 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDArFace: Deformation Aware Robustness for Low Quality Face Recognition
May 13, 2025



Facial recognition systems have achieved remarkable success by leveraging deep neural networks, advanced loss functions, and large-scale datasets. However, their performance often deteriorates in real-world scenarios involving low-quality facial images. Such degradations, common in surveillance footage or standoff imaging include low resolution, motion blur, and various distortions, resulting in a substantial domain gap from the high-quality data typically used during training. While existing approaches attempt to address robustness by modifying network architectures or modeling global spatial transformations, they frequently overlook local, non-rigid deformations that are inherently present in real-world settings. In this work, we introduce DArFace, a Deformation-Aware robust Face recognition framework that enhances robustness to such degradations without requiring paired high- and low-quality training samples. Our method adversarially integrates both global transformations (e.g., rotation, translation) and local elastic deformations during training to simulate realistic low-quality conditions. Moreover, we introduce a contrastive objective to enforce identity consistency across different deformed views. Extensive evaluations on low-quality benchmarks including TinyFace, IJB-B, and IJB-C demonstrate that DArFace surpasses state-of-the-art methods, with significant gains attributed to the inclusion of local deformation modeling.
The SkatingVerse Workshop & Challenge: Methods and Results
May 27, 2024

The SkatingVerse Workshop & Challenge aims to encourage research in developing novel and accurate methods for human action understanding. The SkatingVerse dataset used for the SkatingVerse Challenge has been publicly released. There are two subsets in the dataset, i.e., the training subset and testing subset. The training subsets consists of 19,993 RGB video sequences, and the testing subsets consists of 8,586 RGB video sequences. Around 10 participating teams from the globe competed in the SkatingVerse Challenge. In this paper, we provide a brief summary of the SkatingVerse Workshop & Challenge including brief introductions to the top three methods. The submission leaderboard will be reopened for researchers that are interested in the human action understanding challenge. The benchmark dataset and other information can be found at: https://skatingverse.github.io/.
The 3rd Anti-UAV Workshop & Challenge: Methods and Results
May 12, 2023


The 3rd Anti-UAV Workshop & Challenge aims to encourage research in developing novel and accurate methods for multi-scale object tracking. The Anti-UAV dataset used for the Anti-UAV Challenge has been publicly released. There are two main differences between this year's competition and the previous two. First, we have expanded the existing dataset, and for the first time, released a training set so that participants can focus on improving their models. Second, we set up two tracks for the first time, i.e., Anti-UAV Tracking and Anti-UAV Detection & Tracking. Around 76 participating teams from the globe competed in the 3rd Anti-UAV Challenge. In this paper, we provide a brief summary of the 3rd Anti-UAV Workshop & Challenge including brief introductions to the top three methods in each track. The submission leaderboard will be reopened for researchers that are interested in the Anti-UAV challenge. The benchmark dataset and other information can be found at: https://anti-uav.github.io/.
Hierarchical Explanations for Video Action Recognition
Jan 04, 2023



We propose Hierarchical ProtoPNet: an interpretable network that explains its reasoning process by considering the hierarchical relationship between classes. Different from previous methods that explain their reasoning process by dissecting the input image and finding the prototypical parts responsible for the classification, we propose to explain the reasoning process for video action classification by dissecting the input video frames on multiple levels of the class hierarchy. The explanations leverage the hierarchy to deal with uncertainty, akin to human reasoning: When we observe water and human activity, but no definitive action it can be recognized as the water sports parent class. Only after observing a person swimming can we definitively refine it to the swimming action. Experiments on ActivityNet and UCF-101 show performance improvements while providing multi-level explanations.
Wiggling Weights to Improve the Robustness of Classifiers
Nov 18, 2021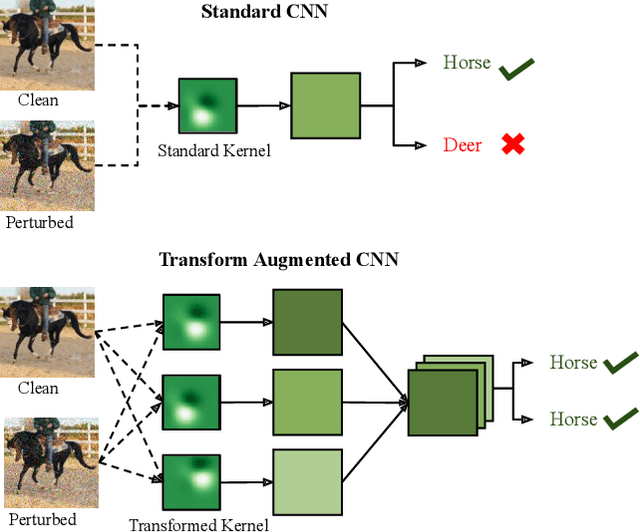
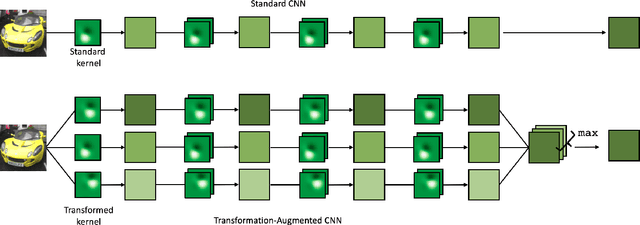

Robustness against unwanted perturbations is an important aspect of deploying neural network classifiers in the real world. Common natural perturbations include noise, saturation, occlusion, viewpoint changes, and blur deformations. All of them can be modelled by the newly proposed transform-augmented convolutional networks. While many approaches for robustness train the network by providing augmented data to the network, we aim to integrate perturbations in the network architecture to achieve improved and more general robustness. To demonstrate that wiggling the weights consistently improves classification, we choose a standard network and modify it to a transform-augmented network. On perturbed CIFAR-10 images, the modified network delivers a better performance than the original network. For the much smaller STL-10 dataset, in addition to delivering better general robustness, wiggling even improves the classification of unperturbed, clean images substantially. We conclude that wiggled transform-augmented networks acquire good robustness even for perturbations not seen during training.
Built-in Elastic Transformations for Improved Robustness
Jul 20, 2021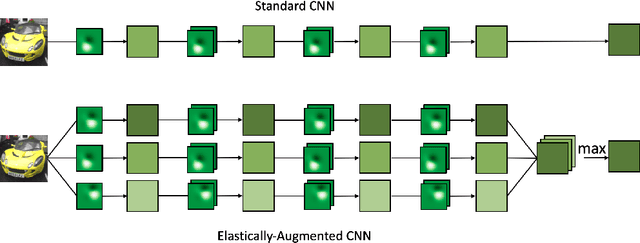
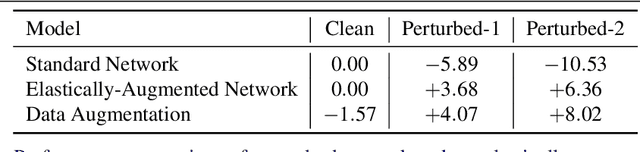
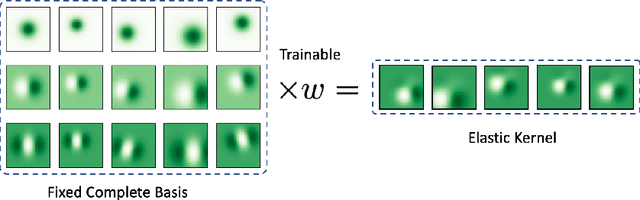
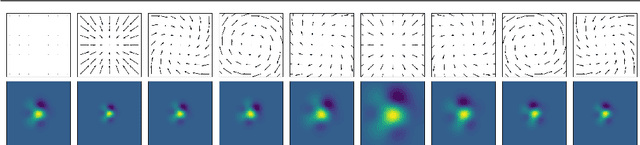
We focus on building robustness in the convolutions of neural visual classifiers, especially against natural perturbations like elastic deformations, occlusions and Gaussian noise. Existing CNNs show outstanding performance on clean images, but fail to tackle naturally occurring perturbations. In this paper, we start from elastic perturbations, which approximate (local) view-point changes of the object. We present elastically-augmented convolutions (EAConv) by parameterizing filters as a combination of fixed elastically-perturbed bases functions and trainable weights for the purpose of integrating unseen viewpoints in the CNN. We show on CIFAR-10 and STL-10 datasets that the general robustness of our method on unseen occlusion and Gaussian perturbations improves, while even improving the performance on clean images slightly without performing any data augmentation.
Natural Perturbed Training for General Robustness of Neural Network Classifiers
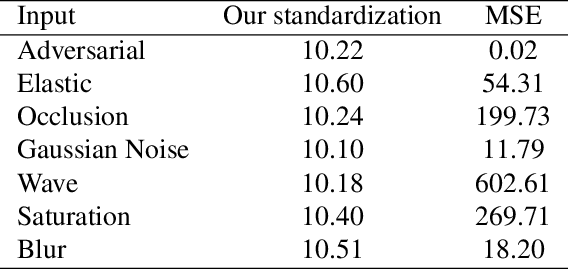
Mar 21, 2021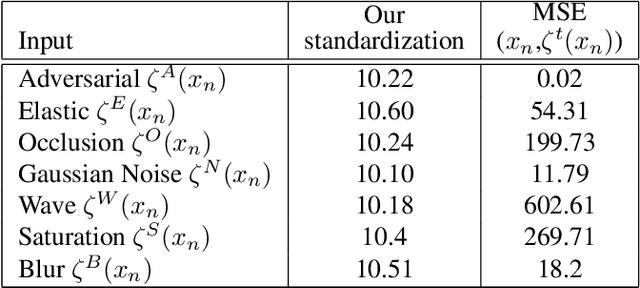
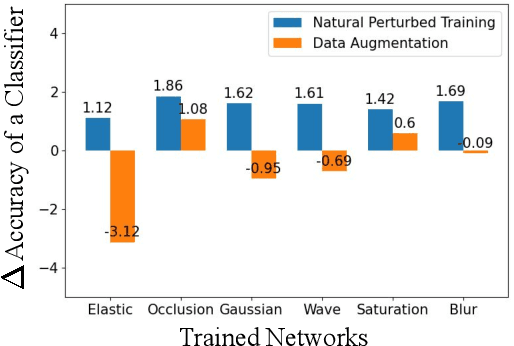

We focus on the robustness of neural networks for classification. To permit a fair comparison between methods to achieve robustness, we first introduce a standard based on the mensuration of a classifier's degradation. Then, we propose natural perturbed training to robustify the network. Natural perturbations will be encountered in practice: the difference of two images of the same object may be approximated by an elastic deformation (when they have slightly different viewing angles), by occlusions (when they hide differently behind objects), or by saturation, Gaussian noise etc. Training some fraction of the epochs on random versions of such variations will help the classifier to learn better. We conduct extensive experiments on six datasets of varying sizes and granularity. Natural perturbed learning show better and much faster performance than adversarial training on clean, adversarial as well as natural perturbed images. It even improves general robustness on perturbations not seen during the training. For Cifar-10 and STL-10 natural perturbed training even improves the accuracy for clean data and reaches the state of the art performance. Ablation studies verify the effectiveness of natural perturbed training.
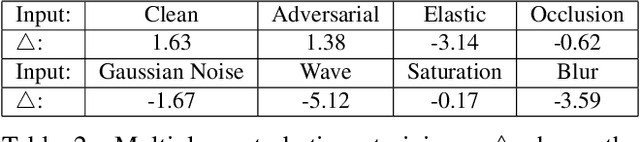
Adversarial and Natural Perturbations for General Robustness
Oct 03, 2020
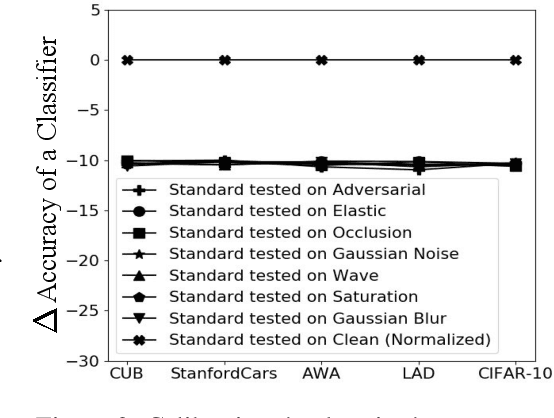
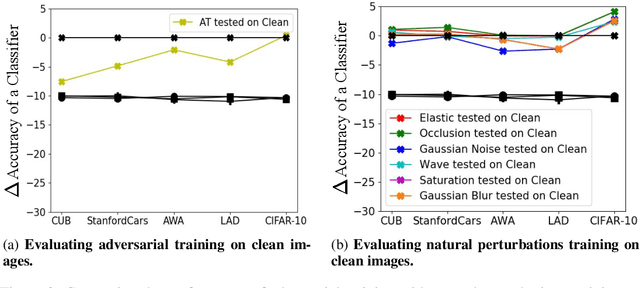
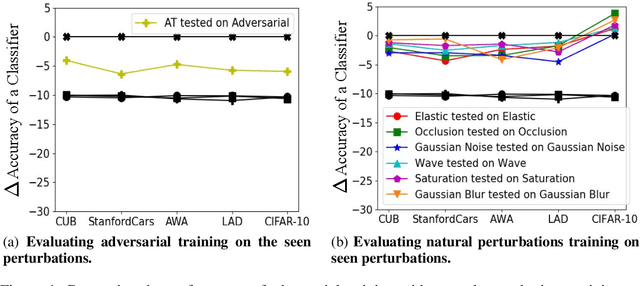
In this paper we aim to explore the general robustness of neural network classifiers by utilizing adversarial as well as natural perturbations. Different from previous works which mainly focus on studying the robustness of neural networks against adversarial perturbations, we also evaluate their robustness on natural perturbations before and after robustification. After standardizing the comparison between adversarial and natural perturbations, we demonstrate that although adversarial training improves the performance of the networks against adversarial perturbations, it leads to drop in the performance for naturally perturbed samples besides clean samples. In contrast, natural perturbations like elastic deformations, occlusions and wave does not only improve the performance against natural perturbations, but also lead to improvement in the performance for the adversarial perturbations. Additionally they do not drop the accuracy on the clean images.
Explaining with Counter Visual Attributes and Examples
Jan 27, 2020
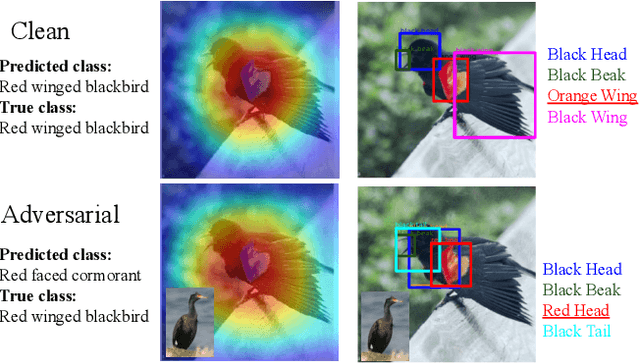

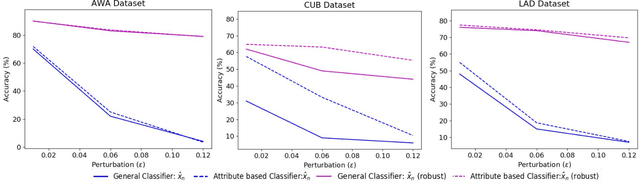
In this paper, we aim to explain the decisions of neural networks by utilizing multimodal information. That is counter-intuitive attributes and counter visual examples which appear when perturbed samples are introduced. Different from previous work on interpreting decisions using saliency maps, text, or visual patches we propose to use attributes and counter-attributes, and examples and counter-examples as part of the visual explanations. When humans explain visual decisions they tend to do so by providing attributes and examples. Hence, inspired by the way of human explanations in this paper we provide attribute-based and example-based explanations. Moreover, humans also tend to explain their visual decisions by adding counter-attributes and counter-examples to explain what is not seen. We introduce directed perturbations in the examples to observe which attribute values change when classifying the examples into the counter classes. This delivers intuitive counter-attributes and counter-examples. Our experiments with both coarse and fine-grained datasets show that attributes provide discriminating and human-understandable intuitive and counter-intuitive explanations.
Understanding Misclassifications by Attributes
Oct 15, 2019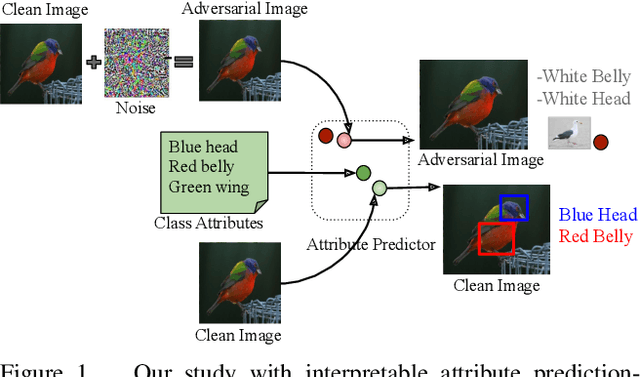

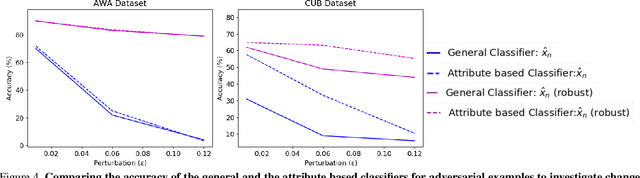
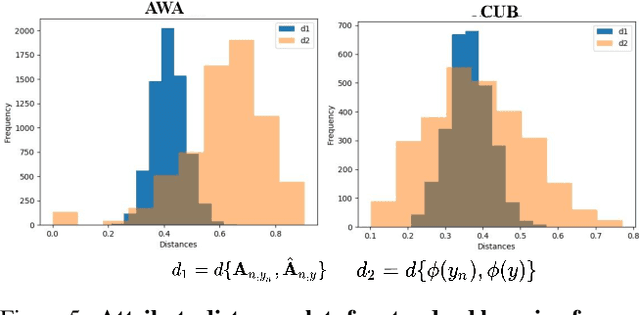
In this paper, we aim to understand and explain the decisions of deep neural networks by studying the behavior of predicted attributes when adversarial examples are introduced. We study the changes in attributes for clean as well as adversarial images in both standard and adversarially robust networks. We propose a metric to quantify the robustness of an adversarially robust network against adversarial attacks. In a standard network, attributes predicted for adversarial images are consistent with the wrong class, while attributes predicted for the clean images are consistent with the true class. In an adversarially robust network, the attributes predicted for adversarial images classified correctly are consistent with the true class. Finally, we show that the ability to robustify a network varies for different datasets. For the fine grained dataset, it is higher as compared to the coarse-grained dataset. Additionally, the ability to robustify a network increases with the increase in adversarial noise.