 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Duality Learning for Unsupervised Visible-Infrared Person Re-Identfication
May 05, 2025
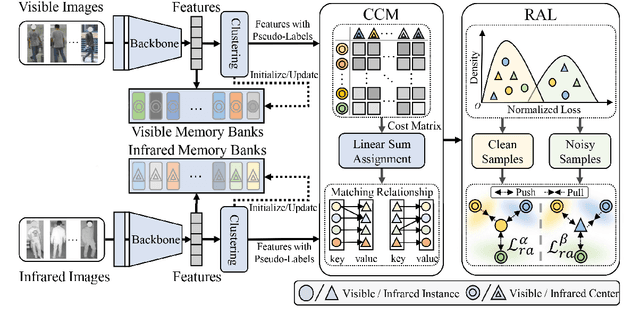


Unsupervised visible-infrared person re-identification (UVI-ReID) aims to retrieve pedestrian images across different modalities without costly annotations, but faces challenges due to the modality gap and lack of supervision. Existing methods often adopt self-training with clustering-generated pseudo-labels but implicitly assume these labels are always correct. In practice, however, this assumption fails due to inevitable pseudo-label noise, which hinders model learning. To address this, we introduce a new learning paradigm that explicitly considers Pseudo-Label Noise (PLN), characterized by three key challenges: noise overfitting, error accumulation, and noisy cluster correspondence. To this end, we propose a novel Robust Duality Learning framework (RoDE) for UVI-ReID to mitigate the effects of noisy pseudo-labels. First, to combat noise overfitting, a Robust Adaptive Learning mechanism (RAL) is proposed to dynamically emphasize clean samples while down-weighting noisy ones. Second, to alleviate error accumulation-where the model reinforces its own mistakes-RoDE employs dual distinct models that are alternately trained using pseudo-labels from each other, encouraging diversity and preventing collapse. However, this dual-model strategy introduces misalignment between clusters across models and modalities, creating noisy cluster correspondence. To resolve this, we introduce Cluster Consistency Matching (CCM), which aligns clusters across models and modalities by measuring cross-cluster similarity. Extensive experiments on three benchmarks demonstrate the effectiveness of RoDE.
LLaVA-ReID: Selective Multi-image Questioner for Interactive Person Re-Identification
Apr 15, 2025

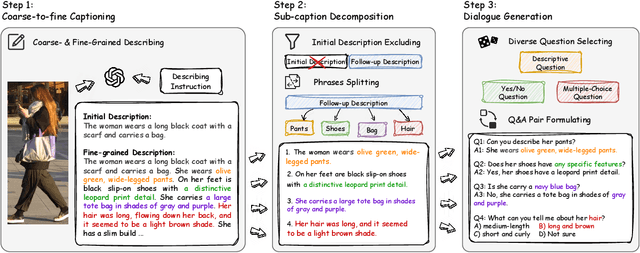

Traditional text-based person ReID assumes that person descriptions from witnesses are complete and provided at once. However, in real-world scenarios, such descriptions are often partial or vague. To address this limitation, we introduce a new task called interactive person re-identification (Inter-ReID). Inter-ReID is a dialogue-based retrieval task that iteratively refines initial descriptions through ongoing interactions with the witnesses. To facilitate the study of this new task, we construct a dialogue dataset that incorporates multiple types of questions by decomposing fine-grained attributes of individuals. We further propose LLaVA-ReID, a question model that generates targeted questions based on visual and textual contexts to elicit additional details about the target person. Leveraging a looking-forward strategy, we prioritize the most informative questions as supervision during training. Experimental results on both Inter-ReID and text-based ReID benchmarks demonstrate that LLaVA-ReID significantly outperforms baselines.
Improving Representation Learning of Complex Critical Care Data with ICU-BERT
Feb 26, 2025



The multivariate, asynchronous nature of real-world clinical data, such as that generated in Intensive Care Units (ICUs), challenges traditional AI-based decision-support systems. These often assume data regularity and feature independence and frequently rely on limited data scopes and manual feature engineering. The potential of generative AI technologies has not yet been fully exploited to analyze clinical data. We introduce ICU-BERT, a transformer-based model pre-trained on the MIMIC-IV database using a multi-task scheme to learn robust representations of complex ICU data with minimal preprocessing. ICU-BERT employs a multi-token input strategy, incorporating dense embeddings from a biomedical Large Language Model to learn a generalizable representation of complex and multivariate ICU data. With an initial evaluation of five tasks and four additional ICU datasets, ICU-BERT results indicate that ICU-BERT either compares to or surpasses current performance benchmarks by leveraging fine-tuning. By integrating structured and unstructured data, ICU-BERT advances the use of foundational models in medical informatics, offering an adaptable solution for clinical decision support across diverse applications.
High-Speed Dynamic 3D Imaging with Sensor Fusion Splatting
Feb 07, 2025



Capturing and reconstructing high-speed dynamic 3D scenes has numerous applications in computer graphics, vision, and interdisciplinary fields such as robotics, aerodynamics, and evolutionary biology. However, achieving this using a single imaging modality remains challenging. For instance, traditional RGB cameras suffer from low frame rates, limited exposure times, and narrow baselines. To address this, we propose a novel sensor fusion approach using Gaussian splatting, which combines RGB, depth, and event cameras to capture and reconstruct deforming scenes at high speeds. The key insight of our method lies in leveraging the complementary strengths of these imaging modalities: RGB cameras capture detailed color information, event cameras record rapid scene changes with microsecond resolution, and depth cameras provide 3D scene geometry. To unify the underlying scene representation across these modalities, we represent the scene using deformable 3D Gaussians. To handle rapid scene movements, we jointly optimize the 3D Gaussian parameters and their temporal deformation fields by integrating data from all three sensor modalities. This fusion enables efficient, high-quality imaging of fast and complex scenes, even under challenging conditions such as low light, narrow baselines, or rapid motion. Experiments on synthetic and real datasets captured with our prototype sensor fusion setup demonstrate that our method significantly outperforms state-of-the-art techniques, achieving noticeable improvements in both rendering fidelity and structural accuracy.
Interpretable Failure Detection with Human-Level Concepts
Feb 07, 2025



Reliable failure detection holds paramount importance in safety-critical applications. Yet, neural networks are known to produce overconfident predictions for misclassified samples. As a result, it remains a problematic matter as existing confidence score functions rely on category-level signals, the logits, to detect failures. This research introduces an innovative strategy, leveraging human-level concepts for a dual purpose: to reliably detect when a model fails and to transparently interpret why. By integrating a nuanced array of signals for each category, our method enables a finer-grained assessment of the model's confidence. We present a simple yet highly effective approach based on the ordinal ranking of concept activation to the input image. Without bells and whistles, our method significantly reduce the false positive rate across diverse real-world image classification benchmarks, specifically by 3.7% on ImageNet and 9% on EuroSAT.
MaIR: A Locality- and Continuity-Preserving Mamba for Image Restoration
Dec 28, 2024



Recent advancements in Mamba have shown promising results in image restoration. These methods typically flatten 2D images into multiple distinct 1D sequences along rows and columns, process each sequence independently using selective scan operation, and recombine them to form the outputs. However, such a paradigm overlooks two vital aspects: i) the local relationships and spatial continuity inherent in natural images, and ii) the discrepancies among sequences unfolded through totally different ways. To overcome the drawbacks, we explore two problems in Mamba-based restoration methods: i) how to design a scanning strategy preserving both locality and continuity while facilitating restoration, and ii) how to aggregate the distinct sequences unfolded in totally different ways. To address these problems, we propose a novel Mamba-based Image Restoration model (MaIR), which consists of Nested S-shaped Scanning strategy (NSS) and Sequence Shuffle Attention block (SSA). Specifically, NSS preserves locality and continuity of the input images through the stripe-based scanning region and the S-shaped scanning path, respectively. SSA aggregates sequences through calculating attention weights within the corresponding channels of different sequences. Thanks to NSS and SSA, MaIR surpasses 40 baselines across 14 challenging datasets, achieving state-of-the-art performance on the tasks of image super-resolution, denoising, deblurring and dehazing. Our codes will be available after acceptance.
DiFiC: Your Diffusion Model Holds the Secret to Fine-Grained Clustering
Dec 25, 2024



Fine-grained clustering is a practical yet challenging task, whose essence lies in capturing the subtle differences between instances of different classes. Such subtle differences can be easily disrupted by data augmentation or be overwhelmed by redundant information in data, leading to significant performance degradation for existing clustering methods. In this work, we introduce DiFiC a fine-grained clustering method building upon the conditional diffusion model. Distinct from existing works that focus on extracting discriminative features from images, DiFiC resorts to deducing the textual conditions used for image generation. To distill more precise and clustering-favorable object semantics, DiFiC further regularizes the diffusion target and guides the distillation process utilizing neighborhood similarity. Extensive experiments demonstrate that DiFiC outperforms both state-of-the-art discriminative and generative clustering methods on four fine-grained image clustering benchmarks. We hope the success of DiFiC will inspire future research to unlock the potential of diffusion models in tasks beyond generation. The code will be released.
Beyond Accuracy: On the Effects of Fine-tuning Towards Vision-Language Model's Prediction Rationality
Dec 17, 2024



Vision-Language Models (VLMs), such as CLIP, have already seen widespread applications. Researchers actively engage in further fine-tuning VLMs in safety-critical domains. In these domains, prediction rationality is crucial: the prediction should be correct and based on valid evidence. Yet, for VLMs, the impact of fine-tuning on prediction rationality is seldomly investigated. To study this problem, we proposed two new metrics called Prediction Trustworthiness and Inference Reliability. We conducted extensive experiments on various settings and observed some interesting phenomena. On the one hand, we found that the well-adopted fine-tuning methods led to more correct predictions based on invalid evidence. This potentially undermines the trustworthiness of correct predictions from fine-tuned VLMs. On the other hand, having identified valid evidence of target objects, fine-tuned VLMs were more likely to make correct predictions. Moreover, the findings are also consistent under distributional shifts and across various experimental settings. We hope our research offer fresh insights to VLM fine-tuning.
Self-Supervised Conditional Distribution Learning on Graphs
Nov 20, 2024Graph contrastive learning (GCL) has shown promising performance in semisupervised graph classification. However, existing studies still encounter significant challenges in GCL. First, successive layers in graph neural network (GNN) tend to produce more similar node embeddings, while GCL aims to increase the dissimilarity between negative pairs of node embeddings. This inevitably results in a conflict between the message-passing mechanism of GNNs and the contrastive learning of negative pairs via intraviews. Second, leveraging the diversity and quantity of data provided by graph-structured data augmentations while preserving intrinsic semantic information is challenging. In this paper, we propose a self-supervised conditional distribution learning (SSCDL) method designed to learn graph representations from graph-structured data for semisupervised graph classification. Specifically, we present an end-to-end graph representation learning model to align the conditional distributions of weakly and strongly augmented features over the original features. This alignment effectively reduces the risk of disrupting intrinsic semantic information through graph-structured data augmentation. To avoid conflict between the message-passing mechanism and contrastive learning of negative pairs, positive pairs of node representations are retained for measuring the similarity between the original features and the corresponding weakly augmented features. Extensive experiments with several benchmark graph datasets demonstrate the effectiveness of the proposed SSCDL method.
Beyond Accuracy: Ensuring Correct Predictions With Correct Rationales
Oct 31, 2024



Large pretrained foundation models demonstrate exceptional performance and, in some high-stakes applications, even surpass human experts. However, most of these models are currently evaluated primarily on prediction accuracy, overlooking the validity of the rationales behind their accurate predictions. For the safe deployment of foundation models, there is a pressing need to ensure double-correct predictions, i.e., correct prediction backed by correct rationales. To achieve this, we propose a two-phase scheme: First, we curate a new dataset that offers structured rationales for visual recognition tasks. Second, we propose a rationale-informed optimization method to guide the model in disentangling and localizing visual evidence for each rationale, without requiring manual annotations. Extensive experiments and ablation studies demonstrate that our model outperforms state-of-the-art models by up to 10.1% in prediction accuracy across a wide range of tasks. Furthermore, our method significantly improves the model's rationale correctness, improving localization by 7.5% and disentanglement by 36.5%. Our dataset, source code, and pretrained weights: https://github.com/deep-real/DCP