 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussianDreamer: Fast Generation from Text to 3D Gaussian Splatting with Point Cloud Priors
Oct 12, 2023In recent times, the generation of 3D assets from text prompts has shown impressive results. Both 2D and 3D diffusion models can generate decent 3D objects based on prompts. 3D diffusion models have good 3D consistency, but their quality and generalization are limited as trainable 3D data is expensive and hard to obtain. 2D diffusion models enjoy strong abilities of generalization and fine generation, but the 3D consistency is hard to guarantee. This paper attempts to bridge the power from the two types of diffusion models via the recent explicit and efficient 3D Gaussian splatting representation. A fast 3D generation framework, named as \name, is proposed, where the 3D diffusion model provides point cloud priors for initialization and the 2D diffusion model enriches the geometry and appearance. Operations of noisy point growing and color perturbation are introduced to enhance the initialized Gaussians. Our \name can generate a high-quality 3D instance within 25 minutes on one GPU, much faster than previous methods, while the generated instances can be directly rendered in real time. Demos and code are available at https://taoranyi.com/gaussiandreamer/.
4D Gaussian Splatting for Real-Time Dynamic Scene Rendering
Oct 12, 2023Representing and rendering dynamic scenes has been an important but challenging task. Especially, to accurately model complex motions, high efficiency is usually hard to maintain. We introduce the 4D Gaussian Splatting (4D-GS) to achieve real-time dynamic scene rendering while also enjoying high training and storage efficiency. An efficient deformation field is constructed to model both Gaussian motions and shape deformations. Different adjacent Gaussians are connected via a HexPlane to produce more accurate position and shape deformations. Our 4D-GS method achieves real-time rendering under high resolutions, 70 FPS at a 800$\times$800 resolution on an RTX 3090 GPU, while maintaining comparable or higher quality than previous state-of-the-art methods. More demos and code are available at https://guanjunwu.github.io/4dgs/.
TiAVox: Time-aware Attenuation Voxels for Sparse-view 4D DSA Reconstruction
Sep 05, 2023Four-dimensional Digital Subtraction Angiography (4D DSA) plays a critical role in the diagnosis of many medical diseases, such as Arteriovenous Malformations (AVM) and Arteriovenous Fistulas (AVF). Despite its significant application value, the reconstruction of 4D DSA demands numerous views to effectively model the intricate vessels and radiocontrast flow, thereby implying a significant radiation dose. To address this high radiation issue, we propose a Time-aware Attenuation Voxel (TiAVox) approach for sparse-view 4D DSA reconstruction, which paves the way for high-quality 4D imaging. Additionally, 2D and 3D DSA imaging results can be generated from the reconstructed 4D DSA images. TiAVox introduces 4D attenuation voxel grids, which reflect attenuation properties from both spatial and temporal dimensions. It is optimized by minimizing discrepancies between the rendered images and sparse 2D DSA images. Without any neural network involved, TiAVox enjoys specific physical interpretability. The parameters of each learnable voxel represent the attenuation coefficients. We validated the TiAVox approach on both clinical and simulated datasets, achieving a 31.23 Peak Signal-to-Noise Ratio (PSNR) for novel view synthesis using only 30 views on the clinically sourced dataset, whereas traditional Feldkamp-Davis-Kress methods required 133 views. Similarly, with merely 10 views from the synthetic dataset, TiAVox yielded a PSNR of 34.32 for novel view synthesis and 41.40 for 3D reconstruction. We also executed ablation studies to corroborate the essential components of TiAVox. The code will be publically available.
Condition-Adaptive Graph Convolution Learning for Skeleton-Based Gait Recognition
Aug 13, 2023



Graph convolutional networks have been widely applied in skeleton-based gait recognition. A key challenge in this task is to distinguish the individual walking styles of different subjects across various views. Existing state-of-the-art methods employ uniform convolutions to extract features from diverse sequences and ignore the effects of viewpoint changes. To overcome these limitations, we propose a condition-adaptive graph (CAG) convolution network that can dynamically adapt to the specific attributes of each skeleton sequence and the corresponding view angle. In contrast to using fixed weights for all joints and sequences, we introduce a joint-specific filter learning (JSFL) module in the CAG method, which produces sequence-adaptive filters at the joint level. The adaptive filters capture fine-grained patterns that are unique to each joint, enabling the extraction of diverse spatial-temporal information about body parts. Additionally, we design a view-adaptive topology learning (VATL) module that generates adaptive graph topologies. These graph topologies are used to correlate the joints adaptively according to the specific view conditions. Thus, CAG can simultaneously adjust to various walking styles and viewpoints. Experiments on the two most widely used datasets (i.e., CASIA-B and OU-MVLP) show that CAG surpasses all previous skeleton-based methods. Moreover, the recognition performance can be enhanced by simply combining CAG with appearance-based methods, demonstrating the ability of CAG to provide useful complementary information.The source code will be available at https://github.com/OliverHxh/CAG.
MapTRv2: An End-to-End Framework for Online Vectorized HD Map Construction
Aug 10, 2023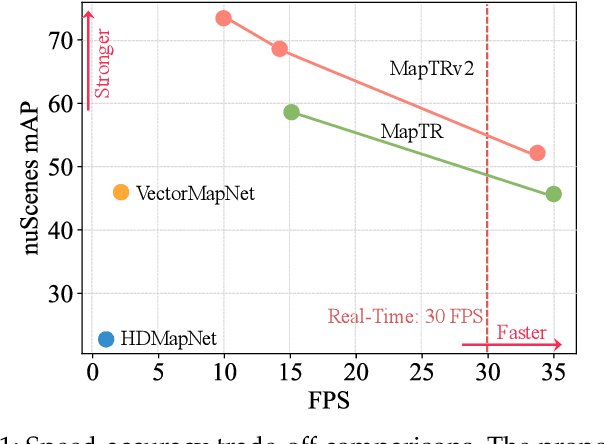
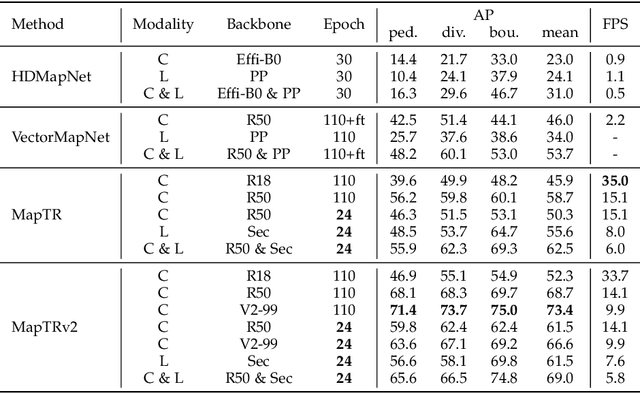
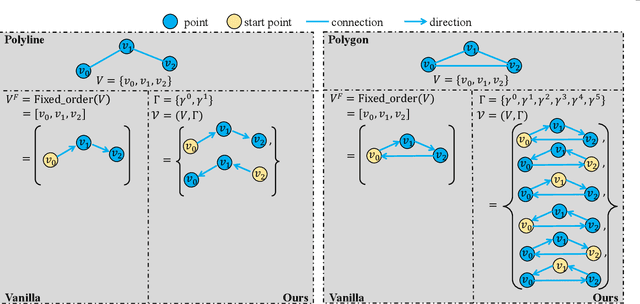
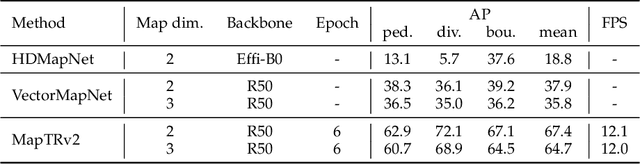
High-definition (HD) map provides abundant and precise static environmental information of the driving scene, serving as a fundamental and indispensable component for planning in autonomous driving system. In this paper, we present \textbf{Map} \textbf{TR}ansformer, an end-to-end framework for online vectorized HD map construction. We propose a unified permutation-equivalent modeling approach, \ie, modeling map element as a point set with a group of equivalent permutations, which accurately describes the shape of map element and stabilizes the learning process. We design a hierarchical query embedding scheme to flexibly encode structured map information and perform hierarchical bipartite matching for map element learning. To speed up convergence, we further introduce auxiliary one-to-many matching and dense supervision. The proposed method well copes with various map elements with arbitrary shapes. It runs at real-time inference speed and achieves state-of-the-art performance on both nuScenes and Argoverse2 datasets. Abundant qualitative results show stable and robust map construction quality in complex and various driving scenes. Code and more demos are available at \url{https://github.com/hustvl/MapTR} for facilitating further studies and applications.
Symphonize 3D Semantic Scene Completion with Contextual Instance Queries
Jun 27, 2023



3D Semantic Scene Completion (SSC) has emerged as a nascent and pivotal task for autonomous driving, as it involves predicting per-voxel occupancy within a 3D scene from partial LiDAR or image inputs. Existing methods primarily focus on the voxel-wise feature aggregation, while neglecting the instance-centric semantics and broader context. In this paper, we present a novel paradigm termed Symphonies (Scene-from-Insts) for SSC, which completes the scene volume from a sparse set of instance queries derived from the input with context awareness. By incorporating the queries as the instance feature representations within the scene, Symphonies dynamically encodes the instance-centric semantics to interact with the image and volume features while avoiding the dense voxel-wise modeling. Simultaneously, it orchestrates a more comprehensive understanding of the scenario by capturing context throughout the entire scene, contributing to alleviating the geometric ambiguity derived from occlusion and perspective errors. Symphonies achieves a state-of-the-art result of 13.02 mIoU on the challenging SemanticKITTI dataset, outperforming existing methods and showcasing the promising advancements of the paradigm. The code is available at \url{https://github.com/hustvl/Symphonies}.
SparseTrack: Multi-Object Tracking by Performing Scene Decomposition based on Pseudo-Depth
Jun 08, 2023Exploring robust and efficient association methods has always been an important issue in multiple-object tracking (MOT). Although existing tracking methods have achieved impressive performance, congestion and frequent occlusions still pose challenging problems in multi-object tracking. We reveal that performing sparse decomposition on dense scenes is a crucial step to enhance the performance of associating occluded targets. To this end, we propose a pseudo-depth estimation method for obtaining the relative depth of targets from 2D images. Secondly, we design a depth cascading matching (DCM) algorithm, which can use the obtained depth information to convert a dense target set into multiple sparse target subsets and perform data association on these sparse target subsets in order from near to far. By integrating the pseudo-depth method and the DCM strategy into the data association process, we propose a new tracker, called SparseTrack. SparseTrack provides a new perspective for solving the challenging crowded scene MOT problem. Only using IoU matching, SparseTrack achieves comparable performance with the state-of-the-art (SOTA) methods on the MOT17 and MOT20 benchmarks. Code and models are publicly available at \url{https://github.com/hustvl/SparseTrack}.
Matte Anything: Interactive Natural Image Matting with Segment Anything Models
Jun 07, 2023



Natural image matting algorithms aim to predict the transparency map (alpha-matte) with the trimap guidance. However, the production of trimaps often requires significant labor, which limits the widespread application of matting algorithms on a large scale. To address the issue, we propose Matte Anything model (MatAny), an interactive natural image matting model which could produce high-quality alpha-matte with various simple hints. The key insight of MatAny is to generate pseudo trimap automatically with contour and transparency prediction. We leverage task-specific vision models to enhance the performance of natural image matting. Specifically, we use the segment anything model (SAM) to predict high-quality contour with user interaction and an open-vocabulary (OV) detector to predict the transparency of any object. Subsequently, a pretrained image matting model generates alpha mattes with pseudo trimaps. MatAny is the interactive matting algorithm with the most supported interaction methods and the best performance to date. It consists of orthogonal vision models without any additional training. We evaluate the performance of MatAny against several current image matting algorithms, and the results demonstrate the significant potential of our approach.
GaitGS: Temporal Feature Learning in Granularity and Span Dimension for Gait Recognition
Jun 01, 2023



Gait recognition is an emerging biological recognition technology that identifies and verifies individuals based on their walking patterns. However, many current methods are limited in their use of temporal information. In order to fully harness the potential of gait recognition, it is crucial to consider temporal features at various granularities and spans. Hence, in this paper, we propose a novel framework named GaitGS, which aggregates temporal features in the granularity dimension and span dimension simultaneously. Specifically, Multi-Granularity Feature Extractor (MGFE) is proposed to focus on capturing the micro-motion and macro-motion information at the frame level and unit level respectively. Moreover, we present Multi-Span Feature Learning (MSFL) module to generate global and local temporal representations. On three popular gait datasets, extensive experiments demonstrate the state-of-the-art performance of our method. Our method achieves the Rank-1 accuracies of 92.9% (+0.5%), 52.0% (+1.4%), and 97.5% (+0.8%) on CASIA-B, GREW, and OU-MVLP respectively. The source code will be released soon.
A Range-Null Space Decomposition Approach for Fast and Flexible Spectral Compressive Imaging
May 16, 2023We present RND-SCI, a novel framework for compressive hyperspectral image (HSI) reconstruction. Our framework decomposes the reconstructed object into range-space and null-space components, where the range-space part ensures the solution conforms to the compression process, and the null-space term introduces a deep HSI prior to constraining the output to have satisfactory properties. RND-SCI is not only simple in design with strong interpretability but also can be easily adapted to various HSI reconstruction networks, improving the quality of HSIs with minimal computational overhead. RND-SCI significantly boosts the performance of HSI reconstruction networks in retraining, fine-tuning or plugging into a pre-trained off-the-shelf model. Based on the framework and SAUNet, we design an extremely fast HSI reconstruction network, RND-SAUNet, which achieves an astounding 91 frames per second while maintaining superior reconstruction accuracy compared to other less time-consuming methods. Code and models are available at https://github.com/hustvl/RND-SCI.