 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniTabBench: Mapping the Empirical Frontiers of GBDTs, Neural Networks, and Foundation Models for Tabular Data at Scale
Apr 08, 2026While traditional tree-based ensemble methods have long dominated tabular tasks, deep neural networks and emerging foundation models have challenged this primacy, yet no consensus exists on a universally superior paradigm. Existing benchmarks typically contain fewer than 100 datasets, raising concerns about evaluation sufficiency and potential selection biases. To address these limitations, we introduce OmniTabBench, the largest tabular benchmark to date, comprising 3030 datasets spanning diverse tasks that are comprehensively collected from diverse sources and categorized by industry using large language models. We conduct an unprecedented large-scale empirical evaluation of state-of-the-art models from all model families on OmniTabBench, confirming the absence of a dominant winner. Furthermore, through a decoupled metafeature analysis, which examines individual properties such as dataset size, feature types, feature and target skewness/kurtosis, we elucidate conditions favoring specific model categories, providing clearer, more actionable guidance than prior compound-metric studies.
DP$^2$-VAE: Differentially Private Pre-trained Variational Autoencoders
Aug 05, 2022
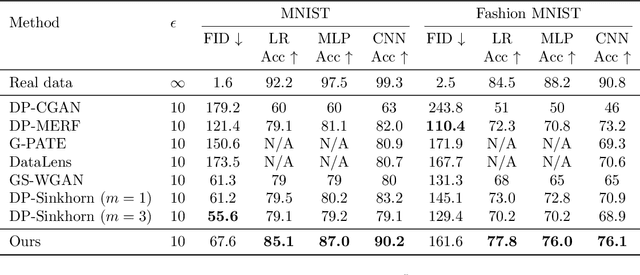

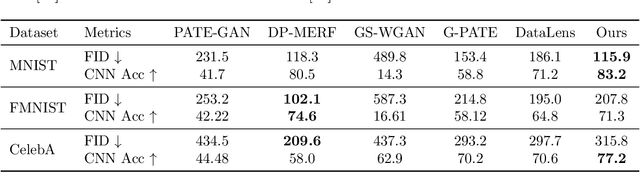
Modern machine learning systems achieve great success when trained on large datasets. However, these datasets usually contain sensitive information (e.g. medical records, face images), leading to serious privacy concerns. Differentially private generative models (DPGMs) emerge as a solution to circumvent such privacy concerns by generating privatized sensitive data. Similar to other differentially private (DP) learners, the major challenge for DPGM is also how to achieve a subtle balance between utility and privacy. We propose DP$^2$-VAE, a novel training mechanism for variational autoencoders (VAE) with provable DP guarantees and improved utility via \emph{pre-training on private data}. Under the same DP constraints, DP$^2$-VAE minimizes the perturbation noise during training, and hence improves utility. DP$^2$-VAE is very flexible and easily amenable to many other VAE variants. Theoretically, we study the effect of pretraining on private data. Empirically, we conduct extensive experiments on image datasets to illustrate our superiority over baselines under various privacy budgets and evaluation metrics.
Multi-Scale Supervised 3D U-Net for Kidneys and Kidney Tumor Segmentation
Apr 17, 2020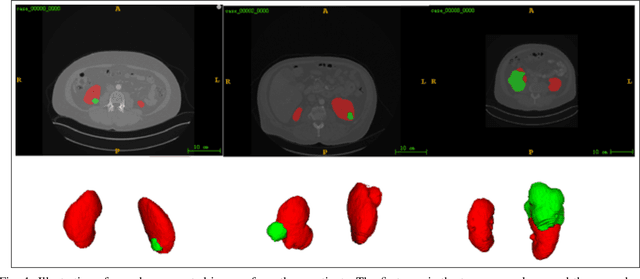
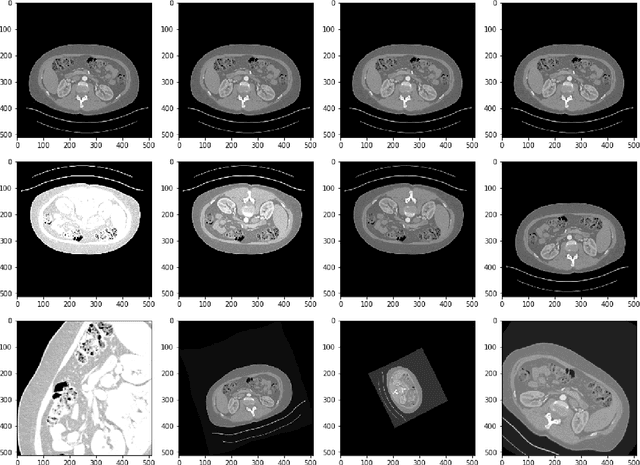
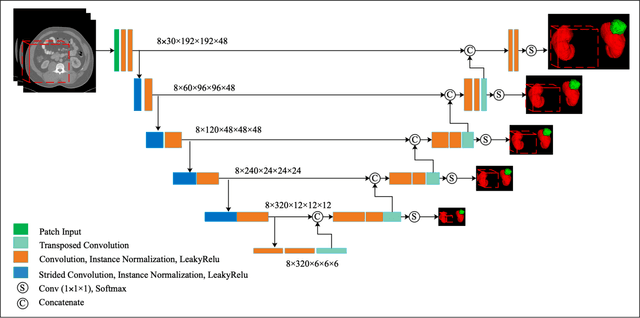
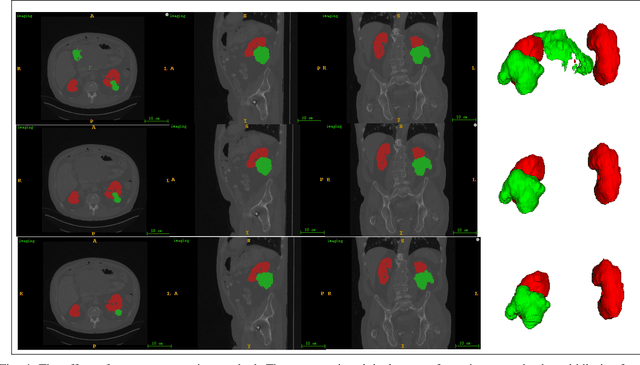
Accurate segmentation of kidneys and kidney tumors is an essential step for radiomic analysis as well as developing advanced surgical planning techniques. In clinical analysis, the segmentation is currently performed by clinicians from the visual inspection images gathered through a computed tomography (CT) scan. This process is laborious and its success significantly depends on previous experience. Moreover, the uncertainty in the tumor location and heterogeneity of scans across patients increases the error rate. To tackle this issue, computer-aided segmentation based on deep learning techniques have become increasingly popular. We present a multi-scale supervised 3D U-Net, MSS U-Net, to automatically segment kidneys and kidney tumors from CT images. Our architecture combines deep supervision with exponential logarithmic loss to increase the 3D U-Net training efficiency. Furthermore, we introduce a connected-component based post processing method to enhance the performance of the overall process. This architecture shows superior performance compared to state-of-the-art works using data from KiTS19 public dataset, with the Dice coefficient of kidney and tumor up to 0.969 and 0.805 respectively. The segmentation techniques introduced in this paper have been tested in the KiTS19 challenge with its corresponding dataset.