 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Multi-view Clustering against Imperfect Information
Jun 03, 2026Real-world multi-view data always suffer from imperfect information problem, where the view-specific observations are absent (i.e., Incomplete Views, IV) and cross-view correspondences are mismatched (i.e., Noisy Correspondences, NC) for certain instances. As a remedy, numerous IV- and NC-oriented multi-view clustering (MvC) methods have been proposed, which however require either reliable correspondences or sufficiently complete instances, thus stopping short of addressing the imperfect information problem. In contrast, we observe that both IV and NC challenges originate from the same issue of imperfect cross-view counterpart information, where the counterpart of an anchor instance in another view might be either unavailable or unreliable. Based on the observation, we propose a novel robust MvC framework, termed Posterior-guided Latent Counterpart Inference (PLCI), which could handle both IV and NC in a unified manner. Specifically, PLCI formulates the desired cross-view counterpart of each anchor instance as a latent variable, and integrates both instance-level reliability and prototype-level semantic transport to infer the posterior distribution of the latent counterpart. Extensive experiments on six widely-used multi-view datasets against 10 state-of-the-art MvC methods demonstrate the effectiveness of PLCI for tackling the imperfect information problem. The code will be released upon acceptance.
Reliable Thinking with Images
Feb 16, 2026As a multimodal extension of Chain-of-Thought (CoT), Thinking with Images (TWI) has recently emerged as a promising avenue to enhance the reasoning capability of Multi-modal Large Language Models (MLLMs), which generates interleaved CoT by incorporating visual cues into the textual reasoning process. However, the success of existing TWI methods heavily relies on the assumption that interleaved image-text CoTs are faultless, which is easily violated in real-world scenarios due to the complexity of multimodal understanding. In this paper, we reveal and study a highly-practical yet under-explored problem in TWI, termed Noisy Thinking (NT). Specifically, NT refers to the imperfect visual cues mining and answer reasoning process. As the saying goes, ``One mistake leads to another'', erroneous interleaved CoT would cause error accumulation, thus significantly degrading the performance of MLLMs. To solve the NT problem, we propose a novel method dubbed Reliable Thinking with Images (RTWI). In brief, RTWI estimates the reliability of visual cues and textual CoT in a unified text-centric manner and accordingly employs robust filtering and voting modules to prevent NT from contaminating the final answer. Extensive experiments on seven benchmarks verify the effectiveness of RTWI against NT.
ARK: A Dual-Axis Multimodal Retrieval Benchmark along Reasoning and Knowledge
Feb 10, 2026Existing multimodal retrieval benchmarks largely emphasize semantic matching on daily-life images and offer limited diagnostics of professional knowledge and complex reasoning. To address this gap, we introduce ARK, a benchmark designed to analyze multimodal retrieval from two complementary perspectives: (i) knowledge domains (five domains with 17 subtypes), which characterize the content and expertise retrieval relies on, and (ii) reasoning skills (six categories), which characterize the type of inference over multimodal evidence required to identify the correct candidate. Specifically, ARK evaluates retrieval with both unimodal and multimodal queries and candidates, covering 16 heterogeneous visual data types. To avoid shortcut matching during evaluation, most queries are paired with targeted hard negatives that require multi-step reasoning. We evaluate 23 representative text-based and multimodal retrievers on ARK and observe a pronounced gap between knowledge-intensive and reasoning-intensive retrieval, with fine-grained visual and spatial reasoning emerging as persistent bottlenecks. We further show that simple enhancements such as re-ranking and rewriting yield consistent improvements, but substantial headroom remains.
Toward Robust and Harmonious Adaptation for Cross-modal Retrieval
Nov 18, 2025



Recently, the general-to-customized paradigm has emerged as the dominant approach for Cross-Modal Retrieval (CMR), which reconciles the distribution shift problem between the source domain and the target domain. However, existing general-to-customized CMR methods typically assume that the entire target-domain data is available, which is easily violated in real-world scenarios and thus inevitably suffer from the query shift (QS) problem. Specifically, query shift embraces the following two characteristics and thus poses new challenges to CMR. i) Online Shift: real-world queries always arrive in an online manner, rendering it impractical to access the entire query set beforehand for customization approaches; ii) Diverse Shift: even with domain customization, the CMR models struggle to satisfy queries from diverse users or scenarios, leaving an urgent need to accommodate diverse queries. In this paper, we observe that QS would not only undermine the well-structured common space inherited from the source model, but also steer the model toward forgetting the indispensable general knowledge for CMR. Inspired by the observations, we propose a novel method for achieving online and harmonious adaptation against QS, dubbed Robust adaptation with quEry ShifT (REST). To deal with online shift, REST first refines the retrieval results to formulate the query predictions and accordingly designs a QS-robust objective function on these predictions to preserve the well-established common space in an online manner. As for tackling the more challenging diverse shift, REST employs a gradient decoupling module to dexterously manipulate the gradients during the adaptation process, thus preventing the CMR model from forgetting the general knowledge. Extensive experiments on 20 benchmarks across three CMR tasks verify the effectiveness of our method against QS.
LLaVA-ReID: Selective Multi-image Questioner for Interactive Person Re-Identification
Apr 15, 2025

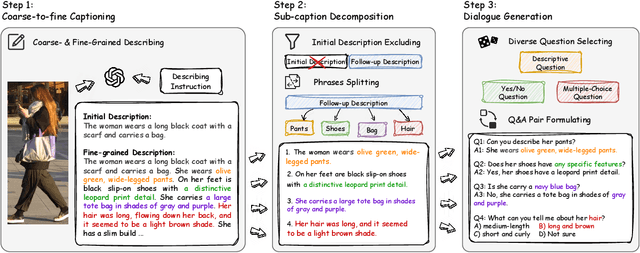

Traditional text-based person ReID assumes that person descriptions from witnesses are complete and provided at once. However, in real-world scenarios, such descriptions are often partial or vague. To address this limitation, we introduce a new task called interactive person re-identification (Inter-ReID). Inter-ReID is a dialogue-based retrieval task that iteratively refines initial descriptions through ongoing interactions with the witnesses. To facilitate the study of this new task, we construct a dialogue dataset that incorporates multiple types of questions by decomposing fine-grained attributes of individuals. We further propose LLaVA-ReID, a question model that generates targeted questions based on visual and textual contexts to elicit additional details about the target person. Leveraging a looking-forward strategy, we prioritize the most informative questions as supervision during training. Experimental results on both Inter-ReID and text-based ReID benchmarks demonstrate that LLaVA-ReID significantly outperforms baselines.
Learning Locally, Revising Globally: Global Reviser for Federated Learning with Noisy Labels
Nov 30, 2024



The success of most federated learning (FL) methods heavily depends on label quality, which is often inaccessible in real-world scenarios, such as medicine, leading to the federated label-noise (F-LN) problem. In this study, we observe that the global model of FL memorizes the noisy labels slowly. Based on the observations, we propose a novel approach dubbed Global Reviser for Federated Learning with Noisy Labels (FedGR) to enhance the label-noise robustness of FL. In brief, FedGR employs three novel modules to achieve noisy label sniffing and refining, local knowledge revising, and local model regularization. Specifically, the global model is adopted to infer local data proxies for global sample selection and refine incorrect labels. To maximize the utilization of local knowledge, we leverage the global model to revise the local exponential moving average (EMA) model of each client and distill it into the clients' models. Additionally, we introduce a global-to-local representation regularization to mitigate the overfitting of noisy labels. Extensive experiments on three F-LNL benchmarks against seven baseline methods demonstrate the effectiveness of the proposed FedGR.
Test-time Adaptation for Cross-modal Retrieval with Query Shift
Oct 21, 2024



The success of most existing cross-modal retrieval methods heavily relies on the assumption that the given queries follow the same distribution of the source domain. However, such an assumption is easily violated in real-world scenarios due to the complexity and diversity of queries, thus leading to the query shift problem. Specifically, query shift refers to the online query stream originating from the domain that follows a different distribution with the source one. In this paper, we observe that query shift would not only diminish the uniformity (namely, within-modality scatter) of the query modality but also amplify the gap between query and gallery modalities. Based on the observations, we propose a novel method dubbed Test-time adaptation for Cross-modal Retrieval (TCR). In brief, TCR employs a novel module to refine the query predictions (namely, retrieval results of the query) and a joint objective to prevent query shift from disturbing the common space, thus achieving online adaptation for the cross-modal retrieval models with query shift. Expensive experiments demonstrate the effectiveness of the proposed TCR against query shift. The code will be released upon acceptance.
An Empirical Study of Parameter Efficient Fine-tuning on Vision-Language Pre-train Model
Mar 13, 2024Recent studies applied Parameter Efficient Fine-Tuning techniques (PEFTs) to efficiently narrow the performance gap between pre-training and downstream. There are two important factors for various PEFTs, namely, the accessible data size and fine-tunable parameter size. A natural expectation for PEFTs is that the performance of various PEFTs is positively related to the data size and fine-tunable parameter size. However, according to the evaluation of five PEFTs on two downstream vision-language (VL) tasks, we find that such an intuition holds only if the downstream data and task are not consistent with pre-training. For downstream fine-tuning consistent with pre-training, data size no longer affects the performance, while the influence of fine-tunable parameter size is not monotonous. We believe such an observation could guide the choice of training strategy for various PEFTs.
Decoupled Contrastive Multi-view Clustering with High-order Random Walks
Aug 22, 2023



In recent, some robust contrastive multi-view clustering (MvC) methods have been proposed, which construct data pairs from neighborhoods to alleviate the false negative issue, i.e., some intra-cluster samples are wrongly treated as negative pairs. Although promising performance has been achieved by these methods, the false negative issue is still far from addressed and the false positive issue emerges because all in- and out-of-neighborhood samples are simply treated as positive and negative, respectively. To address the issues, we propose a novel robust method, dubbed decoupled contrastive multi-view clustering with high-order random walks (DIVIDE). In brief, DIVIDE leverages random walks to progressively identify data pairs in a global instead of local manner. As a result, DIVIDE could identify in-neighborhood negatives and out-of-neighborhood positives. Moreover, DIVIDE embraces a novel MvC architecture to perform inter- and intra-view contrastive learning in different embedding spaces, thus boosting clustering performance and embracing the robustness against missing views. To verify the efficacy of DIVIDE, we carry out extensive experiments on four benchmark datasets comparing with nine state-of-the-art MvC methods in both complete and incomplete MvC settings.
Semantic Invariant Multi-view Clustering with Fully Incomplete Information
May 22, 2023



Robust multi-view learning with incomplete information has received significant attention due to issues such as incomplete correspondences and incomplete instances that commonly affect real-world multi-view applications. Existing approaches heavily rely on paired samples to realign or impute defective ones, but such preconditions cannot always be satisfied in practice due to the complexity of data collection and transmission. To address this problem, we present a novel framework called SeMantic Invariance LEarning (SMILE) for multi-view clustering with incomplete information that does not require any paired samples. To be specific, we discover the existence of invariant semantic distribution across different views, which enables SMILE to alleviate the cross-view discrepancy to learn consensus semantics without requiring any paired samples. The resulting consensus semantics remains unaffected by cross-view distribution shifts, making them useful for realigning/imputing defective instances and forming clusters. We demonstrate the effectiveness of SMILE through extensive comparison experiments with 13 state-of-the-art baselines on five benchmarks. Our approach improves the clustering accuracy of NoisyMNIST from 19.3\%/23.2\% to 82.7\%/69.0\% when the correspondences/instances are fully incomplete. We will release the code after acceptance.