 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHadaptive-Net: Efficient Vision Models via Adaptive Cross-Hadamard Synergy
May 28, 2025Recent studies have revealed the immense potential of Hadamard product in enhancing network representational capacity and dimensional compression. However, despite its theoretical promise, this technique has not been systematically explored or effectively applied in practice, leaving its full capabilities underdeveloped. In this work, we first analyze and identify the advantages of Hadamard product over standard convolutional operations in cross-channel interaction and channel expansion. Building upon these insights, we propose a computationally efficient module: Adaptive Cross-Hadamard (ACH), which leverages adaptive cross-channel Hadamard products for high-dimensional channel expansion. Furthermore, we introduce Hadaptive-Net (Hadamard Adaptive Network), a lightweight network backbone for visual tasks, which is demonstrated through experiments that it achieves an unprecedented balance between inference speed and accuracy through our proposed module.
CogniBench: A Legal-inspired Framework and Dataset for Assessing Cognitive Faithfulness of Large Language Models
May 28, 2025Faithfulness hallucination are claims generated by a Large Language Model (LLM) not supported by contexts provided to the LLM. Lacking assessment standard, existing benchmarks only contain "factual statements" that rephrase source materials without marking "cognitive statements" that make inference from the given context, making the consistency evaluation and optimization of cognitive statements difficult. Inspired by how an evidence is assessed in the legislative domain, we design a rigorous framework to assess different levels of faithfulness of cognitive statements and create a benchmark dataset where we reveal insightful statistics. We design an annotation pipeline to create larger benchmarks for different LLMs automatically, and the resulting larger-scale CogniBench-L dataset can be used to train accurate cognitive hallucination detection model. We release our model and dataset at: https://github.com/FUTUREEEEEE/CogniBench
3DGS Compression with Sparsity-guided Hierarchical Transform Coding
May 28, 20253D Gaussian Splatting (3DGS) has gained popularity for its fast and high-quality rendering, but it has a very large memory footprint incurring high transmission and storage overhead. Recently, some neural compression methods, such as Scaffold-GS, were proposed for 3DGS but they did not adopt the approach of end-to-end optimized analysis-synthesis transforms which has been proven highly effective in neural signal compression. Without an appropriate analysis transform, signal correlations cannot be removed by sparse representation. Without such transforms the only way to remove signal redundancies is through entropy coding driven by a complex and expensive context modeling, which results in slower speed and suboptimal rate-distortion (R-D) performance. To overcome this weakness, we propose Sparsity-guided Hierarchical Transform Coding (SHTC), the first end-to-end optimized transform coding framework for 3DGS compression. SHTC jointly optimizes the 3DGS, transforms and a lightweight context model. This joint optimization enables the transform to produce representations that approach the best R-D performance possible. The SHTC framework consists of a base layer using KLT for data decorrelation, and a sparsity-coded enhancement layer that compresses the KLT residuals to refine the representation. The enhancement encoder learns a linear transform to project high-dimensional inputs into a low-dimensional space, while the decoder unfolds the Iterative Shrinkage-Thresholding Algorithm (ISTA) to reconstruct the residuals. All components are designed to be interpretable, allowing the incorporation of signal priors and fewer parameters than black-box transforms. This novel design significantly improves R-D performance with minimal additional parameters and computational overhead.
Mobile-Agent-V: A Video-Guided Approach for Effortless and Efficient Operational Knowledge Injection in Mobile Automation
May 21, 2025The exponential rise in mobile device usage necessitates streamlined automation for effective task management, yet many AI frameworks fall short due to inadequate operational expertise. While manually written knowledge can bridge this gap, it is often burdensome and inefficient. We introduce Mobile-Agent-V, an innovative framework that utilizes video as a guiding tool to effortlessly and efficiently inject operational knowledge into mobile automation processes. By deriving knowledge directly from video content, Mobile-Agent-V eliminates manual intervention, significantly reducing the effort and time required for knowledge acquisition. To rigorously evaluate this approach, we propose Mobile-Knowledge, a benchmark tailored to assess the impact of external knowledge on mobile agent performance. Our experimental findings demonstrate that Mobile-Agent-V enhances performance by 36% compared to existing methods, underscoring its effortless and efficient advantages in mobile automation.
MirrorGuard: Adaptive Defense Against Jailbreaks via Entropy-Guided Mirror Crafting
Mar 17, 2025Defending large language models (LLMs) against jailbreak attacks is crucial for ensuring their safe deployment. Existing defense strategies generally rely on predefined static criteria to differentiate between harmful and benign prompts. However, such rigid rules are incapable of accommodating the inherent complexity and dynamic nature of real jailbreak attacks. In this paper, we propose a novel concept of ``mirror'' to enable dynamic and adaptive defense. A mirror refers to a dynamically generated prompt that mirrors the syntactic structure of the input while ensuring semantic safety. The personalized discrepancies between the input prompts and their corresponding mirrors serve as the guiding principles for defense. A new defense paradigm, MirrorGuard, is further proposed to detect and calibrate risky inputs based on such mirrors. An entropy-based detection metric, Relative Input Uncertainty (RIU), is integrated into MirrorGuard to quantify the discrepancies between input prompts and mirrors. MirrorGuard is evaluated on several popular datasets, demonstrating state-of-the-art defense performance while maintaining general effectiveness.
JailBench: A Comprehensive Chinese Security Assessment Benchmark for Large Language Models
Feb 26, 2025



Large language models (LLMs) have demonstrated remarkable capabilities across various applications, highlighting the urgent need for comprehensive safety evaluations. In particular, the enhanced Chinese language proficiency of LLMs, combined with the unique characteristics and complexity of Chinese expressions, has driven the emergence of Chinese-specific benchmarks for safety assessment. However, these benchmarks generally fall short in effectively exposing LLM safety vulnerabilities. To address the gap, we introduce JailBench, the first comprehensive Chinese benchmark for evaluating deep-seated vulnerabilities in LLMs, featuring a refined hierarchical safety taxonomy tailored to the Chinese context. To improve generation efficiency, we employ a novel Automatic Jailbreak Prompt Engineer (AJPE) framework for JailBench construction, which incorporates jailbreak techniques to enhance assessing effectiveness and leverages LLMs to automatically scale up the dataset through context-learning. The proposed JailBench is extensively evaluated over 13 mainstream LLMs and achieves the highest attack success rate against ChatGPT compared to existing Chinese benchmarks, underscoring its efficacy in identifying latent vulnerabilities in LLMs, as well as illustrating the substantial room for improvement in the security and trustworthiness of LLMs within the Chinese context. Our benchmark is publicly available at https://github.com/STAIR-BUPT/JailBench.
Mobile-Agent-V: Learning Mobile Device Operation Through Video-Guided Multi-Agent Collaboration
Feb 25, 2025



The rapid increase in mobile device usage necessitates improved automation for seamless task management. However, many AI-driven frameworks struggle due to insufficient operational knowledge. Manually written knowledge helps but is labor-intensive and inefficient. To address these challenges, we introduce Mobile-Agent-V, a framework that leverages video guidance to provide rich and cost-effective operational knowledge for mobile automation. Mobile-Agent-V enhances task execution capabilities by leveraging video inputs without requiring specialized sampling or preprocessing. Mobile-Agent-V integrates a sliding window strategy and incorporates a video agent and deep-reflection agent to ensure that actions align with user instructions. Through this innovative approach, users can record task processes with guidance, enabling the system to autonomously learn and execute tasks efficiently. Experimental results show that Mobile-Agent-V achieves a 30% performance improvement compared to existing frameworks. The code will be open-sourced at https://github.com/X-PLUG/MobileAgent.
PC-Agent: A Hierarchical Multi-Agent Collaboration Framework for Complex Task Automation on PC
Feb 21, 2025In the field of MLLM-based GUI agents, compared to smartphones, the PC scenario not only features a more complex interactive environment, but also involves more intricate intra- and inter-app workflows. To address these issues, we propose a hierarchical agent framework named PC-Agent. Specifically, from the perception perspective, we devise an Active Perception Module (APM) to overcome the inadequate abilities of current MLLMs in perceiving screenshot content. From the decision-making perspective, to handle complex user instructions and interdependent subtasks more effectively, we propose a hierarchical multi-agent collaboration architecture that decomposes decision-making processes into Instruction-Subtask-Action levels. Within this architecture, three agents (i.e., Manager, Progress and Decision) are set up for instruction decomposition, progress tracking and step-by-step decision-making respectively. Additionally, a Reflection agent is adopted to enable timely bottom-up error feedback and adjustment. We also introduce a new benchmark PC-Eval with 25 real-world complex instructions. Empirical results on PC-Eval show that our PC-Agent achieves a 32% absolute improvement of task success rate over previous state-of-the-art methods. The code is available at https://github.com/X-PLUG/MobileAgent/tree/main/PC-Agent.
Qwen2.5-VL Technical Report
Feb 19, 2025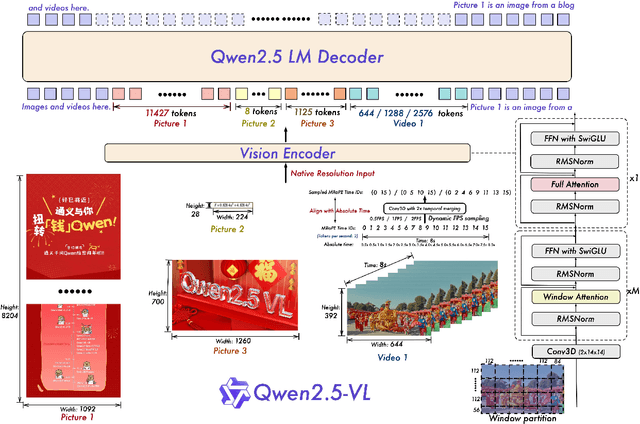
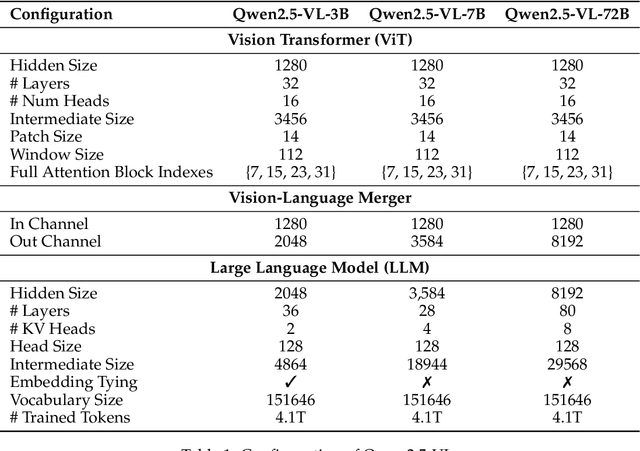
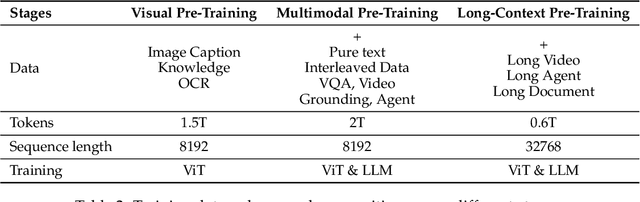
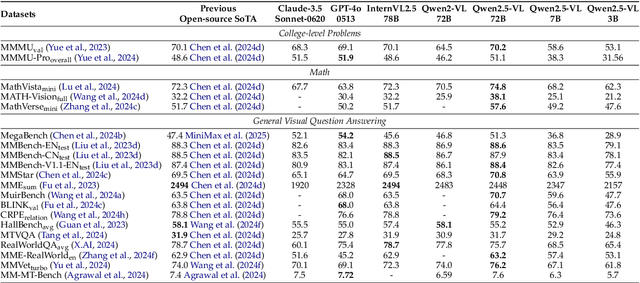
We introduce Qwen2.5-VL, the latest flagship model of Qwen vision-language series, which demonstrates significant advancements in both foundational capabilities and innovative functionalities. Qwen2.5-VL achieves a major leap forward in understanding and interacting with the world through enhanced visual recognition, precise object localization, robust document parsing, and long-video comprehension. A standout feature of Qwen2.5-VL is its ability to localize objects using bounding boxes or points accurately. It provides robust structured data extraction from invoices, forms, and tables, as well as detailed analysis of charts, diagrams, and layouts. To handle complex inputs, Qwen2.5-VL introduces dynamic resolution processing and absolute time encoding, enabling it to process images of varying sizes and videos of extended durations (up to hours) with second-level event localization. This allows the model to natively perceive spatial scales and temporal dynamics without relying on traditional normalization techniques. By training a native dynamic-resolution Vision Transformer (ViT) from scratch and incorporating Window Attention, we reduce computational overhead while maintaining native resolution. As a result, Qwen2.5-VL excels not only in static image and document understanding but also as an interactive visual agent capable of reasoning, tool usage, and task execution in real-world scenarios such as operating computers and mobile devices. Qwen2.5-VL is available in three sizes, addressing diverse use cases from edge AI to high-performance computing. The flagship Qwen2.5-VL-72B model matches state-of-the-art models like GPT-4o and Claude 3.5 Sonnet, particularly excelling in document and diagram understanding. Additionally, Qwen2.5-VL maintains robust linguistic performance, preserving the core language competencies of the Qwen2.5 LLM.
SCCD: A Session-based Dataset for Chinese Cyberbullying Detection
Jan 25, 2025



The rampant spread of cyberbullying content poses a growing threat to societal well-being. However, research on cyberbullying detection in Chinese remains underdeveloped, primarily due to the lack of comprehensive and reliable datasets. Notably, no existing Chinese dataset is specifically tailored for cyberbullying detection. Moreover, while comments play a crucial role within sessions, current session-based datasets often lack detailed, fine-grained annotations at the comment level. To address these limitations, we present a novel Chinese cyber-bullying dataset, termed SCCD, which consists of 677 session-level samples sourced from a major social media platform Weibo. Moreover, each comment within the sessions is annotated with fine-grained labels rather than conventional binary class labels. Empirically, we evaluate the performance of various baseline methods on SCCD, highlighting the challenges for effective Chinese cyberbullying detection.