 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePairReranker: Pairwise Reranking for Natural Language Generation
Dec 20, 2022Pre-trained language models have been successful in natural language generation (NLG) tasks. While various decoding methods have been employed, they often produce suboptimal results. We first present an empirical analysis of three NLG tasks: summarization, machine translation, and constrained text generation. We found that selecting the best output from the results of multiple decoding methods can significantly improve performance. To further improve reranking for NLG tasks, we proposed a novel method, \textsc{PairReranker}, which uses a single encoder and a pairwise loss function to jointly encode a source input and a pair of candidates and compare them. Experiments on three NLG tasks demonstrated the effectiveness and flexibility of \textsc{PairReranker}, showing strong results, compared with previous baselines. In addition, our \textsc{PairReranker} can generalize to significantly improve GPT-3 (text-davinci-003) results (e.g., 24.55\% on CommonGen and 11.35\% on WMT18 zh-en), even though our rerankers are not trained with any GPT-3 candidates.
Dataless Knowledge Fusion by Merging Weights of Language Models
Dec 19, 2022



Fine-tuning pre-trained language models has become the prevalent paradigm for building downstream NLP models. Oftentimes fine-tuned models are readily available but their training data is not, due to data privacy or intellectual property concerns. This creates a barrier to fusing knowledge across individual models to yield a better single model. In this paper, we study the problem of merging individual models built on different training data sets to obtain a single model that performs well both across all data set domains and can generalize on out-of-domain data. We propose a dataless knowledge fusion method that merges models in their parameter space, guided by weights that minimize prediction differences between the merged model and the individual models. Over a battery of evaluation settings, we show that the proposed method significantly outperforms baselines such as Fisher-weighted averaging or model ensembling. Further, we find that our method is a promising alternative to multi-task learning that can preserve or sometimes improve over the individual models without access to the training data. Finally, model merging is more efficient than training a multi-task model, thus making it applicable to a wider set of scenarios.
APOLLO: A Simple Approach for Adaptive Pretraining of Language Models for Logical Reasoning
Dec 19, 2022



Logical reasoning of text is an important ability that requires understanding the information present in the text, their interconnections, and then reasoning through them to infer new conclusions. Prior works on improving the logical reasoning ability of language models require complex processing of training data (e.g., aligning symbolic knowledge to text), yielding task-specific data augmentation solutions that restrict the learning of general logical reasoning skills. In this work, we propose APOLLO, an adaptively pretrained language model that has improved logical reasoning abilities. We select a subset of Wikipedia, based on a set of logical inference keywords, for continued pretraining of a language model. We use two self-supervised loss functions: a modified masked language modeling loss where only specific parts-of-speech words, that would likely require more reasoning than basic language understanding, are masked, and a sentence-level classification loss that teaches the model to distinguish between entailment and contradiction types of sentences. The proposed training paradigm is both simple and independent of task formats. We demonstrate the effectiveness of APOLLO by comparing it with prior baselines on two logical reasoning datasets. APOLLO performs comparably on ReClor and outperforms baselines on LogiQA.
KNIFE: Knowledge Distillation with Free-Text Rationales
Dec 19, 2022Free-text rationales (FTRs) follow how humans communicate by explaining reasoning processes via natural language. A number of recent works have studied how to improve language model (LM) generalization by using FTRs to teach LMs the correct reasoning processes behind correct task outputs. These prior works aim to learn from FTRs by appending them to the LM input or target output, but this may introduce an input distribution shift or conflict with the task objective, respectively. We propose KNIFE, which distills FTR knowledge from an FTR-augmented teacher LM (takes both task input and FTR) to a student LM (takes only task input), which is used for inference. Crucially, the teacher LM's forward computation has a bottleneck stage in which all of its FTR states are masked out, which pushes knowledge from the FTR states into the task input/output states. Then, FTR knowledge is distilled to the student LM by training its task input/output states to align with the teacher LM's. On two question answering datasets, we show that KNIFE significantly outperforms existing FTR learning methods, in both fully-supervised and low-resource settings.
CoNAL: Anticipating Outliers with Large Language Models
Nov 28, 2022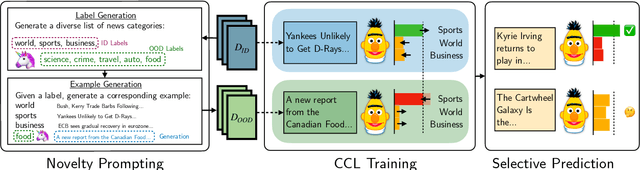
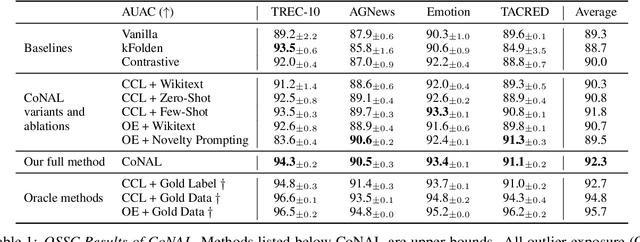

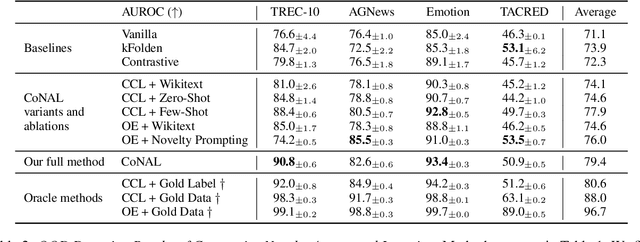
In many task settings, text classification models are likely to encounter examples from novel classes on which they cannot predict correctly. Selective prediction, in which models abstain on low-confidence examples, provides a possible solution, but existing models are often overly confident on OOD examples. To remedy this overconfidence, we introduce Contrastive Novelty-Augmented Learning (CoNAL), a two-step method that generates OOD examples representative of novel classes, then trains to decrease confidence on them. First, we generate OOD examples by prompting a large language model twice: we prompt it to enumerate relevant novel labels, then generate examples from each novel class matching the task format. Second, we train our classifier with a novel contrastive objective that encourages lower confidence on generated OOD examples than training examples. When trained with CoNAL, classifiers improve in their ability to detect and abstain on OOD examples over prior methods by an average of 2.3% AUAC and 5.5% AUROC across 4 NLP datasets, with no cost to in-distribution accuracy.
Reflect, Not Reflex: Inference-Based Common Ground Improves Dialogue Response Quality
Nov 16, 2022Human communication relies on common ground (CG), the mutual knowledge and beliefs shared by participants, to produce coherent and interesting conversations. In this paper, we demonstrate that current response generation (RG) models produce generic and dull responses in dialogues because they act reflexively, failing to explicitly model CG, both due to the lack of CG in training data and the standard RG training procedure. We introduce Reflect, a dataset that annotates dialogues with explicit CG (materialized as inferences approximating shared knowledge and beliefs) and solicits 9k diverse human-generated responses each following one common ground. Using Reflect, we showcase the limitations of current dialogue data and RG models: less than half of the responses in current data are rated as high quality (sensible, specific, and interesting) and models trained using this data have even lower quality, while most Reflect responses are judged high quality. Next, we analyze whether CG can help models produce better-quality responses by using Reflect CG to guide RG models. Surprisingly, we find that simply prompting GPT3 to "think" about CG generates 30% more quality responses, showing promising benefits to integrating CG into the RG process.
PINTO: Faithful Language Reasoning Using Prompt-Generated Rationales
Nov 03, 2022Neural language models (LMs) have achieved impressive results on various language-based reasoning tasks by utilizing latent knowledge encoded in their own pretrained parameters. To make this reasoning process more explicit, recent works retrieve a rationalizing LM's internal knowledge by training or prompting it to generate free-text rationales, which can be used to guide task predictions made by either the same LM or a separate reasoning LM. However, rationalizing LMs require expensive rationale annotation and/or computation, without any assurance that their generated rationales improve LM task performance or faithfully reflect LM decision-making. In this paper, we propose PINTO, an LM pipeline that rationalizes via prompt-based learning, and learns to faithfully reason over rationales via counterfactual regularization. First, PINTO maps out a suitable reasoning process for the task input by prompting a frozen rationalizing LM to generate a free-text rationale. Second, PINTO's reasoning LM is fine-tuned to solve the task using the generated rationale as context, while regularized to output less confident predictions when the rationale is perturbed. Across four datasets, we show that PINTO significantly improves the generalization ability of the reasoning LM, yielding higher performance on both in-distribution and out-of-distribution test sets. Also, we find that PINTO's rationales are more faithful to its task predictions than those generated by competitive baselines.
XMD: An End-to-End Framework for Interactive Explanation-Based Debugging of NLP Models
Oct 30, 2022NLP models are susceptible to learning spurious biases (i.e., bugs) that work on some datasets but do not properly reflect the underlying task. Explanation-based model debugging aims to resolve spurious biases by showing human users explanations of model behavior, asking users to give feedback on the behavior, then using the feedback to update the model. While existing model debugging methods have shown promise, their prototype-level implementations provide limited practical utility. Thus, we propose XMD: the first open-source, end-to-end framework for explanation-based model debugging. Given task- or instance-level explanations, users can flexibly provide various forms of feedback via an intuitive, web-based UI. After receiving user feedback, XMD automatically updates the model in real time, by regularizing the model so that its explanations align with the user feedback. The new model can then be easily deployed into real-world applications via Hugging Face. Using XMD, we can improve the model's OOD performance on text classification tasks by up to 18%.
REV: Information-Theoretic Evaluation of Free-Text Rationales
Oct 10, 2022

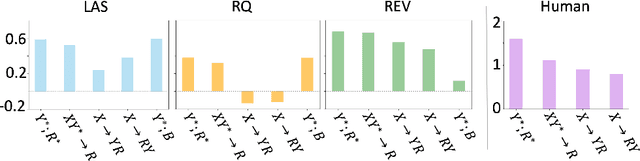
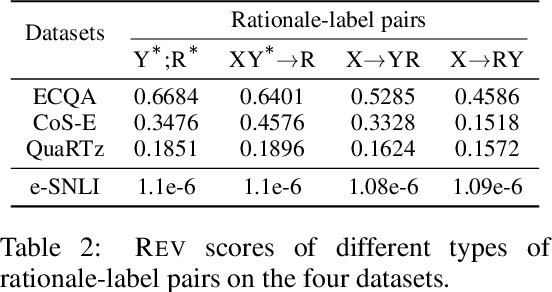
Free-text rationales are a promising step towards explainable AI, yet their evaluation remains an open research problem. While existing metrics have mostly focused on measuring the direct association between the rationale and a given label, we argue that an ideal metric should also be able to focus on the new information uniquely provided in the rationale that is otherwise not provided in the input or the label. We investigate this research problem from an information-theoretic perspective using the conditional V-information. More concretely, we propose a metric called REV (Rationale Evaluation with conditional V-information), that can quantify the new information in a rationale supporting a given label beyond the information already available in the input or the label. Experiments on reasoning tasks across four benchmarks, including few-shot prompting with GPT-3, demonstrate the effectiveness of REV in evaluating different types of rationale-label pairs, compared to existing metrics. Through several quantitative comparisons, we demonstrate the capability of REV in providing more sensitive measurements of new information in free-text rationales with respect to a label. Furthermore, REV is consistent with human judgments on rationale evaluations. Overall, when used alongside traditional performance metrics, REV provides deeper insights into a models' reasoning and prediction processes.
Curriculum Learning for Data-Efficient Vision-Language Alignment
Jul 29, 2022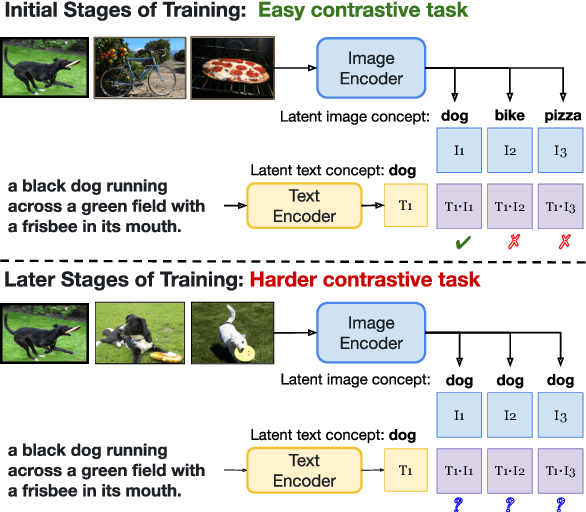
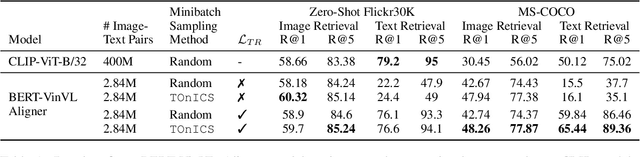

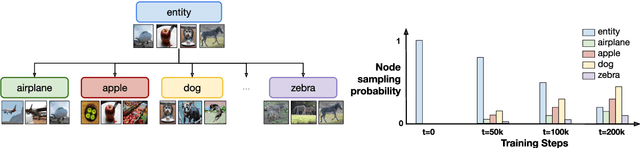
Aligning image and text encoders from scratch using contrastive learning requires large amounts of paired image-text data. We alleviate this need by aligning individually pre-trained language and vision representation models using a much smaller amount of paired data, augmented with a curriculum learning algorithm to learn fine-grained vision-language alignments. TOnICS (Training with Ontology-Informed Contrastive Sampling) initially samples minibatches whose image-text pairs contain a wide variety of objects to learn object-level alignment, and progressively samples minibatches where all image-text pairs contain the same object to learn finer-grained contextual alignment. Aligning pre-trained BERT and VinVL models to each other using TOnICS outperforms CLIP on downstream zero-shot image retrieval while using less than 1% as much training data.