 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXi Chen
Autoregressive Uncertainty Modeling for 3D Bounding Box Prediction
Oct 13, 2022

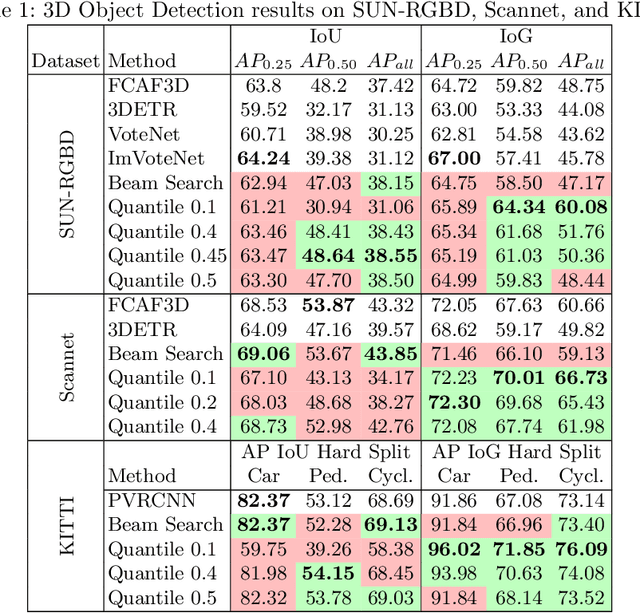
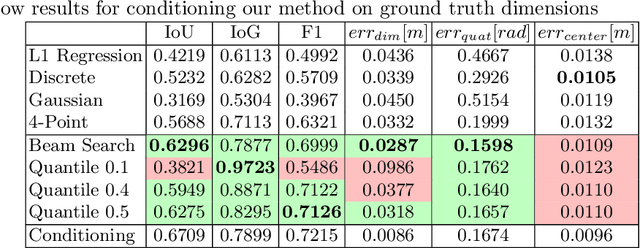
3D bounding boxes are a widespread intermediate representation in many computer vision applications. However, predicting them is a challenging task, largely due to partial observability, which motivates the need for a strong sense of uncertainty. While many recent methods have explored better architectures for consuming sparse and unstructured point cloud data, we hypothesize that there is room for improvement in the modeling of the output distribution and explore how this can be achieved using an autoregressive prediction head. Additionally, we release a simulated dataset, COB-3D, which highlights new types of ambiguity that arise in real-world robotics applications, where 3D bounding box prediction has largely been underexplored. We propose methods for leveraging our autoregressive model to make high confidence predictions and meaningful uncertainty measures, achieving strong results on SUN-RGBD, Scannet, KITTI, and our new dataset.
MuRAG: Multimodal Retrieval-Augmented Generator for Open Question Answering over Images and Text
Oct 06, 2022

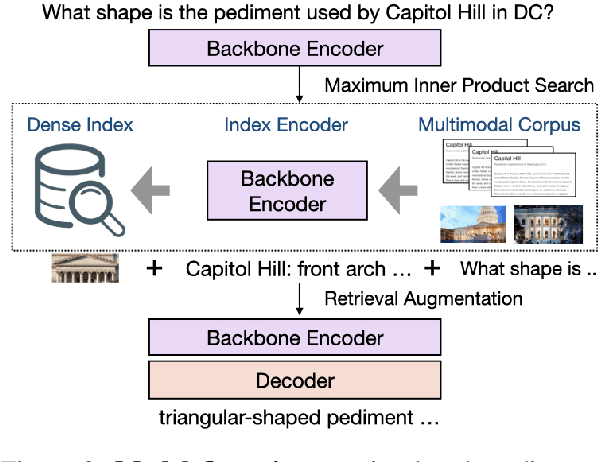
While language Models store a massive amount of world knowledge implicitly in their parameters, even very large models often fail to encode information about rare entities and events, while incurring huge computational costs. Recently, retrieval-augmented models, such as REALM, RAG, and RETRO, have incorporated world knowledge into language generation by leveraging an external non-parametric index and have demonstrated impressive performance with constrained model sizes. However, these methods are restricted to retrieving only textual knowledge, neglecting the ubiquitous amount of knowledge in other modalities like images -- much of which contains information not covered by any text. To address this limitation, we propose the first Multimodal Retrieval-Augmented Transformer (MuRAG), which accesses an external non-parametric multimodal memory to augment language generation. MuRAG is pre-trained with a mixture of large-scale image-text and text-only corpora using a joint contrastive and generative loss. We perform experiments on two different datasets that require retrieving and reasoning over both images and text to answer a given query: WebQA, and MultimodalQA. Our results show that MuRAG achieves state-of-the-art accuracy, outperforming existing models by 10-20\% absolute on both datasets and under both distractor and full-wiki settings.
PaLI: A Jointly-Scaled Multilingual Language-Image Model
Sep 16, 2022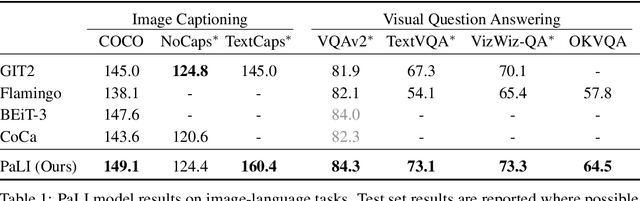

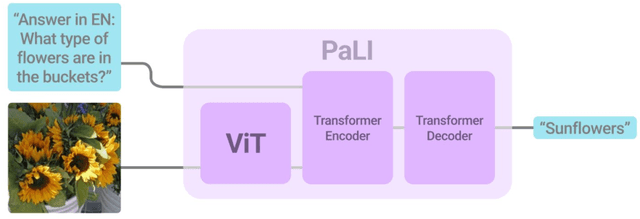

Effective scaling and a flexible task interface enable large language models to excel at many tasks. PaLI (Pathways Language and Image model) extends this approach to the joint modeling of language and vision. PaLI generates text based on visual and textual inputs, and with this interface performs many vision, language, and multimodal tasks, in many languages. To train PaLI, we make use of large pretrained encoder-decoder language models and Vision Transformers (ViTs). This allows us to capitalize on their existing capabilities and leverage the substantial cost of training them. We find that joint scaling of the vision and language components is important. Since existing Transformers for language are much larger than their vision counterparts, we train the largest ViT to date (ViT-e) to quantify the benefits from even larger-capacity vision models. To train PaLI, we create a large multilingual mix of pretraining tasks, based on a new image-text training set containing 10B images and texts in over 100 languages. PaLI achieves state-of-the-art in multiple vision and language tasks (such as captioning, visual question-answering, scene-text understanding), while retaining a simple, modular, and scalable design.
PreSTU: Pre-Training for Scene-Text Understanding
Sep 12, 2022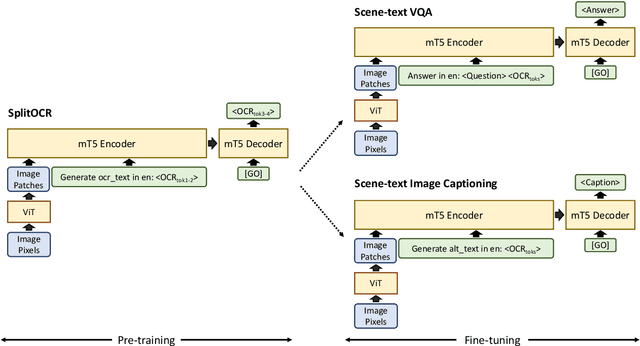
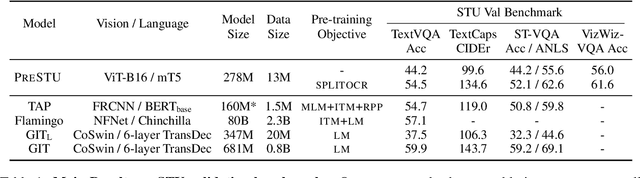
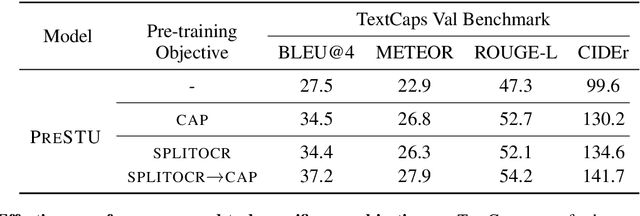
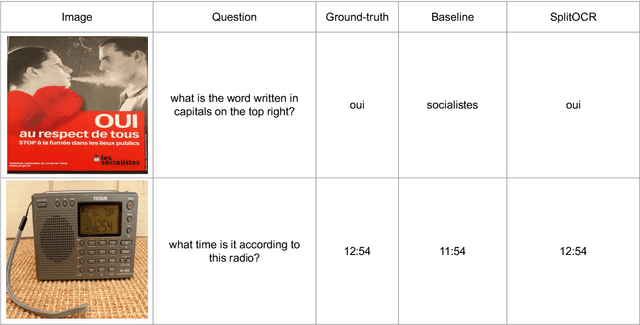
The ability to read and reason about texts in an image is often lacking in vision-and-language (V&L) models. How can we learn V&L models that exhibit strong scene-text understanding (STU)? In this paper, we propose PreSTU, a simple pre-training recipe specifically designed for scene-text understanding. PreSTU combines a simple OCR-aware pre-training objective with a large-scale image-text dataset with off-the-shelf OCR signals. We empirically demonstrate the superiority of this pre-training objective on TextVQA, TextCaps, ST-VQA, and VizWiz-VQA. We also study which factors affect STU performance, where we highlight the importance of image resolution and dataset scale during pre-training.
Towards Multi-Lingual Visual Question Answering
Sep 12, 2022

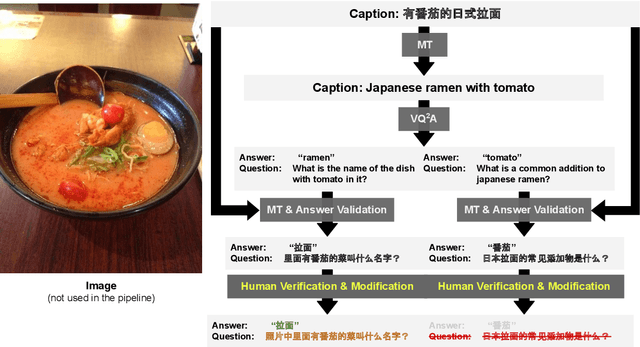
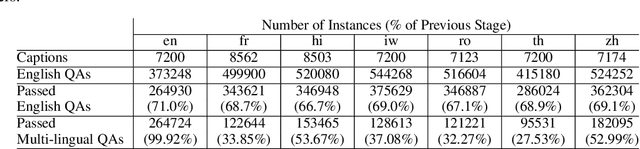
Visual Question Answering (VQA) has been primarily studied through the lens of the English language. Yet, tackling VQA in other languages in the same manner would require considerable amount of resources. In this paper, we propose scalable solutions to multi-lingual visual question answering (mVQA), on both data and modeling fronts. We first propose a translation-based framework to mVQA data generation that requires much less human annotation efforts than the conventional approach of directly collection questions and answers. Then, we apply our framework to the multi-lingual captions in the Crossmodal-3600 dataset and develop an efficient annotation protocol to create MAVERICS-XM3600 (MaXM), a test-only VQA benchmark in 7 diverse languages. Finally, we propose an approach to unified, extensible, open-ended, and end-to-end mVQA modeling and demonstrate strong performance in 13 languages.
Deep Baseline Network for Time Series Modeling and Anomaly Detection
Sep 10, 2022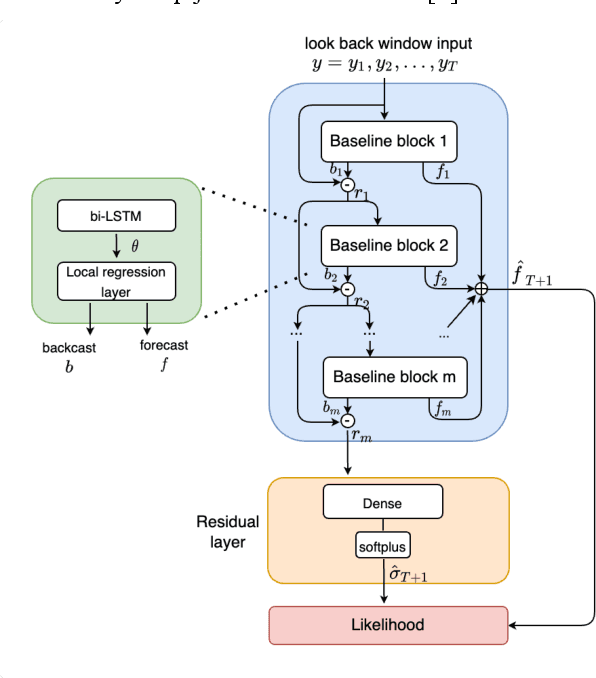
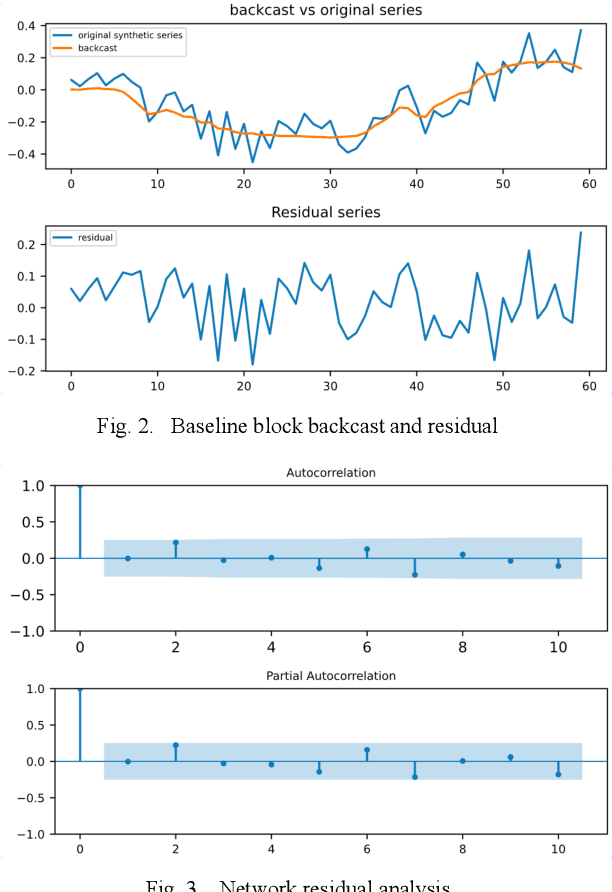
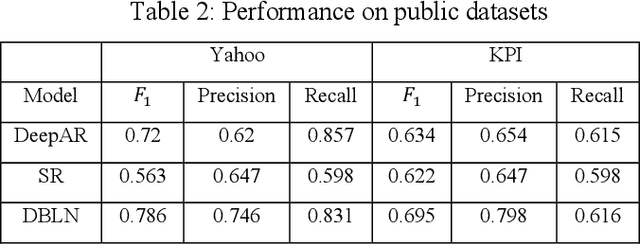

Deep learning has seen increasing applications in time series in recent years. For time series anomaly detection scenarios, such as in finance, Internet of Things, data center operations, etc., time series usually show very flexible baselines depending on various external factors. Anomalies unveil themselves by lying far away from the baseline. However, the detection is not always easy due to some challenges including baseline shifting, lacking of labels, noise interference, real time detection in streaming data, result interpretability, etc. In this paper, we develop a novel deep architecture to properly extract the baseline from time series, namely Deep Baseline Network (DBLN). By using this deep network, we can easily locate the baseline position and then provide reliable and interpretable anomaly detection result. Empirical evaluation on both synthetic and public real-world datasets shows that our purely unsupervised algorithm achieves superior performance compared with state-of-art methods and has good practical applications.
Majority Vote for Distributed Differentially Private Sign Selection
Sep 08, 2022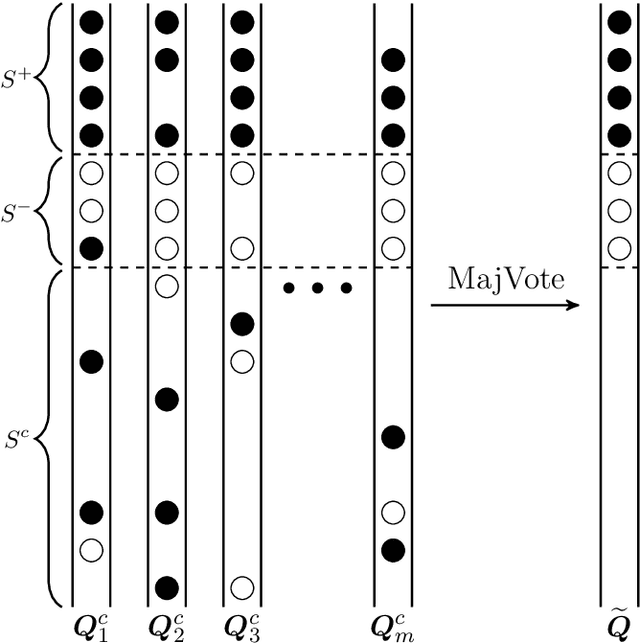
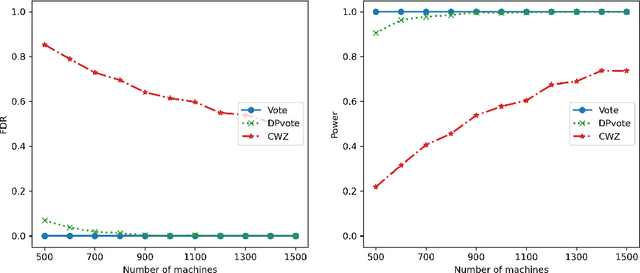
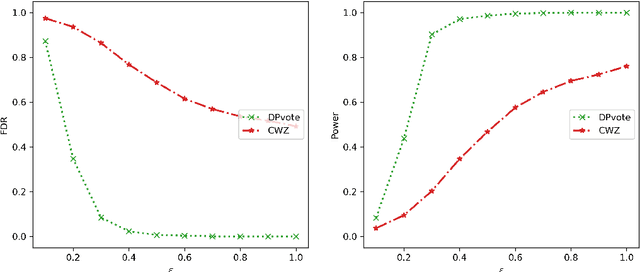
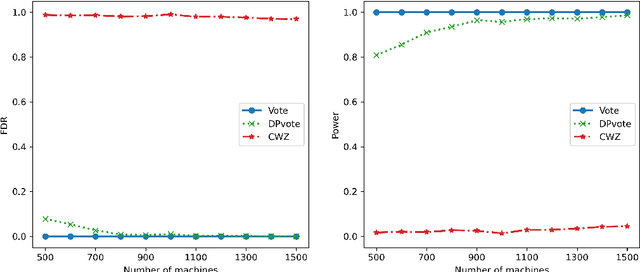
Privacy-preserving data analysis has become prevailing in recent years. In this paper, we propose a distributed group differentially private majority vote mechanism for the sign selection problem in a distributed setup. To achieve this, we apply the iterative peeling to the stability function and use the exponential mechanism to recover the signs. As applications, we study the private sign selection for mean estimation and linear regression problems in distributed systems. Our method recovers the support and signs with the optimal signal-to-noise ratio as in the non-private scenario, which is better than contemporary works of private variable selections. Moreover, the sign selection consistency is justified with theoretical guarantees. Simulation studies are conducted to demonstrate the effectiveness of our proposed method.
DP$^2$-VAE: Differentially Private Pre-trained Variational Autoencoders
Aug 05, 2022
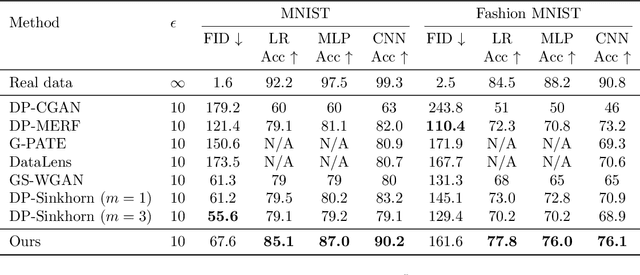

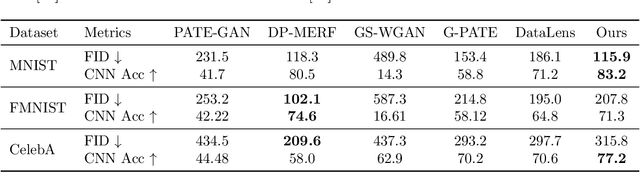
Modern machine learning systems achieve great success when trained on large datasets. However, these datasets usually contain sensitive information (e.g. medical records, face images), leading to serious privacy concerns. Differentially private generative models (DPGMs) emerge as a solution to circumvent such privacy concerns by generating privatized sensitive data. Similar to other differentially private (DP) learners, the major challenge for DPGM is also how to achieve a subtle balance between utility and privacy. We propose DP$^2$-VAE, a novel training mechanism for variational autoencoders (VAE) with provable DP guarantees and improved utility via \emph{pre-training on private data}. Under the same DP constraints, DP$^2$-VAE minimizes the perturbation noise during training, and hence improves utility. DP$^2$-VAE is very flexible and easily amenable to many other VAE variants. Theoretically, we study the effect of pretraining on private data. Empirically, we conduct extensive experiments on image datasets to illustrate our superiority over baselines under various privacy budgets and evaluation metrics.
Delta Hedging Liquidity Positions on Automated Market Makers
Aug 04, 2022
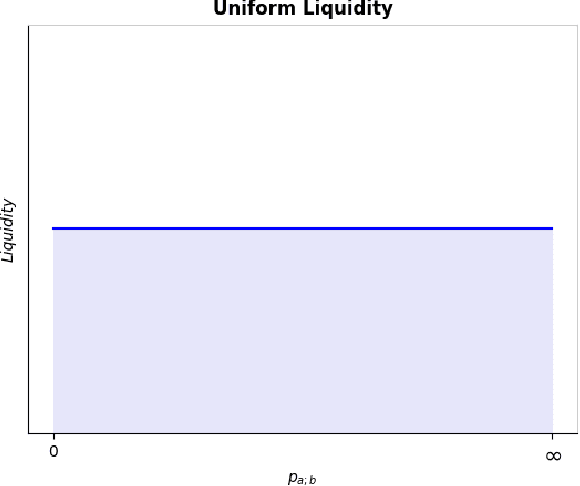
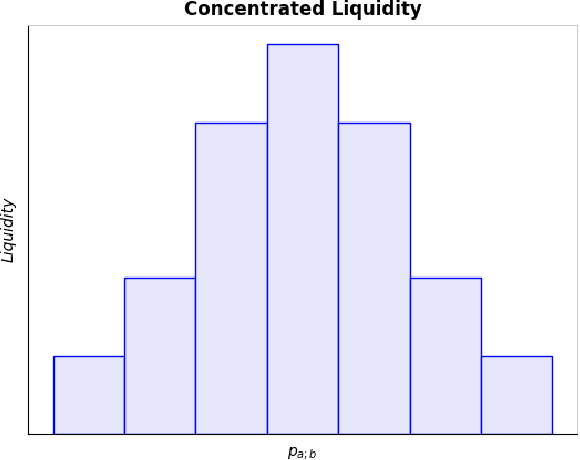
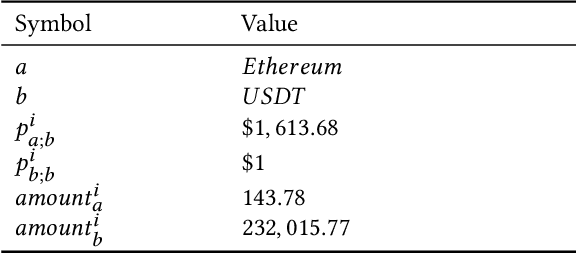
Liquidity Providers on Automated Market Makers generate millions of USD in transaction fees daily. However, the net value of a Liquidity Position is vulnerable to price changes in the underlying assets in the pool. The dominant measure of loss in a Liquidity Position is Impermanent Loss. Impermanent Loss for Constant Function Market Makers has been widely studied. We propose a new metric to measure Liquidity Position PNL based on price movement from the underlying assets. We show how this new metric more appropriately measures the change in the net value of a Liquidity Position as a function of price movement in the underlying assets. Our second contribution is an algorithm to delta hedge arbitrary Liquidity Positions on both uniform liquidity Automated Market Makers (such as Uniswap v2) and concentrated liquidity Automated Market Makers (such as Uniswap v3) via a combination of derivatives.
Gradient-based Bi-level Optimization for Deep Learning: A Survey
Aug 04, 2022
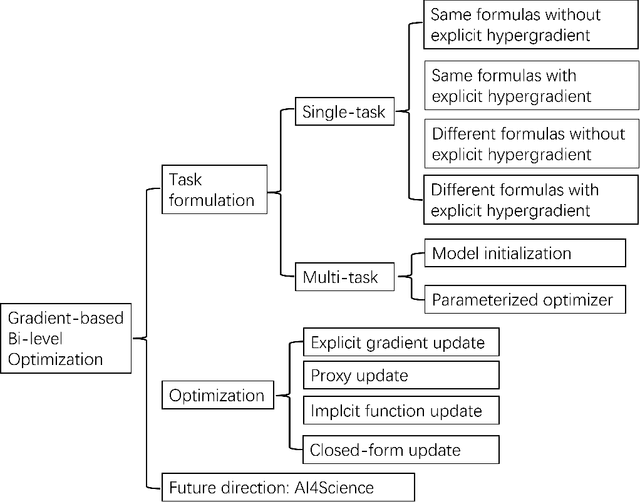
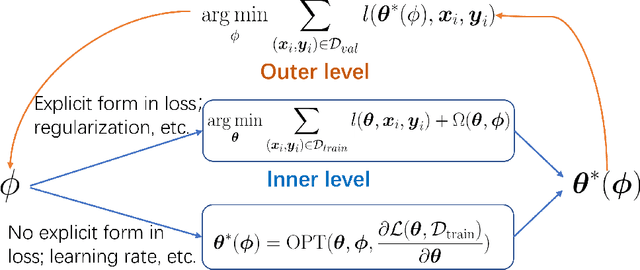
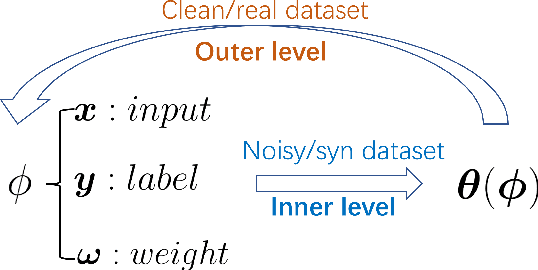
Bi-level optimization, especially the gradient-based category, has been widely used in the deep learning community including hyperparameter optimization and meta knowledge extraction. Bi-level optimization embeds one problem within another and the gradient-based category solves the outer level task by computing the hypergradient, which is much more efficient than classical methods such as the evolutionary algorithm. In this survey, we first give a formal definition of the gradient-based bi-level optimization. Secondly, we illustrate how to formulate a research problem as a bi-level optimization problem, which is of great practical use for beginners. More specifically, there are two formulations: the single-task formulation to optimize hyperparameters such as regularization parameters and the distilled data, and the multi-task formulation to extract meta knowledge such as the model initialization. With a bi-level formulation, we then discuss four bi-level optimization solvers to update the outer variable including explicit gradient update, proxy update, implicit function update, and closed-form update. Last but not least, we conclude the survey by pointing out the great potential of gradient-based bi-level optimization on science problems (AI4Science).