models into embodied, multi-agent frameworks. Finally, we discuss challenges and future directions, underlining the significant promise of EMAS to reshape the landscape of AI-driven collaboration.
GraphThought: Graph Combinatorial Optimization with Thought Generation
Feb 17, 2025Large language models (LLMs) have demonstrated remarkable capabilities across various domains, especially in text processing and generative tasks. Recent advancements in the reasoning capabilities of state-of-the-art LLMs, such as OpenAI-o1, have significantly broadened their applicability, particularly in complex problem-solving and logical inference. However, most existing LLMs struggle with notable limitations in handling graph combinatorial optimization (GCO) problems. To bridge this gap, we formally define the Optimal Thoughts Design (OTD) problem, including its state and action thought space. We then introduce a novel framework, GraphThought, designed to generate high-quality thought datasets for GCO problems. Leveraging these datasets, we fine-tune the Llama-3-8B-Instruct model to develop Llama-GT. Notably, despite its compact 8B-parameter architecture, Llama-GT matches the performance of state-of-the-art LLMs on the GraphArena benchmark. Experimental results show that our approach outperforms both proprietary and open-source models, even rivaling specialized models like o1-mini. This work sets a new state-of-the-art benchmark while challenging the prevailing notion that model scale is the primary driver of reasoning capability.
A Survey of Automatic Prompt Engineering: An Optimization Perspective
Feb 17, 2025The rise of foundation models has shifted focus from resource-intensive fine-tuning to prompt engineering, a paradigm that steers model behavior through input design rather than weight updates. While manual prompt engineering faces limitations in scalability, adaptability, and cross-modal alignment, automated methods, spanning foundation model (FM) based optimization, evolutionary methods, gradient-based optimization, and reinforcement learning, offer promising solutions. Existing surveys, however, remain fragmented across modalities and methodologies. This paper presents the first comprehensive survey on automated prompt engineering through a unified optimization-theoretic lens. We formalize prompt optimization as a maximization problem over discrete, continuous, and hybrid prompt spaces, systematically organizing methods by their optimization variables (instructions, soft prompts, exemplars), task-specific objectives, and computational frameworks. By bridging theoretical formulation with practical implementations across text, vision, and multimodal domains, this survey establishes a foundational framework for both researchers and practitioners, while highlighting underexplored frontiers in constrained optimization and agent-oriented prompt design.
SkyRover: A Modular Simulator for Cross-Domain Pathfinding
Feb 13, 2025Unmanned Aerial Vehicles (UAVs) and Automated Guided Vehicles (AGVs) increasingly collaborate in logistics, surveillance, inspection tasks and etc. However, existing simulators often focus on a single domain, limiting cross-domain study. This paper presents the SkyRover, a modular simulator for UAV-AGV multi-agent pathfinding (MAPF). SkyRover supports realistic agent dynamics, configurable 3D environments, and convenient APIs for external solvers and learning methods. By unifying ground and aerial operations, it facilitates cross-domain algorithm design, testing, and benchmarking. Experiments highlight SkyRover's capacity for efficient pathfinding and high-fidelity simulations in UAV-AGV coordination. Project is available at https://sites.google.com/view/mapf3d/home.
TrackDiffuser: Nearly Model-Free Bayesian Filtering with Diffusion Model
Feb 08, 2025



State estimation remains a fundamental challenge across numerous domains, from autonomous driving, aircraft tracking to quantum system control. Although Bayesian filtering has been the cornerstone solution, its classical model-based paradigm faces two major limitations: it struggles with inaccurate state space model (SSM) and requires extensive prior knowledge of noise characteristics. We present TrackDiffuser, a generative framework addressing both challenges by reformulating Bayesian filtering as a conditional diffusion model. Our approach implicitly learns system dynamics from data to mitigate the effects of inaccurate SSM, while simultaneously circumventing the need for explicit measurement models and noise priors by establishing a direct relationship between measurements and states. Through an implicit predict-and-update mechanism, TrackDiffuser preserves the interpretability advantage of traditional model-based filtering methods. Extensive experiments demonstrate that our framework substantially outperforms both classical and contemporary hybrid methods, especially in challenging non-linear scenarios involving non-Gaussian noises. Notably, TrackDiffuser exhibits remarkable robustness to SSM inaccuracies, offering a practical solution for real-world state estimation problems where perfect models and prior knowledge are unavailable.
Verbalized Bayesian Persuasion
Feb 03, 2025



Information design (ID) explores how a sender influence the optimal behavior of receivers to achieve specific objectives. While ID originates from everyday human communication, existing game-theoretic and machine learning methods often model information structures as numbers, which limits many applications to toy games. This work leverages LLMs and proposes a verbalized framework in Bayesian persuasion (BP), which extends classic BP to real-world games involving human dialogues for the first time. Specifically, we map the BP to a verbalized mediator-augmented extensive-form game, where LLMs instantiate the sender and receiver. To efficiently solve the verbalized game, we propose a generalized equilibrium-finding algorithm combining LLM and game solver. The algorithm is reinforced with techniques including verbalized commitment assumptions, verbalized obedience constraints, and information obfuscation. Numerical experiments in dialogue scenarios, such as recommendation letters, courtroom interactions, and law enforcement, validate that our framework can both reproduce theoretical results in classic BP and discover effective persuasion strategies in more complex natural language and multi-stage scenarios.