 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe SkatingVerse Workshop & Challenge: Methods and Results
May 27, 2024

The SkatingVerse Workshop & Challenge aims to encourage research in developing novel and accurate methods for human action understanding. The SkatingVerse dataset used for the SkatingVerse Challenge has been publicly released. There are two subsets in the dataset, i.e., the training subset and testing subset. The training subsets consists of 19,993 RGB video sequences, and the testing subsets consists of 8,586 RGB video sequences. Around 10 participating teams from the globe competed in the SkatingVerse Challenge. In this paper, we provide a brief summary of the SkatingVerse Workshop & Challenge including brief introductions to the top three methods. The submission leaderboard will be reopened for researchers that are interested in the human action understanding challenge. The benchmark dataset and other information can be found at: https://skatingverse.github.io/.
AdaFPP: Adapt-Focused Bi-Propagating Prototype Learning for Panoramic Activity Recognition
May 04, 2024Panoramic Activity Recognition (PAR) aims to identify multi-granularity behaviors performed by multiple persons in panoramic scenes, including individual activities, group activities, and global activities. Previous methods 1) heavily rely on manually annotated detection boxes in training and inference, hindering further practical deployment; or 2) directly employ normal detectors to detect multiple persons with varying size and spatial occlusion in panoramic scenes, blocking the performance gain of PAR. To this end, we consider learning a detector adapting varying-size occluded persons, which is optimized along with the recognition module in the all-in-one framework. Therefore, we propose a novel Adapt-Focused bi-Propagating Prototype learning (AdaFPP) framework to jointly recognize individual, group, and global activities in panoramic activity scenes by learning an adapt-focused detector and multi-granularity prototypes as the pretext tasks in an end-to-end way. Specifically, to accommodate the varying sizes and spatial occlusion of multiple persons in crowed panoramic scenes, we introduce a panoramic adapt-focuser, achieving the size-adapting detection of individuals by comprehensively selecting and performing fine-grained detections on object-dense sub-regions identified through original detections. In addition, to mitigate information loss due to inaccurate individual localizations, we introduce a bi-propagation prototyper that promotes closed-loop interaction and informative consistency across different granularities by facilitating bidirectional information propagation among the individual, group, and global levels. Extensive experiments demonstrate the significant performance of AdaFPP and emphasize its powerful applicability for PAR.
MVP-Shot: Multi-Velocity Progressive-Alignment Framework for Few-Shot Action Recognition
May 03, 2024Recent few-shot action recognition (FSAR) methods achieve promising performance by performing semantic matching on learned discriminative features. However, most FSAR methods focus on single-scale (e.g., frame-level, segment-level, \etc) feature alignment, which ignores that human actions with the same semantic may appear at different velocities. To this end, we develop a novel Multi-Velocity Progressive-alignment (MVP-Shot) framework to progressively learn and align semantic-related action features at multi-velocity levels. Concretely, a Multi-Velocity Feature Alignment (MVFA) module is designed to measure the similarity between features from support and query videos with different velocity scales and then merge all similarity scores in a residual fashion. To avoid the multiple velocity features deviating from the underlying motion semantic, our proposed Progressive Semantic-Tailored Interaction (PSTI) module injects velocity-tailored text information into the video feature via feature interaction on channel and temporal domains at different velocities. The above two modules compensate for each other to predict query categories more accurately under the few-shot settings. Experimental results show our method outperforms current state-of-the-art methods on multiple standard few-shot benchmarks (i.e., HMDB51, UCF101, Kinetics, and SSv2-small).
GPT4Ego: Unleashing the Potential of Pre-trained Models for Zero-Shot Egocentric Action Recognition
Jan 18, 2024Vision-Language Models (VLMs), pre-trained on large-scale datasets, have shown impressive performance in various visual recognition tasks. This advancement paves the way for notable performance in Zero-Shot Egocentric Action Recognition (ZS-EAR). Typically, VLMs handle ZS-EAR as a global video-text matching task, which often leads to suboptimal alignment of vision and linguistic knowledge. We propose a refined approach for ZS-EAR using VLMs, emphasizing fine-grained concept-description alignment that capitalizes on the rich semantic and contextual details in egocentric videos. In this paper, we introduce GPT4Ego, a straightforward yet remarkably potent VLM framework for ZS-EAR, designed to enhance the fine-grained alignment of concept and description between vision and language. Extensive experiments demonstrate GPT4Ego significantly outperforms existing VLMs on three large-scale egocentric video benchmarks, i.e., EPIC-KITCHENS-100 (33.2%, +9.4%), EGTEA (39.6%, +5.5%), and CharadesEgo (31.5%, +2.6%).
Attack is Good Augmentation: Towards Skeleton-Contrastive Representation Learning
Apr 08, 2023Contrastive learning, relying on effective positive and negative sample pairs, is beneficial to learn informative skeleton representations in unsupervised skeleton-based action recognition. To achieve these positive and negative pairs, existing weak/strong data augmentation methods have to randomly change the appearance of skeletons for indirectly pursuing semantic perturbations. However, such approaches have two limitations: 1) solely perturbing appearance cannot well capture the intrinsic semantic information of skeletons, and 2) randomly perturbation may change the original positive/negative pairs to soft positive/negative ones. To address the above dilemma, we start the first attempt to explore an attack-based augmentation scheme that additionally brings in direct semantic perturbation, for constructing hard positive pairs and further assisting in constructing hard negative pairs. In particular, we propose a novel Attack-Augmentation Mixing-Contrastive learning (A$^2$MC) to contrast hard positive features and hard negative features for learning more robust skeleton representations. In A$^2$MC, Attack-Augmentation (Att-Aug) is designed to collaboratively perform targeted and untargeted perturbations of skeletons via attack and augmentation respectively, for generating high-quality hard positive features. Meanwhile, Positive-Negative Mixer (PNM) is presented to mix hard positive features and negative features for generating hard negative features, which are adopted for updating the mixed memory banks. Extensive experiments on three public datasets demonstrate that A$^2$MC is competitive with the state-of-the-art methods.
Spatiotemporal Decouple-and-Squeeze Contrastive Learning for Semi-Supervised Skeleton-based Action Recognition
Feb 05, 2023Contrastive learning has been successfully leveraged to learn action representations for addressing the problem of semi-supervised skeleton-based action recognition. However, most contrastive learning-based methods only contrast global features mixing spatiotemporal information, which confuses the spatial- and temporal-specific information reflecting different semantic at the frame level and joint level. Thus, we propose a novel Spatiotemporal Decouple-and-Squeeze Contrastive Learning (SDS-CL) framework to comprehensively learn more abundant representations of skeleton-based actions by jointly contrasting spatial-squeezing features, temporal-squeezing features, and global features. In SDS-CL, we design a new Spatiotemporal-decoupling Intra-Inter Attention (SIIA) mechanism to obtain the spatiotemporal-decoupling attentive features for capturing spatiotemporal specific information by calculating spatial- and temporal-decoupling intra-attention maps among joint/motion features, as well as spatial- and temporal-decoupling inter-attention maps between joint and motion features. Moreover, we present a new Spatial-squeezing Temporal-contrasting Loss (STL), a new Temporal-squeezing Spatial-contrasting Loss (TSL), and the Global-contrasting Loss (GL) to contrast the spatial-squeezing joint and motion features at the frame level, temporal-squeezing joint and motion features at the joint level, as well as global joint and motion features at the skeleton level. Extensive experimental results on four public datasets show that the proposed SDS-CL achieves performance gains compared with other competitive methods.
Pyramid Self-attention Polymerization Learning for Semi-supervised Skeleton-based Action Recognition
Feb 05, 2023Most semi-supervised skeleton-based action recognition approaches aim to learn the skeleton action representations only at the joint level, but neglect the crucial motion characteristics at the coarser-grained body (e.g., limb, trunk) level that provide rich additional semantic information, though the number of labeled data is limited. In this work, we propose a novel Pyramid Self-attention Polymerization Learning (dubbed as PSP Learning) framework to jointly learn body-level, part-level, and joint-level action representations of joint and motion data containing abundant and complementary semantic information via contrastive learning covering coarse-to-fine granularity. Specifically, to complement semantic information from coarse to fine granularity in skeleton actions, we design a new Pyramid Polymerizing Attention (PPA) mechanism that firstly calculates the body-level attention map, part-level attention map, and joint-level attention map, as well as polymerizes these attention maps in a level-by-level way (i.e., from body level to part level, and further to joint level). Moreover, we present a new Coarse-to-fine Contrastive Loss (CCL) including body-level contrast loss, part-level contrast loss, and joint-level contrast loss to jointly measure the similarity between the body/part/joint-level contrasting features of joint and motion data. Finally, extensive experiments are conducted on the NTU RGB+D and North-Western UCLA datasets to demonstrate the competitive performance of the proposed PSP Learning in the semi-supervised skeleton-based action recognition task. The source codes of PSP Learning are publicly available at https://github.com/1xbq1/PSP-Learning.
Dilation-Erosion for Single-Frame Supervised Temporal Action Localization
Dec 13, 2022



To balance the annotation labor and the granularity of supervision, single-frame annotation has been introduced in temporal action localization. It provides a rough temporal location for an action but implicitly overstates the supervision from the annotated-frame during training, leading to the confusion between actions and backgrounds, i.e., action incompleteness and background false positives. To tackle the two challenges, in this work, we present the Snippet Classification model and the Dilation-Erosion module. In the Dilation-Erosion module, we expand the potential action segments with a loose criterion to alleviate the problem of action incompleteness and then remove the background from the potential action segments to alleviate the problem of action incompleteness. Relying on the single-frame annotation and the output of the snippet classification, the Dilation-Erosion module mines pseudo snippet-level ground-truth, hard backgrounds and evident backgrounds, which in turn further trains the Snippet Classification model. It forms a cyclic dependency. Furthermore, we propose a new embedding loss to aggregate the features of action instances with the same label and separate the features of actions from backgrounds. Experiments on THUMOS14 and ActivityNet 1.2 validate the effectiveness of the proposed method. Code has been made publicly available (https://github.com/LingJun123/single-frame-TAL).
Expansion-Squeeze-Excitation Fusion Network for Elderly Activity Recognition
Dec 21, 2021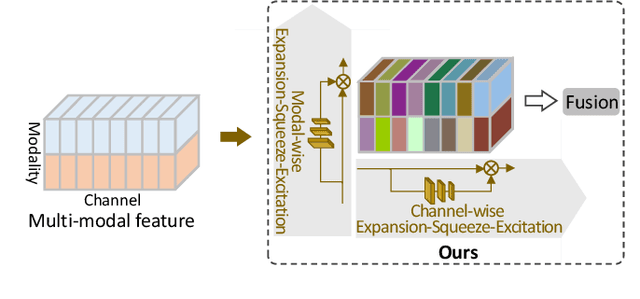

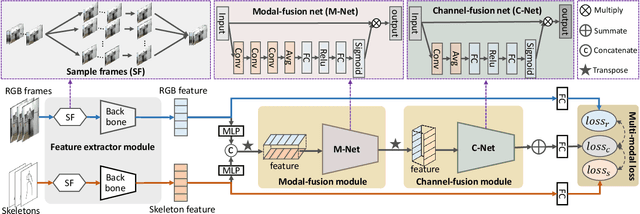

This work focuses on the task of elderly activity recognition, which is a challenging task due to the existence of individual actions and human-object interactions in elderly activities. Thus, we attempt to effectively aggregate the discriminative information of actions and interactions from both RGB videos and skeleton sequences by attentively fusing multi-modal features. Recently, some nonlinear multi-modal fusion approaches are proposed by utilizing nonlinear attention mechanism that is extended from Squeeze-and-Excitation Networks (SENet). Inspired by this, we propose a novel Expansion-Squeeze-Excitation Fusion Network (ESE-FN) to effectively address the problem of elderly activity recognition, which learns modal and channel-wise Expansion-Squeeze-Excitation (ESE) attentions for attentively fusing the multi-modal features in the modal and channel-wise ways. Furthermore, we design a new Multi-modal Loss (ML) to keep the consistency between the single-modal features and the fused multi-modal features by adding the penalty of difference between the minimum prediction losses on single modalities and the prediction loss on the fused modality. Finally, we conduct experiments on a largest-scale elderly activity dataset, i.e., ETRI-Activity3D (including 110,000+ videos, and 50+ categories), to demonstrate that the proposed ESE-FN achieves the best accuracy compared with the state-of-the-art methods. In addition, more extensive experimental results show that the proposed ESE-FN is also comparable to the other methods in terms of normal action recognition task.
Interactive Fusion of Multi-level Features for Compositional Activity Recognition
Dec 10, 2020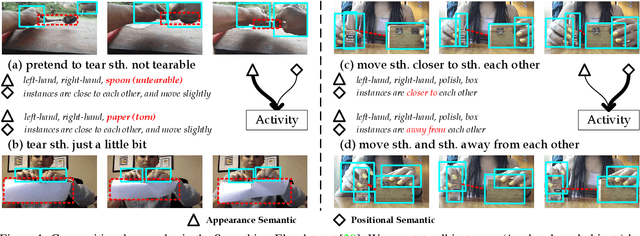
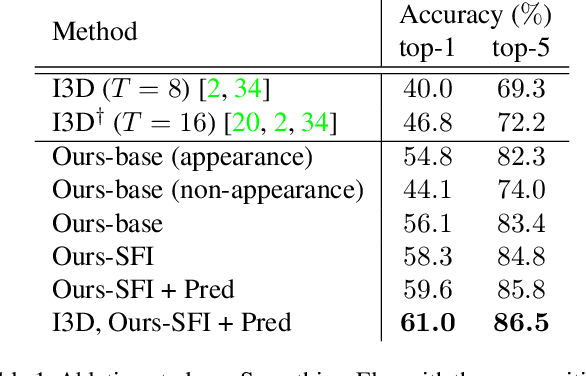
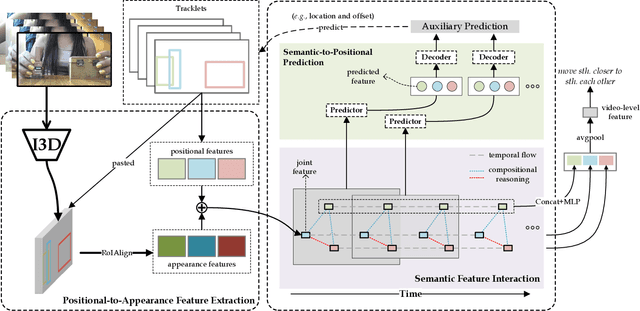
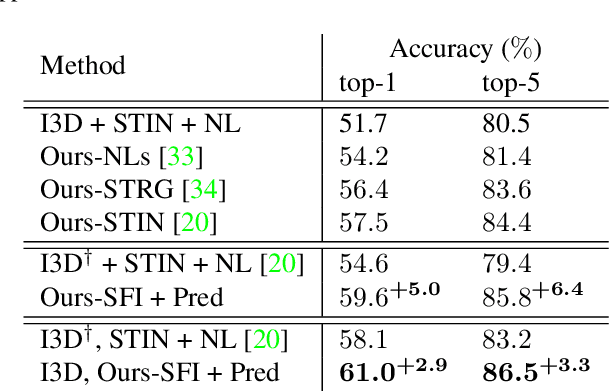
To understand a complex action, multiple sources of information, including appearance, positional, and semantic features, need to be integrated. However, these features are difficult to be fused since they often differ significantly in modality and dimensionality. In this paper, we present a novel framework that accomplishes this goal by interactive fusion, namely, projecting features across different spaces and guiding it using an auxiliary prediction task. Specifically, we implement the framework in three steps, namely, positional-to-appearance feature extraction, semantic feature interaction, and semantic-to-positional prediction. We evaluate our approach on two action recognition datasets, Something-Something and Charades. Interactive fusion achieves consistent accuracy gain beyond off-the-shelf action recognition algorithms. In particular, on Something-Else, the compositional setting of Something-Something, interactive fusion reports a remarkable gain of 2.9% in terms of top-1 accuracy.